

什么是图片懒加载
当我们向下滚动的时候图片资源才被请求到,这也就是我们本次要实现的效果,进入页面的时候,只请求可视区域的图片资源这也就是懒加载。
比如我们加载一个页面,这个页面很长很长,长到我们的浏览器可视区域装不下,那么懒加载就是优先加载可视区域的内容,其他部分等进入了可视区域在加载。
这个功能非常常见,你打开淘宝的首页,向下滚动,就会看到会有图片不断的加载;你在百度中搜索图片,结果肯定成千上万条,不可能所有的都一下子加载出来的,很重要的原因就是会有性能问题。你可以在Network中查看,在页面滚动的时候,会看到图片一张张加载出来。
lazyLoad
为什么要做图片懒加载
懒加载是一种网页性能优化的方式,它能极大的提升用户体验。就比如说图片,图片一直是影响网页性能的主要元凶,现在一张图片超过几兆已经是很经常的事了。如果每次进入页面就请求所有的图片资源,那么可能等图片加载出来用户也早就走了。所以,我们需要懒加载,进入页面的时候,只请求可视区域的图片资源。
总结出来就两个点:
1.全部加载的话会影响用户体验
2.浪费用户的流量,有些用户并不像全部看完,全部加载会耗费大量流量。
懒加载原理
图片的标签是 img标签,图片的来源主要是 src属性,浏览器是否发起加载图片的请求是根据是否有src属性决定的。
所以可以从 img标签的 src属性入手,在没进到可视区域的时候,就先不给 img 标签的 src属性赋值。
懒加载实现
实现效果图:
imgLazyLoad
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<style>
div {
display: flex;
flex-direction: column;
}
img {
width: 100%;
height: 300px;
}
</style>
</head>
<body>
<div>
<img data-src="https://cdn.suisuijiang.com/ImageMessage/5adad39555703565e79040fa_1590657907683.jpeg">
<img data-src="https://cdn.suisuijiang.com/ImageMessage/5adad39555703565e79040fa_1590657913523.jpeg">
<img data-src="https://cdn.suisuijiang.com/ImageMessage/5adad39555703565e79040fa_1590657925550.jpeg">
<img data-src="https://cdn.suisuijiang.com/ImageMessage/5adad39555703565e79040fa_1590657930289.jpeg">
<img data-src="https://cdn.suisuijiang.com/ImageMessage/5adad39555703565e79040fa_1590657934750.jpeg">
<img data-src="https://cdn.suisuijiang.com/ImageMessage/5adad39555703565e79040fa_1590657918315.jpeg">
</div>
</body>
</html>
监听 scroll 事件判断元素是否进入视口
const imgs = [...document.getElementsByTagName('img')];
let n = 0;
lazyload();
function throttle(fn, wait) {
let timer = null;
return function(...args) {
if(!timer) {
timer = setTimeout(() => {
timer = null;
fn.apply(this, args)
}, wait)
}
}
}
function lazyload() {
var innerHeight = window.innerHeight;
var scrollTop = document.documentElement.scrollTop || document.body.scrollTop;
for(let i = n; i < imgs.length; i++) {
if(imgs[i].offsetTop < innerHeight + scrollTop) {
imgs[i].src = imgs[i].getAttribute("data-src");
n = i + 1;
}
}
}
window.addEventListener('scroll', throttle(lazyload, 200));
可能会存在下面几个问题:
每次滑动都要执行一次循环,如果有1000多个图片,性能会很差
每次读取 scrollTop 都会引起回流
scrollTop跟DOM的嵌套关系有关,应该根据getboundingclientrect获取
滑到最后的时候刷新,会看到所有的图片都加载了
IntersectionObserver
Intersection Observer API提供了一种异步观察目标元素与祖先元素或文档viewport的交集中的变化的方法。
创建一个 IntersectionObserver对象,并传入相应参数和回调用函数,该回调函数将会在目标(target)元素和根(root)元素的交集大小超过阈值(threshold)规定的大小时候被执行。
var observer = new IntersectionObserver(callback, options);
IntersectionObserver是浏览器原生提供的构造函数,接受两个参数:callback是可见性变化时的回调函数(即目标元素出现在root选项指定的元素中可见时,回调函数将会被执行),option是配置对象(该参数可选)。
返回的 observer是一个观察器实例。实例的 observe 方法可以指定观察哪个DOM节点。
具体的用法可以 查看 MDN文档
const imgs = [...document.getElementsByTagName('img')];
// 当监听的元素进入可视范围内的会触发回调
if(IntersectionObserver) {
// 创建一个 intersection observer
let lazyImageObserver = new IntersectionObserver((entries, observer) => {
entries.forEach((entry, index) => {
let lazyImage = entry.target;
// 相交率,默认是相对于浏览器视窗
if(entry.intersectionRatio > 0) {
lazyImage.src = lazyImage.getAttribute('data-src');
// 当前图片加载完之后需要去掉监听
lazyImageObserver.unobserve(lazyImage);
}
})
})
for(let i = 0; i < imgs.length; i++) {
lazyImageObserver.observe(imgs[i]);
}
}
源码地址-codePen点击预览
vue自定义指令-懒加载
Vue自定义指令
下面的api来自官网自定义指令:
钩子函数
bind: 只调用一次,指令第一次绑定到元素时调用。在这里可以进行一次性的初始化设置。
inserted: 被绑定元素插入父节点时调用 (仅保证父节点存在,但不一定已被插入文档中)。
update: 所在组件的 VNode 更新时调用,但是可能发生在其子 VNode 更新之前。指令的值可能发生了改变,也可能没有。但是你可以通过比较更新前后的值来忽略不必要的模板更新
componentUpdated: 指令所在组件的 VNode 及其子 VNode 全部更新后调用。
unbind: 只调用一次,指令与元素解绑时调用。
钩子函数参数
指令钩子函数会被传入以下参数:
el:指令所绑定的元素,可以用来直接操作 DOM。
binding:一个对象,包含以下 property:
name:指令名,不包括 v- 前缀。
value:指令的绑定值,例如:v-my-directive="1 + 1" 中,绑定值为 2。
oldValue:指令绑定的前一个值,仅在 update 和 componentUpdated 钩子中可用。无论值是否改变都可用。
expression:字符串形式的指令表达式。例如 v-my-directive="1 + 1" 中,表达式为 "1 + 1"。
arg:传给指令的参数,可选。例如 v-my-directive:foo 中,参数为 "foo"。
modifiers:一个包含修饰符的对象。例如:v-my-directive.foo.bar 中,修饰符对象为 { foo: true, bar: true }。
vnode:Vue 编译生成的虚拟节点。
oldVnode:上一个虚拟节点,仅在 update 和 componentUpdated 钩子中可用。
实现 v-lazyload 指令
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
<style>
img {
width: 100%;
height: 300px;
}
</style>
</head>
<body>
<div id="app">
<p v-for="item in imgs" :key="item">
<img v-lazyload="item">
</p>
</div>
</body>
<script src="https://cdn.jsdelivr.net/npm/vue"></script>
<script>
Vue.directive("lazyload", {
// 指令的定义
bind: function(el, binding) {
可视化是利用计算机图形学和图像处理技术,将数据转换成图形或图像在屏幕上显示出来,再进行交互处理的理论、方法和技术。面对医疗行业,如何将行业数据,转化为视觉可视化中的点线面,是在这个项目中需要思考的问题。
本文将带来设计师在医疗院感可视化项目中的设计过程及思考,讲述如何在业务场景下对数据进行抽取表达。通过可视化打破传统院感系统的表单呈现,使院感场景具备互动性、观赏性,满足不同角色的使用需求。同时院感医生通过可视化的解决方案能清晰直观的了解到院感发生分布、病例分析,从而控制院感发生和预防。
本项目以浙江省建德市第一人民医院为案例,地理数据以建德医院坐标为准。
项目背景
院感是什么?院感为医院感染,入院48小时内都有可能感染到院感细菌。在医院里有专门的院感医生职位,对医院感染进行有效的预防与控制。而传统院感管理的工作流:医护人员及院感医生 > 院感系统分析疑似病例 > 得出结论预防或治疗。这种偏人工的方式数据获取方式,无法更的获取院感发生的原因、定位、以及未来的院感预测。

P1 因此我们通过对医院数据的整理,抽离出影响院感的数据,将院感发生、发展、管控、治疗、预测全流程进行整合。

P2 通过医院>楼层>人员三个层面,空间和时间两个维度对院感展示。打破传统院感系统的表单呈现,使院感场景具备互动性、观赏性,满足不同角色的使用需求:如院长的展示性需求。院感医生通过可视化的解决方案能清晰直观的了解到院感发生分布、病例分析,从而控制院感发生和预防。

P3 同时在这样的设计场景下,可以覆盖的医疗业务场景和数据单位也会更多元,具有一定的商业化价值。

P4 设计流程
整个项目的设计流程可以分为4个阶段:信息收集、可视化、线上搭建、效果调试。在此项目实践中,重点投入在前三大部分。

P5 Part1信息收集
我们基于项目背景,梳理要展现的数据指标,对整体业务场景进行故事脚本的规划(即如何展现前期的数据收集,并把其串联在整体业务场景中),设定动作摄像机语言,同时也需要了解最终呈现的硬件设备与使用环境。

P6 Part2可视化
1.交互信息框架
首先梳理院感的信息框架和交互方式。

整个大屏分为院楼层,呈现整体院感数据的统计;楼层屏,作为重点病区的监测预测;个人屏,分析病例回溯病程,从而预测院感。三屏之间相互跳转, 交互演示方式从医院的外部跳转内部结构、再到患者的个人维度,三屏都分别展示相关的数据指标。
P7 2.视觉风格
在大屏视效风格探索上,期初的目标是希望可以打造不一样行业视觉语言,所以选择不同于以往的设计大屏风格,选择白色的风格,符合大家对医护行业的认知。但到中期发现,在硬件设备上展示发是过曝的。因此对设计风格进行调整改为X光片的风格,色系上偏冷绿的感觉。这是在这个项目中的试错经验之一。

P8 3.建模设计
在可视化部分中遇到的难点:建筑模型的高还原。下图为建德第一人民医院实拍图。在大屏项目中,必须真实还原地理位置。而在此医院没有清晰的CAD图纸提供的;在Google的卫星地图下也没有的建筑结构的,所以我在建模的过程中,是踩了坑的,先盲画了一版,但是精细度不够,过于粗糙。

P9 因此我反复看得到的资料,通过在确定地理氛围内,去丰富场景。这样的好处是使业务场景更加丰富,包括扩展到院外的车流数据,为业务场景提供更多可能性 当然后期也摇到了建筑内部的消防图,根据消防图绘制内部结构。

P10 4.数据面板
对可视化组件的组件进行设计:时间筛选、数据统计、占比关系、趋势分析。设计之前也参考了很多概念版的可视化设计,希望在院感屏上可以呈现一种科技概念的感觉。

