如果您想订阅本博客内容,每天自动发到您的邮箱中, 请点这里
很多产品设计师,在画原型或者设计 UI 的时候痴迷于工具的使用,拿到需求文档之后急于动手画图,忽略了信息架构设计对于产品的作用。
信息架构作为一个产品的骨架,是产品非常重要的一部分,它决定了一个产品
的布局和未来的发展方向以及用户