P11 Part3线上搭建
1.获取地理数据
这部分是非常耗时的,datav是数据驱动的可视化产品,在搭建部分,是全程依靠datav平台的。
首先需要明确地理数据,通过高德数据通过点线成面,可以作为场景定位,也就是物理模型的经纬度数据 后面还原数据效果,造虚拟数据,是非常依赖于这个坐标数据的。
119.291724 , 29.472365
这是建德医院的坐标,医院在地图上的数据是很简化的,颗粒度很大,具体位置无法显示。
 P12 因此我们需要建立与地理数据绑定的建模,先对位置。
P12 因此我们需要建立与地理数据绑定的建模,先对位置。
 P13 在这个过程中我发现,如果最开始没有对准位置,也不用紧张,可以在DATAV平台增加hook数据过滤器,解决地理数据与世界坐标无法对齐的问题。
P13 在这个过程中我发现,如果最开始没有对准位置,也不用紧张,可以在DATAV平台增加hook数据过滤器,解决地理数据与世界坐标无法对齐的问题。
2.线上场景还原
根据对确定过位置模型进行烘焙还原。这个过程中遇到了一些不知名的原因烘焙失败,原因可能是命名有中文/位置数据错误/模型块面复杂等,遇到这样的问题就需要重新从头检查烘焙流程每一步。
 P14 3.数据维度展示还原
P14 3.数据维度展示还原
这一步我们需要把前期做好的数据可视化效果,还原到线上模型中。在这一步我遇到的问题是因建德医院内部具体结构的缺失,使一些可视化效果无法精准匹配到模型上。所以设计过程中只能依赖于在对的地理位置上丰富的场景内造数据,这个过程是比较吃力的。

P15 这个问题的解决办法是通过开发工具和导出的结构俯视图,对位置,然后转化出LEGO的数据

P16 在数据效果还原的过程中,也发现我在前期设计的数据效果,不能全部实现,有些是依赖于开发的 。这时可以通过其他组件效果代替尝试,比如热力的效果用粒子放大,通过参数调节得到热力 再比如局部房间的扫管,通过设计部分多次烘焙模型,不断叠加扫光层,得到房间监测的效果
 P17 设计小结
P17 设计小结
综合以上的经验,院感可视化从设计到落地,整体结构应该是这样从物理基础坐标的获取、到场景搭建、再到数据展示的过程。在这个过程中会用到DATAV、C4D、数据库、简单的代码等技术来实现。
 P18 这个项目虽然这只是医疗行业中一个小的业务场景,但我们的业务数据提取及可视化设计思路,他不仅限于医疗行业,同时也可以成为场馆类大屏解决方案的一部分,是具有一定商业化价值的。同时在这过程中沉淀下来的人体结构模型,和一些设计经验,是可以复用到对应行业解决方案中,达到提效。
P18 这个项目虽然这只是医疗行业中一个小的业务场景,但我们的业务数据提取及可视化设计思路,他不仅限于医疗行业,同时也可以成为场馆类大屏解决方案的一部分,是具有一定商业化价值的。同时在这过程中沉淀下来的人体结构模型,和一些设计经验,是可以复用到对应行业解决方案中,达到提效。
转自:
火车车次
/^[GCDZTSPKXLY1-9]\d{1,4}$/
手机机身码(IMEI)
/^\d{15,17}$/
必须带端口号的网址(或ip)
/^((ht|f)tps?:\/\/)?[\w-]+(\.[\w-]+)+:\d{1,5}\/?$/
网址(url,支持端口和"?+参数"和"#+参数)
/^(((ht|f)tps?):\/\/)?[\w-]+(\.[\w-]+)+([\w.,@?^=%&:\/~+#-]*[\w@?^=%&\/~+#-])?$/
统一社会信用代码
/^[0-9A-HJ-NPQRTUWXY]{2}\d{6}[0-9A-HJ-NPQRTUWXY]{10}$/
迅雷链接
/^thunderx?:\/\/[a-zA-Z\d]+=$/
ed2k链接(宽松匹配)
/^ed2k:\/\/\|file\|.+\|\/$/
磁力链接(宽松匹配)
/^magnet:\?xt=urn:btih:[0-9a-fA-F]{40,}.*$/
子网掩码
/^(?:\d{1,2}|1\d\d|2[0-4]\d|25[0-5])(?:\.(?:\d{1,2}|1\d\d|2[0-4]\d|25[0-5])){3}$/
linux"隐藏文件"路径
/^\/(?:[^\/]+\/)*\.[^\/]*/
linux文件夹路径
/^\/(?:[^\/]+\/)*$/
linux文件路径
/^\/(?:[^\/]+\/)*[^\/]+$/
window"文件夹"路径
/^[a-zA-Z]:\\(?:\w+\\?)*$/
window下"文件"路径
/^[a-zA-Z]:\\(?:\w+\\)*\w+\.\w+$/
股票代码(A股)
/^(s[hz]|S[HZ])(000[\d]{3}|002[\d]{3}|300[\d]{3}|600[\d]{3}|60[\d]{4})$/
大于等于0, 小于等于150, 支持小数位出现5, 如145.5, 用于判断考卷分数
/^150$|^(?:\d|[1-9]\d|1[0-4]\d)(?:.5)?$/
html注释
/^<!--[\s\S]*?-->$/
md5格式(32位)
/^([a-f\d]{32}|[A-F\d]{32})$/
版本号(version)格式必须为X.Y.Z
/^\d+(?:\.\d+){2}$/
视频(video)链接地址(视频格式可按需增删)
/^https?:\/\/(.+\/)+.+(\.(swf|avi|flv|mpg|rm|mov|wav|asf|3gp|mkv|rmvb|mp4))$/i
图片(image)链接地址(图片格式可按需增删)
/^https?:\/\/(.+\/)+.+(\.(gif|png|jpg|jpeg|webp|svg|psd|bmp|tif))$/i
24小时制时间(HH:mm:ss)
/^(?:[01]\d|2[0-3]):[0-5]\d:[0-5]\d$/
12小时制时间(hh:mm:ss)
/^(?:1[0-2]|0?[1-9]):[0-5]\d:[0-5]\d$/
base64格式
/^\s*data:(?:[a-z]+\/[a-z0-9-+.]+(?:;[a-z-]+=[a-z0-9-]+)?)?(?:;base64)?,([a-z0-9!$&',()*+;=\-._~:@\/?%\s]*?)\s*$/i
数字/货币金额(支持负数、千分位分隔符)
/^-?\d+(,\d{3})*(\.\d{1,2})?$/
数字/货币金额 (只支持正数、不支持校验千分位分隔符)
/(?:^[1-9]([0-9]+)?(?:\.[0-9]{1,2})?$)|(?:^(?:0){1}$)|(?:^[0-9]\.[0-9](?:[0-9])?$)/
银行卡号(10到30位, 覆盖对公/私账户, 参考微信支付)
/^[1-9]\d{9,29}$/
中文姓名
/^(?:[\u4e00-\u9fa5·]{2,16})$/
英文姓名
/(^[a-zA-Z]{1}[a-zA-Z\s]{0,20}[a-zA-Z]{1}$)/
车牌号(新能源)
/[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领 A-Z]{1}[A-HJ-NP-Z]{1}(([0-9]{5}[DF])|([DF][A-HJ-NP-Z0-9][0-9]{4}))$/
车牌号(非新能源)
/^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领 A-Z]{1}[A-HJ-NP-Z]{1}[A-Z0-9]{4}[A-Z0-9挂学警港澳]{1}$/
车牌号(新能源+非新能源)
/^(?:[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领 A-Z]{1}[A-HJ-NP-Z]{1}(?:(?:[0-9]{5}[DF])|(?:[DF](?:[A-HJ-NP-Z0-9])[0-9]{4})))|(?:[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领 A-Z]{1}[A-Z]{1}[A-HJ-NP-Z0-9]{4}[A-HJ-NP-Z0-9 挂学警港澳]{1})$/
手机号(mobile phone)中国(严谨), 根据工信部2019年公布的手机号段
/^(?:(?:\+|00)86)?1(?:(?:3[\d])|(?:4[5-7|9])|(?:5[0-3|5-9])|(?:6[5-7])|(?:7[0-8])|(?:8[\d])|(?:9[1|8|9]))\d{8}$/
手机号(mobile phone)中国(宽松), 只要是13,14,15,16,17,18,19开头即可
/^(?:(?:\+|00)86)?1[3-9]\d{9}$/
手机号(mobile phone)中国(最宽松), 只要是1开头即可, 如果你的手机号是用来接收短信, 优先建议选择这一条
/^(?:(?:\+|00)86)?1\d{10}$/
date(日期)
/^\d{4}(-)(1[0-2]|0?\d)\1([0-2]\d|\d|30|31)$/
email(邮箱)
/^[a-zA-Z0-9.!#$%&'*+\/=?^_`{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(?:\.[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*$/
座机(tel phone)电话(国内),如: 0341-86091234
/^\d{3}-\d{8}$|^\d{4}-\d{7}$/
身份证号(1代,15位数字)
/^[1-9]\d{7}(?:0\d|10|11|12)(?:0[1-9]|[1-2][\d]|30|31)\d{3}$/
身份证号(2代,18位数字),最后一位是校验位,可能为数字或字符X
/^[1-9]\d{5}(?:18|19|20)\d{2}(?:0\d|10|11|12)(?:0[1-9]|[1-2]\d|30|31)\d{3}[\dXx]$/
身份证号, 支持1/2代(15位/18位数字)
/(^\d{8}(0\d|10|11|12)([0-2]\d|30|31)\d{3}$)|(^\d{6}(18|19|20)\d{2}(0\d|10|11|12)([0-2]\d|30|31)\d{3}(\d|X|x)$)/
护照(包含香港、澳门)
/(^[EeKkGgDdSsPpHh]\d{8}$)|(^(([Ee][a-fA-F])|([DdSsPp][Ee])|([Kk][Jj])|([Mm][Aa])|(1[45]))\d{7}$)/
帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线组合
/^[a-zA-Z]\w{4,15}$/
中文/汉字
/^(?:[\u3400-\u4DB5\u4E00-\u9FEA\uFA0E\uFA0F\uFA11\uFA13\uFA14\uFA1F\uFA21\uFA23\uFA24\uFA27-\uFA29]|[\uD840-\uD868\uD86A-\uD86C\uD86F-\uD872\uD874-\uD879][\uDC00-\uDFFF]|\uD869[\uDC00-\uDED6\uDF00-\uDFFF]|\uD86D[\uDC00-\uDF34\uDF40-\uDFFF]|\uD86E[\uDC00-\uDC1D\uDC20-\uDFFF]|\uD873[\uDC00-\uDEA1\uDEB0-\uDFFF]|\uD87A[\uDC00-\uDFE0])+$/
小数
/^\d+\.\d+$/
数字
/^\d{1,}$/
html标签(宽松匹配)
/<(\w+)[^>]*>(.*?<\/\1>)?/
qq号格式正确
/^[1-9][0-9]{4,10}$/
数字和字母组成
/^[A-Za-z0-9]+$/
英文字母
/^[a-zA-Z]+$/
小写英文字母组成
/^[a-z]+$/
大写英文字母
/^[A-Z]+$/
密码强度校验,最少6位,包括至少1个大写字母,1个小写字母,1个数字,1个特殊字符
/^\S*(?=\S{6,})(?=\S*\d)(?=\S*[A-Z])(?=\S*[a-z])(?=\S*[!@#$%^&*? ])\S*$/
用户名校验,4到16位(字母,数字,下划线,减号)
/^[a-zA-Z0-9_-]{4,16}$/
ip-v4
/^(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$/
ip-v6
/^((([0-9A-Fa-f]{1,4}:){7}[0-9A-Fa-f]{1,4})|(([0-9A-Fa-f]{1,4}:){6}:[0-9A-Fa-f]{1,4})|(([0-9A-Fa-f]{1,4}:){5}:([0-9A-Fa-f]{1,4}:)?[0-9A-Fa-f]{1,4})|(([0-9A-Fa-f]{1,4}:){4}:([0-9A-Fa-f]{1,4}:){0,2}[0-9A-Fa-f]{1,4})|(([0-9A-Fa-f]{1,4}:){3}:([0-9A-Fa-f]{1,4}:){0,3}[0-9A-Fa-f]{1,4})|(([0-9A-Fa-f]{1,4}:){2}:([0-9A-Fa-f]{1,4}:){0,4}[0-9A-Fa-f]{1,4})|(([0-9A-Fa-f]{1,4}:){6}((\b((25[0-5])|(1\d{2})|(2[0-4]\d)|(\d{1,2}))\b)\.){3}(\b((25[0-5])|(1\d{2})|(2[0-4]\d)|(\d{1,2}))\b))|(([0-9A-Fa-f]{1,4}:){0,5}:((\b((25[0-5])|(1\d{2})|(2[0-4]\d)|(\d{1,2}))\b)\.){3}(\b((25[0-5])|(1\d{2})|(2[0-4]\d)|(\d{1,2}))\b))|(::([0-9A-Fa-f]{1,4}:){0,5}((\b((25[0-5])|(1\d{2})|(2[0-4]\d)|(\d{1,2}))\b)\.){3}(\b((25[0-5])|(1\d{2})|(2[0-4]\d)|(\d{1,2}))\b))|([0-9A-Fa-f]{1,4}::([0-9A-Fa-f]{1,4}:){0,5}[0-9A-Fa-f]{1,4})|(::([0-9A-Fa-f]{1,4}:){0,6}[0-9A-Fa-f]{1,4})|(([0-9A-Fa-f]{1,4}:){1,7}:))$/i
16进制颜色
/^#?([a-fA-F0-9]{6}|[a-fA-F0-9]{3})$/
微信号(wx),6至20位,以字母开头,字母,数字,减号,下划线
/^[a-zA-Z][-_a-zA-Z0-9]{5,19}$/
邮政编码(中国)
/^(0[1-7]|1[0-356]|2[0-7]|3[0-6]|4[0-7]|5[1-7]|6[1-7]|7[0-5]|8[013-6])\d{4}$/
中文和数字
/^((?:[\u3400-\u4DB5\u4E00-\u9FEA\uFA0E\uFA0F\uFA11\uFA13\uFA14\uFA1F\uFA21\uFA23\uFA24\uFA27-\uFA29]|[\uD840-\uD868\uD86A-\uD86C\uD86F-\uD872\uD874-\uD879][\uDC00-\uDFFF]|\uD869[\uDC00-\uDED6\uDF00-\uDFFF]|\uD86D[\uDC00-\uDF34\uDF40-\uDFFF]|\uD86E[\uDC00-\uDC1D\uDC20-\uDFFF]|\uD873[\uDC00-\uDEA1\uDEB0-\uDFFF]|\uD87A[\uDC00-\uDFE0])|(\d))+$/
不能包含字母
/^[^A-Za-z]*$/
java包名
/^([a-zA-Z_][a-zA-Z0-9_]*)+([.][a-zA-Z_][a-zA-Z0-9_]*)+$/
mac地址
/^((([a-f0-9]{2}:){5})|(([a-f0-9]{2}-){5}))[a-f0-9]{2}$/i
使用 vue-router 的导航守卫钩子函数,某些钩子函数可以让开发者根据业务逻辑,控制是否进行下一步,或者进入到指定的路由。
例如,后台管理页面,会在进入路由前,进行必要登录、权限判断,来决定去往哪个路由,以下是伪代码:
// 全局导航守卫
router.beforEach((to, from, next) => {
if('no login'){
next('/login')
}else if('admin') {
next('/admin')
}else {
next()
}
})
// 路由配置钩子函数
{
path: '',
component: component,
beforeEnter: (to, from, next) => {
next()
}
}
// 组件中配置钩子函数
{
template: '',
beforeRouteEnter(to, from, next) {
next()
}
}
调用 next,意味着继续进行下面的流程;不调用,则直接终止,导致路由中设置的组件无法渲染,会出现页面一片空白的现象。
钩子函数有不同的作用,例如 beforEach,afterEach,beforeEnter,beforeRouteEnter,beforeRouteUpdate,beforeRouteLeave,针对这些注册的钩子函数,要依次进行执行,并且在必要环节有控制权决定是否继续进入到下一个钩子函数中。
以下分析下源码中实现的方式,而源码中处理的边界情况比较多,需要抓住核心点,去掉冗余代码,精简出便于理解的实现。
精简源码核心功能
总结下核心点:钩子函数注册的回调函数,能顺序执行,同时会将控制权交给开发者。
先来一个能够注册回调函数的类:
class VueRouter {
constructor(){
this.beforeHooks = []
this.beforeEnterHooks = []
this.afterHooks = []
}
beforEach(callback){
return registerHook(this.beforeHooks, callback)
}
beforeEnter(callback){
return registerHook(this.beforeEnterHooks, callback)
}
afterEach(callback){
return registerHook(this.afterHooks, callback)
}
}
function registerHook (list, fn) {
list.push(fn)
return () => {
const i = list.indexOf(fn)
if (i > -1) list.splice(i, 1)
}
}
声明的类,提供了 beforEach 、beforeEnter 和 afterEach 来注册必要的回调函数。
抽象出一个 registerHook 公共方法,作用:
注册回调函数
返回的函数,可以取消注册的回调函数
使用一下:
const router = new VueRouter()
const beforEach = router.beforEach((to, from, next) => {
console.log('beforEach');
next()
})
// 取消注册的函数
beforEach()
以上的回调函数会被取消,意味着不会执行了。
router.beforEach((to, from, next) => {
console.log('beforEach');
next()
})
router.beforeEnter((to, from, next) => {
console.log('beforeEnter');
next()
})
router.afterEach(() => {
console.log('afterEach');
})
以上注册的钩子函数会依次执行。beforEach 和 beforeEnter 的回调接收内部传来的参数,同时通过调用 next 可继续走下面的回调函数,如果不调用,则直接被终止了。
最后一个 afterEach 在上面的回调函数都执行后,才被执行,且不接收任何参数。
先来实现依次执行,这是最简单的方式,在类中增加 run 方法,手动调用:
class VueRouter {
// ... 其他省略,增加 run 函数
run(){
// 把需要依次执行的回调存放在一个队列中
let queue = [].concat(
this.beforeHooks,
this.afterHooks
)
for(let i = 0; i < queue.length; i++){
if(queue(i)) {
queue(i)('to', 'from', () => {})
}
}
}
}
// 手动调用
router.run()
打印:
'beforEach'
'beforeEnter'
上面把要依次执行的回调函数聚合在一个队列中执行,并传入必要的参数,但这样开发者不能控制是否进行下一步,即便不执行 next 函数,依然会依次执行完队列的函数。
改进一下:
class VueRouter {
// ... 其他省略,增加 run 函数
run(){
// 把需要依次执行的回调存放在一个队列中
let queue = [].concat(
this.beforeHooks,
this.afterHooks
)
queue[0]('to', 'from', () => {
queue[1]('to', 'from', () => {
console.log('调用结束');
})
})
}
}
router.beforEach((to, from, next) => {
console.log('beforEach');
// next()
})
router.beforeEnter((to, from, next) => {
console.log('beforeEnter');
next()
})
传入的 next 函数会有调用下一个回调函数的行为,把控制权交给了开发者,调用了 next 函数会继续执行下一个回调函数;不调用 next 函数,则终止了队列的执行,所以打印结果是:
'beforEach'
上面实现有个弊端,代码不够灵活,手动一个个调用,在真实场景中无法确定注册了多少个回调函数,所以需要继续抽象成一个功能更强的方法:
function runQueue (queue, fn, cb) {
const step = index => {
// 队列执行结束了
if (index >= queue.length) {
cb()
} else {
// 队列有值
if (queue[index]) {
// 传入队列中回调,做一些必要的操作,第二个参数是为了进行下一个回调函数
fn(queue[index], () => {
step(index + 1)
})
} else {
step(index + 1)
}
}
}
// 初次调用,从第一个开始
step(0)
}
runQueue 就是执行队列的通用方法。
第一个参数为回调函数队列, 会依次取出来;
第二个参数是函数,它接受队列中的函数,进行一些其他处理;并能进行下个回调函数的执行;
第三个参数是队列执行结束后调用。
知道了这个函数的含义,来使用一下:
class VueRouter {
// ... 其他省略,增加 run 函数
run(){
// 把需要依次执行的回调存放在一个队列中
let queue = [].concat(
this.beforeHooks,
this.beforeEnterHooks
)
// 接收回到函数,和进行下一个的执行函数
const iterator = (hook, next) => {
// 传给回调函数的参数,第三个参数是函数,交给开发者调用,调用后进行下一个
hook('to', 'from', () => {
console.log('执行下一个回调时,处理一些相关信息');
next()
})
}
runQueue(queue, iterator, () => {
console.log('执行结束');
// 执行 afterEach 中的回调函数
this.afterHooks.forEach((fn) => {
fn()
})
})
}
}
// 注册
router.beforEach((to, from, next) => {
console.log('beforEach');
next()
})
router.beforeEnter((to, from, next) => {
console.log('beforeEnter');
next()
})
router.afterEach(() => {
console.log('afterEach');
})
router.run();
从上面代码可以看出来,每次把队列 queue 中的回调函数传给 iterator , 用 hook 接收,并调用。
传给 hook 必要的参数,尤其是第三个参数,开发者在注册的回调函数中调用,来控制进行下一步。
在队列执行完毕后,依次执行 afterHooks 的回调函数,不传入任何参数。
所以打印结果为:
beforEach
执行下一个回调时,处理一些相关信息
beforeEnter
执行下一个回调时,处理一些相关信息
执行结束
afterEach
以上实现的非常巧妙,再看 Vue-router 源码这块的实现方式,相信你会豁然开朗。
文章目录
小白学VUE——快速入门
前言:什么是VUE?
环境准备:
vue的js文件
vscode
Vue入门程序
抽取代码片段
vue标准语法:
什么是vue指令?
v-bind指令
事件单向绑定
v-model:事件双向绑定
v-on事件监听指令
v: on:submit.prevent指令
v-if 判断指令
v-for 循环渲染指令
Vue.js(读音 /vjuː/, 类似于 view) 是一套构建用户界面的渐进式框架。 Vue 只关注视图层, 采用自底向上增量开发的设计。 Vue 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件。

环境准备:
vue的js文件
使用CDN外部导入方法
以下推荐国外比较稳定的两个 CDN,把这些网址放进script标签的src属性下即可,国内还没发现哪一家比较好,目前还是建议下载到本地。
Staticfile CDN(国内) : https://cdn.staticfile.org/vue/2.2.2/vue.min.js
unpkg:https://unpkg.com/vue/dist/vue.js, 会保持和 npm 发布的的版本一致。
cdnjs : https://cdnjs.cloudflare.com/ajax/libs/vue/2.1.8/vue.min.js
2.VSCODE软件
(2).使用内部导入方法(自行下载js文件放进工作区js文件夹即可)

前往vscode官网下载对应版本的vscode

Vue入门程序
首先了解一下什么是插值
插值:数据绑定最常见的形式就是使用 **{{…}}(双大括号)**的文本插值:
单独抽出这段来看一下:
Vue即是vue内置的对象,el(element)指的是绑定的元素,可以用#id绑定元素,data指的是定义页面中显示的模型数据,还有未展示的methods,指的是方法
var app = new Vue({
el: "#app",//绑定VUE作用的范围
data: {//定义页面中显示的模型数据
message: 'hello vue'
}
});
代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
<script src="js/vue.min.js"></script>
</head>
<body>
<!-- 插值表达式 获取data里面定义的值 {{message}} -->
<div id="app">{{ message }}</div>
<script>
//创建一个VUE对象
var app = new Vue({
el: "#app",//绑定VUE作用的范围
data: {//定义页面中显示的模型数据
message: 'hello vue'
}
});
</script>
</body>
</html>
步骤:文件-首选项-用户片段
输入片段名称回车
{
"vh": {
"prefix": "vh", // 触发的关键字 输入vh按下tab键
"body": [
"<!DOCTYPE html>",
"<html lang=\"en\">",
"",
"<head>",
" <meta charset=\"UTF-8\">",
" <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">",
" <meta http-equiv=\"X-UA-Compatible\" content=\"ie=edge\">",
" <title>Document</title>",
" <script src=\"js/vue.min.js\"></script>",
"</head>",
"",
"<body>",
" <div id=\"app\"></div>",
" <script>",
" var vm=new Vue({",
" el:'#app',",
" data:{},",
" methods:{}",
" });",
" </script>",
"</body>",
"",
"</html>",
],
"description": "vh components"
}
}
此时,新建一个html文件,输入vh在按下tab键即可快速填充内容
vue标准语法:
什么是vue指令?
在vue中提供了一些对于页面 + 数据的更为方便的输出,这些操作就叫做指令, 以v-xxx表示
类似于html页面中的属性 `
比如在angular中 以ng-xxx开头的就叫做指令
在vue中 以v-xxx开头的就叫做指令
指令中封装了一些DOM行为, 结合属性作为一个暗号, 暗号有对应的值,根据不同的值,框架会进行相关DOM操作的绑定
下面简单介绍一下vue的几个基础指令: v-bind v-if v-for v-on等
v-bind指令
作用:
给元素的属性赋值
可以给已经存在的属性赋值 input value
也可以给自定义属性赋值 mydata
语法
在元素上 v-bind:属性名="常量||变量名"
简写形式 :属性名="变量名"
例:
<div v-bind:原属性名="变量"></div> <div :属性名="变量"></div>
事件单向绑定,可以用 v-bind:属性名="常量||变量名,绑定事件,用插值表达式取出值
<body>
效果:

————————————————
版权声明:本文为CSDN博主「热爱旅行的小李同学」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/m0_46275020/java/article/details/106055312
1. 访问内部属性
JavaScript 对象无法以常规方式访问的内部属性。内部属性名由双方括号[[]]包围,在创建对象时可用。
内部属性不能动态地添加到现有对象。
内部属性可以在某些内置 JavaScript 对象中使用,它们存储ECMAScript规范指定的内部状态。
有两种内部属性,一种操作对象的方法,另一种是存储数据的方法。例如:
[[Prototype]] — 对象的原型,可以为null或对象
[[Extensible]] — 表示是否允许在对象中动态添加新的属性
[[PrivateFieldValues]] — 用于管理私有类字段
2. 属性描述符对象
数据属性包含了一个数据值的位置,在这个位置可以读取和写入值。也就是说,数据属性可以通过 对象.属性 访问,就是我么平常接触的用户赋什么值,它们就返回什么,不会做额外的事情。
数据属性有4个描述其行为的特性(为了表示内部值,把属性放在两对方括号中),称为描述符对象。
属性 解释 默认值
[[Configurable]] 能否通过delete删除属性从而重新定义属性;
能否修改属性的特性;
能否把属性修改为访问器属性 true
[[Enumerable]] 能否通过for-in循环返回属性 true
[[Writable]] 能否修改属性的值 true
[[Value]] 包含这个属性的数据值 undefined
value 描述符是属性的数据值,例如,我们有以下对象 :
let foo = {
a: 1
}
那么,a 的value属性描述符为1。
writable是指该属性的值是否可以更改。 默认值为true,表示属性是可写的。 但是,我们可以通过多种方式将其设置为不可写。
configurable 的意思是可以删除对象的属性还是可以更改其属性描述符。 默认值为true,这意味着它是可配置的。
enumerable 意味着它可以被for ... in循环遍历。 默认值为true,说明能通过for-in循环返回属性
将属性键添加到返回的数组之前,Object.keys方法还检查enumerable 描述符。 但是,Reflect.ownKeys方法不会检查此属性描述符,而是返回所有自己的属性键。
Prototype描述符有其他方法,get和set分别用于获取和设置值。
在创建新对象, 我们可以使用Object.defineProperty方法设置的描述符,如下所示:
let foo = {
a: 1
}
Object.defineProperty(foo, 'b', {
value: 2,
writable: true,
enumerable: true,
configurable: true,
});
这样得到foo的新值是{a: 1, b: 2}。
我们还可以使用defineProperty更改现有属性的描述符。 例如:
let foo = {
a: 1
}
Object.defineProperty(foo, 'a', {
value: 2,
writable: false,
enumerable: true,
configurable: true,
});
这样当我们尝试给 foo.a 赋值时,如:
foo.a = 2;
如果关闭了严格模式,浏览器将忽略,否则将抛出一个错误,因为我们将 writable 设置为 false, 表示该属性不可写。
我们还可以使用defineProperty将属性转换为getter,如下所示:
'use strict'
let foo = {
a: 1
}
Object.defineProperty(foo, 'b', {
get() {
return 1;
}
})
当我们这样写的时候:
foo.b = 2;
因为b属性是getter属性,所以当使用严格模式时,我们会得到一个错误:Getter 属性不能重新赋值。
3.无法分配继承的只读属性
继承的只读属性不能再赋值。这是有道理的,因为我们这样设置它,它是继承的,所以它应该传播到继承属性的对象。
我们可以使用Object.create创建一个从原型对象继承属性的对象,如下所示:
const proto = Object.defineProperties({}, {
a: {
value: 1,
writable: false
}
})
const foo = Object.create(proto)
在上面的代码中,我们将proto.a的 writable 描述符设置为false,因此我们无法为其分配其他值。
如果我们这样写:
foo.a = 2;
在严格模式下,我们会收到错误消息。
总结
我们可以用 JavaScript 对象做很多我们可能不知道的事情。
首先,某些 JavaScript 对象(例如内置浏览器对象)具有内部属性,这些属性由双方括号包围,它们具有内部状态,对象创建无法动态添加。
JavaScript对象属性还具有属性描述符,该属性描述符使我们可以控制其值以及可以设置它们的值,还是可以更改其属性描述符等。
我们可以使用defineProperty更改属性的属性描述符,它还用于添加新属性及其属性描述符。
最后,继承的只读属性保持只读状态,这是有道理的,因为它是从父原型对象继承而来的。
web中开发的三个基本技术(html5,css3,JavaScript)
html简介:html语言是纯文本类型的语言,是internet上用来编写网页的主要语言,使用HTML语言编写的网页文件也是标准的纯文本文件(简单说告诉浏览器显示什么)
.
css简介:css是一种网页控制技术,采用css技术,可以有效地对页面、字体、颜色、背景和其他效果实现更加精准的控制
(简单的说告诉浏览器如何显示)
.
JavaScript:JavaScript是web页面中的一种脚本编程语言,也是一种通用的、跨平台的、基于对象和事件驱动并具有安全性的脚本语言。它不需要进行编译,而是直接嵌入HTML页面中,把静态页面变成动态页面。(简单的来说告诉浏览器如何交互)
简单HTML文件结构
<html>/*文件开始*/ <head>/*文件头*/ <title>标题</title>/*文件标题*/ </head> <body>内容</body> </html>/*文件结束*/
HTML常用的标记
<br>换行 <p></p>段落 <s></s>删除线 <b></b>字体粗体 <u></u>下划线 <em></em>斜体内容 <sub></sub> 下标 <sup></sup>上标 <hr></hr>水平线 <a></a>超链接 .....
Elasticsearch(下面简称ES)中的bool查询在业务中使用也是比较多的。在一些非实时的分页查询,导出的场景,我们经常使用bool查询组合各种查询条件。
Bool查询包括四种子句,
must
filter
should
must_not
我这里只介绍下must和filter两种子句,因为是我们今天要讲的重点。其它的可以自行查询官方文档。
must, 返回的文档必须满足must子句的条件,并且参与计算分值
filter, 返回的文档必须满足filter子句的条件。但是跟Must不一样的是,不会计算分值, 并且可以使用缓存
从上面的描述来看,你应该已经知道,如果只看查询的结果,must和filter是一样的。区别是场景不一样。如果结果需要算分就使用must,否则可以考虑使用filter。
光说比较抽象,看个例子,下面两个语句,查询的结果是一样的。
使用filter过滤时间范围,
GET kibana_sample_data_ecommerce/_search
{
"size": 1000,
"query": {
"bool": {
"must": [
{"term": {
"currency": "EUR"
}}
],
"filter": {
"range": {
"order_date": {
"gte": "2020-01-25T23:45:36.000+00:00",
"lte": "2020-02-01T23:45:36.000+00:00"
}
}
}
}
}
}
filter比较的原理
上一节你已经知道了must和filter的基本用法和区别。简单来讲,如果你的业务场景不需要算分,使用filter可以真的让你的查询效率飞起来。
为了说明filter查询的原因,我们需要引入ES的一个概念 query context和 filter context。
query context
query context关注的是,文档到底有多匹配查询的条件,这个匹配的程度是由相关性分数决定的,分数越高自然就越匹配。所以这种查询除了关注文档是否满足查询条件,还需要额外的计算相关性分数.
filter context
filter context关注的是,文档是否匹配查询条件,结果只有两个,是和否。没有其它额外的计算。它常用的一个场景就是过滤时间范围。
并且filter context会自动被ES缓存结果,效率进一步提高。
对于bool查询,must使用的就是query context,而filter使用的就是filter context。
我们可以通过一个示例验证下。继续使用第一节的例子,我们通过kibana自带的search profiler来看看ES的查询的详细过程。
使用must查询的执行过程是这样的:
可以明显看到,此次查询计算了相关性分数,而且score的部分占据了查询时间的10分之一左右。
filter的查询我就不截图了,区别就是score这部分是0,也就是不计算相关性分数。
除了是否计算相关性算分的差别,经常使用的过滤器将被Elasticsearch自动缓存,以提高性能。
我自己曾经在一个项目中,对一个业务查询场景做了这种优化,当时线上的索引文档数量大概是3000万左右,改成filter之后,查询的速度几乎快了一倍。
我们应该根据自己的实际业务场景选择合适的查询语句,在某些不需要相关性算分的查询场景,尽量使用filter context可以让你的查询更加。
前言
文章首次发表在 个人博客
之前写过一篇 web安全之XSS实例解析,是通过举的几个简单例子讲解的,同样通过简单得例子来理解和学习CSRF,有小伙伴问实际开发中有没有遇到过XSS和CSRF,答案是有遇到过,不过被测试同学发现了,还有安全扫描发现了可能的问题,这两篇文章就是简化了一下当时实际遇到的问题。
CSRF
跨站请求伪造(Cross Site Request Forgery),是指黑客诱导用户打开黑客的网站,在黑客的网站中,利用用户的登陆状态发起的跨站请求。CSRF攻击就是利用了用户的登陆状态,并通过第三方的站点来做一个坏事。
要完成一次CSRF攻击,受害者依次完成两个步骤:
登录受信任网站A,并在本地生成Cookie
在不登出A的情况,访问危险网站B
CSRF攻击
在a.com登陆后种下cookie, 然后有个支付的页面,支付页面有个诱导点击的按钮或者图片,第三方网站域名为 b.com,中的页面请求 a.com的接口,b.com 其实拿不到cookie,请求 a.com会把Cookie自动带上(因为Cookie种在 a.com域下)。这就是为什么在服务端要判断请求的来源,及限制跨域(只允许信任的域名访问),然后除了这些还有一些方法来防止 CSRF 攻击,下面会通过几个简单的例子来详细介绍 CSRF 攻击的表现及如何防御。
下面会通过一个例子来讲解 CSRF 攻击的表现是什么样子的。
实现的例子:
在前后端同域的情况下,前后端的域名都为 http://127.0.0.1:3200, 第三方网站的域名为 http://127.0.0.1:3100,钓鱼网站页面为 http://127.0.0.1:3100/bad.html。
平时自己写例子中会用到下面这两个工具,非常方便好用:
http-server: 是基于node.js的HTTP 服务器,它最大的好处就是:可以使用任意一个目录成为服务器的目录,完全抛开后端的沉重工程,直接运行想要的js代码;
nodemon: nodemon是一种工具,通过在检测到目录中的文件更改时自动重新启动节点应用程序来帮助开发基于node.js的应用程序
前端页面: client.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>CSRF-demo</title>
<style>
.wrap {
height: 500px;
width: 300px;
border: 1px solid #ccc;
padding: 20px;
margin-bottom: 20px;
}
input {
width: 300px;
}
.payInfo {
display: none;
}
.money {
font-size: 16px;
}
</style>
</head>
<body>
<div class="wrap">
<div class="loginInfo">
<h3>登陆</h3>
<input type="text" placeholder="用户名" class="userName">
<br>
<input type="password" placeholder="密码" class="password">
<br>
<br>
<button class="btn">登陆</button>
</div>
<div class="payInfo">
<h3>转账信息</h3>
<p >当前账户余额为 <span class="money">0</span>元</p>
<!-- <input type="text" placeholder="收款方" class="account"> -->
<button class="pay">支付10元</button>
<br>
<br>
<a href="http://127.0.0.1:3100/bad.html" target="_blank">
听说点击这个链接的人都赚大钱了,你还不来看一下么
</a>
</div>
</div>
</body>
<script>
const btn = document.querySelector('.btn');
const loginInfo = document.querySelector('.loginInfo');
const payInfo = document.querySelector('.payInfo');
const money = document.querySelector('.money');
let currentName = '';
// 第一次进入判断是否已经登陆
Fetch('http://127.0.0.1:3200/isLogin', 'POST', {})
.then((res) => {
if(res.data) {
payInfo.style.display = "block"
loginInfo.style.display = 'none';
Fetch('http://127.0.0.1:3200/pay', 'POST', {userName: currentName, money: 0})
.then((res) => {
money.innerHTML = res.data.money;
})
} else {
payInfo.style.display = "none"
loginInfo.style.display = 'block';
}
})
// 点击登陆
btn.onclick = function () {
var userName = document.querySelector('.userName').value;
currentName = userName;
var password = document.querySelector('.password').value;
Fetch('http://127.0.0.1:3200/login', 'POST', {userName, password})
.then((res) => {
payInfo.style.display = "block";
loginInfo.style.display = 'none';
money.innerHTML = res.data.money;
})
}
// 点击支付10元
const pay = document.querySelector('.pay');
pay.onclick = function () {
Fetch('http://127.0.0.1:3200/pay', 'POST', {userName: currentName, money: 10})
.then((res) => {
console.log(res);
money.innerHTML = res.data.money;
})
}
// 封装的请求方法
function Fetch(url, method = 'POST', data) {
return new Promise((resolve, reject) => {
let options = {};
if (method !== 'GET') {
options = {
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(data),
}
}
fetch(url, {
mode: 'cors', // no-cors, cors, *same-origin
method,
...options,
credentials: 'include',
}).then((res) => {
return res.json();
}).then(res => {
resolve(res);
}).catch(err => {
reject(err);
});
})
}
</script>
</html>
实现一个简单的支付功能:
会首先判断有没有登录,如果已经登陆过,就直接展示转账信息,未登录,展示登陆信息
登陆完成之后,会展示转账信息,点击支付,可以实现金额的扣减
后端服务: server.js
const Koa = require("koa");
const app = new Koa();
const route = require('koa-route');
const bodyParser = require('koa-bodyparser');
const cors = require('@koa/cors');
const KoaStatic = require('koa-static');
let currentUserName = '';
// 使用 koa-static 使得前后端都在同一个服务下
app.use(KoaStatic(__dirname));
app.use(bodyParser()); // 处理post请求的参数
// 初始金额为 1000
let money = 1000;
// 调用登陆的接口
const login = ctx => {
const req = ctx.request.body;
const userName = req.userName;
currentUserName = userName;
// 简单设置一个cookie
ctx.cookies.set(
'name',
userName,
{
domain: '127.0.0.1', // 写cookie所在的域名
path: '/', // 写cookie所在的路径
maxAge: 10 * 60 * 1000, // cookie有效时长
expires: new Date('2021-02-15'), // cookie失效时间
overwrite: false, // 是否允许重写
SameSite: 'None',
}
)
ctx.response.body = {
data: {
money,
},
msg: '登陆成功'
};
}
// 调用支付的接口
const pay = ctx => {
if(ctx.method === 'GET') {
money = money - Number(ctx.request.query.money);
} else {
money = money - Number(ctx.request.body.money);
}
ctx.set('Access-Control-Allow-Credentials', 'true');
// 根据有没有 cookie 来简单判断是否登录
if(ctx.cookies.get('name')){
ctx.response.body = {
data: {
money: money,
},
msg: '支付成功'
};
}else{
ctx.body = '未登录';
}
}
// 判断是否登陆
const isLogin = ctx => {
ctx.set('Access-Control-Allow-Credentials', 'true');
if(ctx.cookies.get('name')){
ctx.response.body = {
data: true,
msg: '登陆成功'
};
}else{
ctx.response.body = {
data: false,
msg: '未登录'
};
}
}
// 处理 options 请求
app.use((ctx, next)=> {
const headers = ctx.request.headers;
if(ctx.method === 'OPTIONS') {
ctx.set('Access-Control-Allow-Origin', headers.origin);
ctx.set('Access-Control-Allow-Headers', 'Content-Type');
ctx.set('Access-Control-Allow-Credentials', 'true');
ctx.status = 204;
} else {
next();
}
})
app.use(cors());
app.use(route.post('/login', login));
app.use(route.post('/pay', pay));
app.use(route.get('/pay', pay));
app.use(route.post('/isLogin', isLogin));
app.listen(3200, () => {
console.log('启动成功');
});
执行 nodemon server.js,访问页面 http://127.0.0.1:3200/client.html
CSRF-demo
登陆完成之后,可以看到Cookie是种到 http://127.0.0.1:3200 这个域下面的。
第三方页面 bad.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>第三方网站</title>
</head>
<body>
<div>
哈哈,小样儿,哪有赚大钱的方法,还是踏实努力工作吧!
<!-- form 表单的提交会伴随着跳转到action中指定 的url 链接,为了阻止这一行为,可以通过设置一个隐藏的iframe 页面,并将form 的target 属性指向这个iframe,当前页面iframe则不会刷新页面 -->
<form action="http://127.0.0.1:3200/pay" method="POST" class="form" target="targetIfr" style="display: none">
<input type="text" name="userName" value="xiaoming">
<input type="text" name="money" value="100">
</form>
<iframe name="targetIfr" style="display:none"></iframe>
</div>
</body>
<script>
document.querySelector('.form').submit();
</script>
</html>
使用 HTTP-server 起一个 本地端口为 3100的服务,就可以通过 http://127.0.0.1:3100/bad.html 这个链接来访问,CSRF攻击需要做的就是在正常的页面上诱导用户点击链接进入这个页面
CSRF-DEMO
点击诱导链接,跳转到第三方的页面,第三方页面自动发了一个扣款的请求,所以在回到正常页面的时候,刷新,发现钱变少了。
我们可以看到在第三方页面调用 http://127.0.0.1:3200/pay 这个接口的时候,Cookie自动加在了请求头上,这就是为什么 http://127.0.0.1:3100/bad.html 这个页面拿不到 Cookie,但是却能正常请求 http://127.0.0.1:3200/pay 这个接口的原因。
CSRF攻击大致可以分为三种情况,自动发起Get请求, 自动发起POST请求,引导用户点击链接。下面会分别对上面例子进行简单的改造来说明这三种情况
自动发起Get请求
在上面的 bad.html中,我们把代码改成下面这样
<!DOCTYPE html>
<html>
<body>
<img src="http://127.0.0.1:3200/payMoney?money=1000">
</body>
</html>
当用户访问含有这个img的页面后,浏览器会自动向自动发起 img 的资源请求,如果服务器没有对该请求做判断的话,那么会认为这是一个正常的链接。
自动发起POST请求
上面例子中演示的就是这种情况。
<body>
<div>
哈哈,小样儿,哪有赚大钱的方法,还是踏实努力工作吧!
<!-- form 表单的提交会伴随着跳转到action中指定 的url 链接,为了阻止这一行为,可以通过设置一个隐藏的iframe 页面,并将form 的target 属性指向这个iframe,当前页面iframe则不会刷新页面 -->
<form action="http://127.0.0.1:3200/pay" method="POST" class="form" target="targetIfr">
<input type="text" name="userName" value="xiaoming">
<input type="text" name="money" value="100">
</form>
<iframe name="targetIfr" style="display:none"></iframe>
</div>
</body>
<script>
document.querySelector('.form').submit();
</script>
上面这段代码中构建了一个隐藏的表单,表单的内容就是自动发起支付的接口请求。当用户打开该页面时,这个表单会被自动执行提交。当表单被提交之后,服务器就会执行转账操作。因此使用构建自动提交表单这种方式,就可以自动实现跨站点 POST 数据提交。
引导用户点击链接
诱惑用户点击链接跳转到黑客自己的网站,示例代码如图所示
<a href="http://127.0.0.1:3100/bad.html">听说点击这个链接的人都赚大钱了,你还不来看一下么</a>
用户点击这个地址就会跳到黑客的网站,黑客的网站可能会自动发送一些请求,比如上面提到的自动发起Get或Post请求。
如何防御CSRF
利用cookie的SameSite
SameSite有3个值: Strict, Lax和None
Strict。浏览器会完全禁止第三方cookie。比如a.com的页面中访问 b.com 的资源,那么a.com中的cookie不会被发送到 b.com服务器,只有从b.com的站点去请求b.com的资源,才会带上这些Cookie
Lax。相对宽松一些,在跨站点的情况下,从第三方站点链接打开和从第三方站点提交 Get方式的表单这两种方式都会携带Cookie。但如果在第三方站点中使用POST方法或者通过 img、Iframe等标签加载的URL,这些场景都不会携带Cookie。
None。任何情况下都会发送 Cookie数据
我们可以根据实际情况将一些关键的Cookie设置 Stirct或者 Lax模式,这样在跨站点请求的时候,这些关键的Cookie就不会被发送到服务器,从而使得CSRF攻击失败。
验证请求的来源点
由于CSRF攻击大多来自第三方站点,可以在服务器端验证请求来源的站点,禁止第三方站点的请求。
可以通过HTTP请求头中的 Referer和Origin属性。
HTTP请求头
但是这种 Referer和Origin属性是可以被伪造的,碰上黑客高手,这种判断就是不安全的了。
CSRF Token
最开始浏览器向服务器发起请求时,服务器生成一个CSRF Token。CSRF Token其实就是服务器生成的字符串,然后将该字符串种植到返回的页面中(可以通过Cookie)
浏览器之后再发起请求的时候,需要带上页面中的 CSRF Token(在request中要带上之前获取到的Token,比如 x-csrf-token:xxxx), 然后服务器会验证该Token是否合法。第三方网站发出去的请求是无法获取到 CSRF Token的值的。
其他知识点补充
1. 第三方cookie
Cookie是种在服务端的域名下的,比如客户端域名是 a.com,服务端的域名是 b.com, Cookie是种在 b.com域名下的,在 Chrome的 Application下是看到的是 a.com下面的Cookie,是没有的,之后,在a.com下发送b.com的接口请求会自动带上Cookie(因为Cookie是种在b.com下的)
2. 简单请求和复杂请求
复杂请求需要处理option请求。
之前写过一篇特别详细的文章 CORS原理及@koa/cors源码解析,有空可以看一下。
3. Fetch的 credentials 参数
如果没有配置credential 这个参数,fetch是不会发送Cookie的
credential的参数如下
include:不论是不是跨域的请求,总是发送请求资源域在本地的Cookies、HTTP Basic anthentication等验证信息
same-origin:只有当URL与响应脚本同源才发送 cookies、 HTTP Basic authentication 等验证信息
omit: 从不发送cookies.
平常写一些简单的例子,从很多细节问题上也能补充自己的一些知识盲点。
当下“两微一抖”已成为企业品牌传播必备的渠道策略,可见抖音的江湖地位不容小觑。
抖音,诞生于2016年9月,是一款“音乐创意”短视频社交软件。截至2020年1月,其日活跃用户数突破4亿,而同属短视频行业的快手的日活跃用户数也才刚过3亿。要知道,在2016年6月,当时抖音还没上线,快手就坐拥3亿注册用户数。显而易见,抖音不过是一个后起之秀,却能傲视群雄。
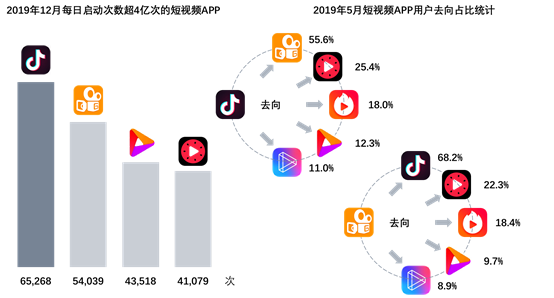
短视频行业的数据统计
也有数据表明,抖音用户的粘性很大,转去玩快手的用户只有55.6%,反而快手用户转去玩抖音的高达68.2%。快手高级副总裁马宏斌也曾透露,快手前100名的大V有70个是抖音用户,抖音前100名的大V只有50个是快手用户。
一般认为,一个人80%的成功几率是由冰山模型水平面以下要素:动机、价值观/性格和综合能力决定的,另外20%是由冰山模型水平面以上要素:经验和技能决定的。
而且,上层要素的生长受到底层要素的制约:一个人有什么样的动机,就会促使他/她着重培养哪方面的综合能力;有什么样的价值观/性格,对他/她的行为举止也会产生一定约束力,什么该做,什么不该做。
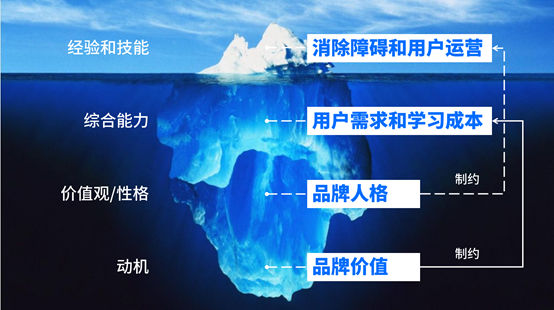
互联网产品的冰山模型
如果把一家互联网公司的品牌视为一个人,那么动机就是品牌价值,价值观/性格就是品牌人格,综合能力就是营销4C中的用户需求(Customer)和学习成本(Cost),经验和技能就是营销4C中的消除障碍(Convenience)和用户运营(Communication)。
抖音的成功可从冰山模型自下而上进行总结:
从最初的品牌Slogan——让崇拜从这里开始,以及有一头条的员工在朋友圈晒出公司的背景墙——让更多人的美好生活被看见,可以看出抖音成立的动机——帮助更多人提升个人知名度。

字节跳动的公司背景墙
这个动机是基于对社会冲突的深刻洞察:近年来各类选秀节目(如:中国好声音、超级女声等)的热播透露出许多年轻人心藏一个明星梦,但由于家庭出身、人际资源、社会财富等先天条件限制不得不放弃追逐梦想。城市已经发展到需要一个品牌来给这批年轻人创造机会的时候,抖音应运而生。
作为一个创造者,抖音还找到了提升个人知名度应该具备的人格特质——精致(Sophistication),并以这样的人格特质与城市年轻群体沟通,包括借助明星光环来诠释何为精致、掷重金在各大城市举办美好生活节……这些事件在目标群体里迅速传开,并取得目标人群的情感认同和品牌信任。

在抖音里明星云集
注:精致(Sophistication)、称职(Competence)、刺激(Excitement)、坚韧(Ruggedness)和真诚(Sincerity)是J.Aaker通过问卷调查得出的五大最容易被消费者感知的人格特质,而且这五大特质也能概括许多流行品牌在消费者心目中的人格形象。
在站内,抖音致力于帮助更多人提升个人知名度,加强产品功能和用户体验,让更多人得到同等机会展示自我。
在用户需求(Customer)方面,采用了去中心化内容分发机制,当内容创作者发布一条短视频后,抖音并不是把这条短视频发给创作者的所有粉丝用户,而是小范围分发测试这条短视频的潜力,让可能喜欢这类内容的标签用户通过行动来评价。只有获得更多用户认可的优质短视频才能得到二次流量推荐,进而成为爆款,创作者就有机会爆红。同时,采用了全屏自动播放模式,让每一条短视频都能被观看,不失为一种公平竞争。
抖音的产品功能
在学习成本(Cost)方面,采用了中心化内容生产机制,组建了服务达人的MCN机构,由平台签约明星、网红和大V推出一个个可复制、易模仿的有趣短视频,降低用户学习门槛。同时,运营团队也会不定期发起各类短视频挑战赛,提供各种滤镜、剪辑技能、流行音乐等素材,即使普通用户没有创新力,跟风模仿也能拍出看起来酷炫的、专属于自己的15秒“大片”。
在站外,抖音秉承“精致”理念开展一系列PUGC营销活动,持续影响用户的感知,并不断强化精致的人格特质。

抖音冠名综艺节目
在消除障碍(Convenience)方面,抖音通过冠名一些和明星互动的综艺节目,比如中国有嘻哈、快乐大本营、天天向上等,借助节目酷炫的舞台效果和高度吻合的受众群体,消除年用户从产品感知到下载应用之间存在的疑虑——抖音是否有实力助我提升知名度?事实上,抖音已经帮助不少草根明星(如刘宇宁、陆超等)登上主流媒体的舞台,让用户看到了展示自我的机会、成为明星的希望。
在用户运营(Communication)方面,除了大众明星入驻,引入其他平台的网红和大V,还与多家MCN机构合作,扶持和培养平台内的潜力用户,保证内容的质量和持续产出。同时,不定期更新挑战活动、热门搜索、加强品牌合作激励用户创作,以增强用户对抖音的依赖和活跃。在参与创作的过程中,用户也能得到抖音提供的专群维护、不定时礼物、拍摄指导、流量曝光等多方面帮助。

抖音品牌活动及福利
写到这里,你可能会惊叹一声:哦,原来如此!
但是换到自己来做品牌、运营产品,你就会一脸懵逼了。要么无从下手,要么觉得每天的工作就是打杂,不知道做这些运营动作意义何在。你制定的运营计划也可能是杂乱无章,运营策略多半也是效仿其他大品牌,在各个产品生命周期阶段没有什么不同。
产品运营人的苦恼
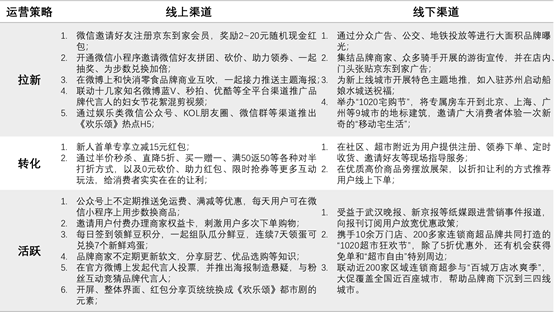
产品运营的策略制定
所以,我们应该从抖音身上学如何“做正确的事“,并且”正确地做事“——把产品当作对社会有贡献的人来培养,寻找能让它快速被社会接纳的人格特质(做正确的事),然后在不同的成长阶段制定相应的历练计划,并长期坚持做事风格的一致性,而不是一天一个花样模糊了用户对品牌的印象(正确地做事)。
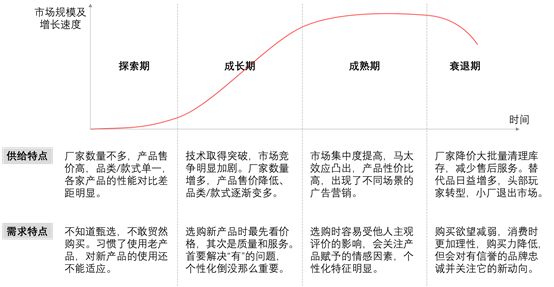
行业生命周期曲线
探索期:市场供给量和需求量低,增长速度只有3%左右。只有一部分有研发实力的企业在生产产品,因为试错率高、生产成本高,使得企业不敢做出太多花样,产品售价普遍也高。对于消费者来说,老产品的转换成本高,新产品的功能还不稳定,普遍是观望态度。
成长期:市场供给量和需求量增加,增长速度达到10%以上。这时候产品技术已取得突破性进展,可大规模复制生产,部分产品还是供不应求。随着进入市场的企业数量增多,企业的竞争就是价格战(红包、补贴)和产品多元化,助长了市场抢购风气,强化了消费者对价格的敏感性。
成熟期:市场供给量和需求量接近峰值,增长速度在5%以下。企业占有的市场份额越多,其产品销路越宽卖得越好。企业之间的竞争从瓜分空白市场变成了抢占对手的市场,营销手段多了起来,导致消费者出现了选择困难症,这时企业的口碑开始发挥了作用。
衰退期:市场供给量和需求量下降,增长速度在0%以下。消费者的消费观念改变了,市场出现了供过于求的现象,而替代品日益增多又带来冲击,企业开始大批量清理库存,行业标杆在现有的口碑基础上向新产业转型,小工厂则因资金不足被迫退出市场。
从行业的发展规律来看,只有产品的企业会因行业变化而被淘汰,但是有好口碑的企业却不会,因为它可以引导用户消费来应对市场挑战。

新媒体时代下的需求
首先,根据行业供给和需求特点细分出公司产品的目标用户群,描绘能给产品创造最大价值的核心人群画像,然后洞察他们在社交生活中未被得到满足的需求:在新媒体时代,每个人都想成为“主角”,年轻人更急于寻求个性表达,但自拍效果不够酷,也没有太多技能加持。
其次,了解标杆/竞争对手又是如何解决这些现实冲突,对目标用户群说了什么。作为抖音的头号竞争对手——快手,以“记录世界,记录你”作为Slogan,具有很浓的个人主义色彩,乍一看以为是帮助感情受到挫折的人走出伤痛,学会自我疗愈。
最后,顺势而为,不违背或超前于行业发展,将核心人群的需求痛点与公司产品利益点建立连接,从事实主张、认知区隔、情感主张和价值区隔中挑选适合当下的一种广告内容。
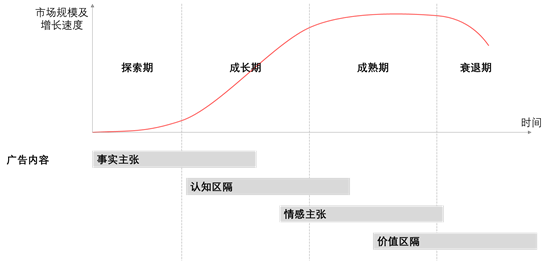
不同生命阶段的产品广告内容
事实主张:根据品牌内部能力或资源的明显优势进行突出定位,传达所具备的事实优势壁垒,直击重点。如:早期的抖音——让崇拜从这里开始。
适用评估:企业在行业中具有先发优势,在组织资源方面具有强大的科研能力、上市速度快,在产品/服务方面是行业唯一,不容易被模仿/超越。
认知区隔:在受众心中建立独特记忆认知,让受众对于该品牌和其他某种特定行为或体验产生强关联,从而做出选择。如:现在的抖音——记录美好生活。
适用评估:行业中出现了新的关键驱动因素,消费者心智中还有其他尚未被占领的空间。
情感主张:提炼品牌中蕴含的情感因素,通过向受众传递美好的情感联想,让受众将心中期望憧憬与品牌实现关联。如:格力——让世界爱上中国造。
适用评估:除功能性需求外,目标用户群还有情感性需求未被满足。相比竞争对手,产品包装设计、信息传播更能触动用户情感,公司愿景能够引发消费者共鸣。
价值区隔:传达品牌对于受众产生的某种独特价值观,且能通过产品体现在受众心中形成心理认同,产生价值共鸣。如:耐克——Just do it。
适用评估:已经积累了一定数量的用户群,公司愿景切换用户心理并引领时代,取得了行业KOL、大V等背书。
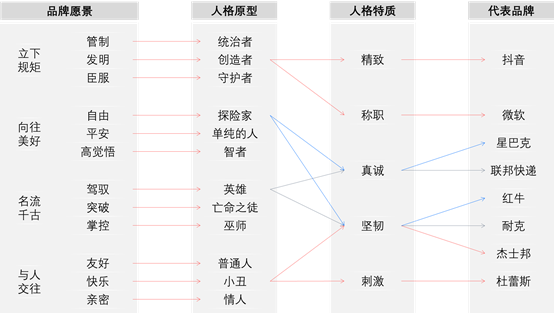
品牌人格原型及特质
将创始人/团队个性特征和公司产品的发展愿景两方面因素综合匹配,找到适合公司长远发展的人格原型。
不同的品牌塑造如同人的成长,不同的基因决定了不同的人格,不同的人格决定了不同的传播调性,不同的传播调性又决定了受众对品牌的不同反应。有生命力的长寿品牌是具有人格原型的。一个成功的品牌人格,可以让品牌拉近与用户的情感距离,并且在用户心智刻画出鲜明难忘的品牌形象。
所以,确立相应的品牌人格后,找出核心人群最可能听具有什么样人格特质的人说的话,然后学习这类人的表达方式、行动风格等,以此作为产品运营的人设模板并长期坚持不断强化。

产品生命周期曲线
产品所处的生命周期阶段一般可从以下几个方面进行判断:
探索期:日下载量/销量极低,市场占有率几乎为0。该阶段主要任务就是寻找高质量的种子用户,让用户参与产品体验,并对产品提出优化建议。种子用户一般控制在100个左右,多了会交流不过来,严重地会导致分不清主次需求。这些种子用户可以是有一定圈子影响力的同事或朋友,与产品沾边的相关领域意见领袖(KOL),微信(群)、微博、垂直论坛等网络大V。那么如何让对方搭理我们愿意成为种子用户?我们得事先准备一个鼓舞人心的品牌故事,愿景是致力于解决某一个非常紧迫的社会难题,现正寻找一群志同道合的人一起攻克。
成长期:日下载量/销量、 日/月活量、营收增多而且增速较快,但与头部竞品的市场占有率相比还有很大差距。该阶段的主要任务就是激发用户尚未意识到或未被满足的需求,一旦使用产品后能够给生活带来不一样的感觉。例如,有些年轻人喜欢自拍模仿明星,但鲜有人围观,最终沦为自娱自乐。于是抖音推出一条“找呀找呀找爱豆”竞猜H5,一下子刷爆了朋友圈,为模仿者,也为抖音带来了巨大的流量关注。在那之后,抖音开始找一些明星合作增加产品流量和话题,让更多的用户也加入到抖音队伍中来。

让抖音一炮而红的宣传
成熟期:日下载量/销量基本稳定,已占据了一定市场规模,但日/月活量、营收仍在增加。该阶段主要任务就是对用户进行精细化运营,围绕用户的地域、人口特征、消费品类、品牌偏好,购物行为、生活场景和用户价值七大维度进行用户分群贴标签,然后收集用户贡献值,如活跃度、购买力情况等数据将用户按二八原则分为不同等级:1%为重要客户,19%为主要客户,30%为普通客户,50%为长尾客户,让不同等级用户享受到不同的专属服务,培养用户的忠诚度和提高客单价。
衰退期:日下载量/销量、日/月活量、营收均出现明显下滑。该阶段主要任务就是牢牢把握住核心用户,通过发起有影响力的社会公益活动扩大品牌影响力的边界,开发出和产品/服务强相关的常用周边产品,满足用户的新需求。同时关注行业的潜在进入者动态,通过升维或降维的方式尝试创新转型,升维是指增加自身的实力,给同质化的产品或服务附加超值的东西;降维是指用高级、全套的打法平移到相对落后的空间,如车企推出网约车服务。
人格是贯穿始终的唯一宗旨,包括内容定位、行文风格、推送时间等在长时间内都是保持不变,让内容集成为一个有人格特质、高辨识度的符号。

内容运营的基本流程
首先,打好内容定位的核心基础,分析用户TA是谁、在哪、每天在做什么、有什么偏好等等,制作出不同于竞品的差异化内容,如图文、视频等类型上的差异,漫画、直播、弹幕等形式上的差异,猎奇、愉悦、慰藉等需求上的差异,形成产品特有的内容亮点。内容亮点是热点和特点的集合,热点源于长期不断积累的素材库、百度热搜和微博热搜,特点则是产品特性和品牌人格的总结。
其次,建立内容生产的素材库和人才库。素材库的建立主要通过以下三种方式,一是对时事保持敏感,搜集和整理每天的新闻热点;二是对舆论保持敏感,通过百度搜索风云榜、微博热搜实时榜等网络渠道了解当下的热点;三是保持的运营思维,收藏和分析最近的优秀内容案例。
人才库的建立通常是先寻找和记录的优质内容创作者,包括个人和机构,然后联系和维护这些优质内容创作者,平时也多加留意热点文章的作者,随时更新和完善优质内容创作者的信息。
当然人才的关系维护离不开一整套合理的合作机制:找到能够帮我们传达信息和组织其他用户的超级用户后,要用产品资源对其进行包装和曝光,如:经纪团队挖出杨超越“村花”这个事件点后,通过节目再不断发酵出各种新的事件。然后再找更多的超级用户,复制这一模式,不断重复循环操作。也可以从不同角度对内容生产者设置不同的奖项,如:微博之夜,由官方定小奖,用户投票定大奖,让80%的用户参与评选,最终给20%的用户颁奖。
再次,有组织地进行内容加工和包装。常见的高级包装有专题和专栏两种:专题是特定事件的内容集合(世界杯专题)、特定时间的内容集合(6月原创歌曲排行榜)、特定场景的内容集合(抖in City 美好生活节)。专栏是特定主题的连续内容(今日说法)、特定领域的连续内容(舌尖上的中国)、特定形式的连续内容(焦点访谈)。
一般加工流程是根据内容的定位确定要生产的内容主题,搭建最终想要呈现的内容框架,用最酷或最土的方式击中用户。再从素材库中挑选出有用的元素,撰写一个优秀的内容策划方案,在特定的时间推一些能引起目标用户情感共鸣的话题。也可以把内容框架和素材给到人才库的创作者,将他们生产的内容包装成一个栏目。又或者把所有具备共性的内容抽离出来,提炼出一个主题,这个主题是没有立场之分,能够引起正反方辩论的。
最后,在用户可触达的渠道发布内容。试想在0预算的情况下,借势热点利用产品功能以不同的方式(Push、Banner、客服等)内推给用户,或者在免费平台(微信微博)建立基础的外推渠道。也可以在一条或多头内容上加入玩法(如:评论、直播、弹幕、测试等),引导用户进行互动传播。为了能让用户有意愿参与,可按用户分层(人群、年龄、工作标签、用户等级等)、内容分层(超级内容、头部内容、信息流内容)、时间场景(上班、周末、休假等)、空间场景(办公、餐厅、酒店等)进行内容精准推荐。个人建议,任何栏目或版块都应有C位内容,把它们放在最显眼的位置。
根据活动举办的周期性,活动类型可分为常规活动、原创活动和节点活动三类。
常规活动,主要包括各种节假日活动、用户共知的节日活动,比如世界杯、NBA总决赛、奥斯卡颁奖等;
原创活动,主要是一些品牌积累到了一定用户基础并有广泛的品牌认知,结合产品本身特点打造的专属性活动,比如天猫的双十一,京东的618等;
节点活动,主要是针对产品生命周期的用户特点开展的重大运营活动,比如为了需求唤醒、信息互动在拉新阶段开展的【新人红包】,为了培养使用习惯、购买升级在促活阶段开展的【每日签到】,为了增强购买升级、精细服务在转化阶段开展的【首单立减】,为了建立用户口碑在传播阶段开展的【分享有礼】。

节点活动目的及手段
每一个活动必须要有一个目标,活动运营的目的无非就是提升粘性、加快用户转化、增强消费决策、提升用户复购和扩大活动传播五个要点。

活动策划的目的及手段
提升用户粘性,实现该目标的关键点(或者说如何让用户养成使用产品的习惯)是让用户在产品上消耗时间,有时间投入,或对产品价值有一定预期,常用的手段就是每日签到各种任务;
加快用户转化,实现该目标的关键点(或者说如何让用户产生付费的意愿)是突出产品在某一方面的实用价值,常用的手段是红包/优惠券,新人特权;
增强消费决策,实现该目标的关键点(或者说如何催促用户尽快下单)是通过价格冲击和优惠策略刺激用户消费,常用的手段是限时秒杀,特殊优惠;
提升用户复购,实现该目标的关键点(或者说如何让用户多次购买,买的更多)是为用户提供信息筛选或新奇有趣的内容,常用的手段是内容/商品精选,特定补贴;
扩大活动传播,实现该目标的关键点(或者说如何让用户主动分享产品信息)是赋予产品更多的内容娱乐价值和社交价值,常用的手段是转发/邀请有奖,测试小游戏。
本着与用户交朋友的心态服务用户,循序渐进为用户谋福利,让用户感知到并不断强化品牌的人格特质。

用户运营的基本流程
拉新:利用高频使用、刚需、大众化需求等流量爆品(如公交刷卡、比价搜索等),以丰富内容形式(如直播、短视频、吉祥物IP等)来吸引用户的策略,进行搜索引擎、新媒体平台、应用商店等线上宣传,或扫楼发传单、赠品合作、地面广告等线下硬广。但是宣传渠道并不是越多越好,事前需要考虑到关于流量效率的问题并做好渠道调研,是不是精准流量来的用户,拉新渠道不精准,获客成本高,用户质量差。
在宣传过程中,适当使用折扣、抽奖、代金券、红包、限时限量购等营销工具,或者团购、预售/众筹、邀请返利、二级分销等社群裂变方法。值得注意的是每一款产品都应该有一个核心的拉新手段/方式,东打一棒西揍一拳,如此从各个渠道得到的流量不会太多。所以建立快速稳定的热点扩散渠道是有必要的,推荐一种方法:强控公司员工朋友圈,然后维护核心种子用户群,再利用双微一抖等第三方管理工具进行效果检测,最后对每个热点创意进行总结、复盘和优化。
盘活:从用户接触产品后需要有一个引导文案或指导规范,突出产品核心功能、利益点,让用户知道这款产品是干嘛用的,对TA有什么好处,给他什么东西希望TA留下来。常见的引导方案就是设计丰富的新手特权,引导用户尝试不同类型资产投资,比如完成签到、转发、评论、收藏等各种任务就可以获得各种奖励。用户能够完整地使用或操作产品全流程,才算是一个有效的、相对稳定的新用户。如果产品服务体验不精准/认知度差,新用户容易流失、产品口碑差。
防流失:一次给用户发多张券,分为不同的面额和门槛,引导用户完成5次以上消费,同时设置连续购买多单就给奖励,缩短付费时间间隔,加速用户生命周期的进化。还可以搭建常态化的活动体系,在固定的时间点(如:每天10点,每月8日等)开展每日秒杀、限时抢购、会员日等的促销活动,让用户形成具备记忆点的活动预期。
对于一个已经流失的用户,可以通过电话召回(重点用户)、短信/App消息、品牌宣传(老用户)、大型促销活动等手段召回,为他们提供限时特权、红包/抵用券、新品发布/重大改版、重点促销商品等新体验。为什么我们宁愿花时间去召回一个老用户而不是寻找新用户,因为召回一个老用户带来的效益要远大于一个新用户的获取成本,老用户已经熟悉我们的产品,不需要太多的教育成本,而且能够直接带来效益的。当然并不是真的等到用户已经流失才会采取行动,我们可以通过RFM模型监控用户活跃情况,对潜在的流失用户进行预警,并且采取相应的挽留措施。
强粘性:建立用户成长体系,比如用户积分体系、积分商城,用户等级体系、会员体系、勋章、证书等。用户成长体系是一整套驱动用户成长的运营机制,是在用户数据模型的基础上,比如交易类产品的累计交易金额、交易频次、交易类型、交易质量等,内容类产品的用户参与度、内容贡献度、用户活跃度等,工具类产品的用户活跃度、用户ARPU值、用户访问时长等,找到用户成长的关键路径和核心驱动力,从而搭建用户成长的激励通道和连接用户行为的触达通道。
促转化:常见的有提高客单价、增加关联购买和拓展盈利模式三种手段。提高客单价手段再细化就是满额立减、满件立减的满减优惠,加N元送配件/日化用品的加价购,第二件半价的N件N折。制作场景、季节专题或推出产品套装就是为了增加关联购买。在拓展盈利模式里,除了线下探索,将产品和服务延展到线下,寻找产品/服务强相关的常用周边商品,提高品类的丰富度。还可以设置会员专属服务,不同等级会员享受不同的服务,首次付费有优惠。
在用户运营工作中最难的是搭建用户成长体系。当然不建议产品刚上线就做用户成长体系,当用户达到一定量级,知道哪些用户对产品贡献值最大后再考虑要不要做、怎么做,而且用户等级不易超过4级。据调查,抖音至今都没有对外公开(就当不存在)用户成长体系,用户也不会知道自己处于哪个等级,有哪些特殊权益。

用户成长体系搭建的基本流程
首先建模型,可以沿用用户漏斗模型,提升从访客、下单到支付每个环节的运营效率,实时关注用户反馈,看用户是在哪个点流失的,这个点就是要优化的地方;也可以沿用用户生命周期模型,判断用户处于哪一阶段,设定对应的运营规则;还可以沿用用户价值模型,根据用户在不同阶段对产品的贡献度,设定对应的运营规则。
其次搭通道,激励通道主要有秒杀/限时抢购、抽奖、代金券/红包、特权等级、积分/成长值/经验值、任务引导;触达通道主要包括关键访问路径、短信、邮件、产品通知功能、微信渠道、个性化Push等。
最后促成长,通常采用补贴策略、在成长节点触发消息推送和抓牢动力引擎三种方式。动力引擎主要包括:内容类产品的高质量、率、内容形态丰富,电商类产品的低价格、高品质、物流快、品类丰富,教育类产品的优秀师资、系统化教学,金融类产品的供给渠道、电商化、游戏化,出行/外卖类产品的供给驱动、匹配、优质服务,工具类产品的解决具体问题的效率。
了解行业发展及竞争对手动态,及时调整品牌的价值主张,加快催熟成长期的产品,或扩大品牌影响力的边界延长产品的成熟期。无论运营重心怎么变,但品牌人格和人格特质不能改变。
在扩大品牌影响力的边界方面,除了借助用户故事都自带自传播的特点,对有代表性的用户故事进行包装,前提是故事一定要真实,把品牌人格的塑造得更富有真情实感。个人推荐发起社会公益活动,就像蚂蚁森林一样打破虚拟空间,通过线上攒能量种树活动,再把4亿+用户的这份参与热情展现到线下——在沙漠种真实的树苗。
文章来源:人人都是产品经理 作者:炒冷饭的二叔
蓝蓝设计的小编 http://www.lanlanwork.com
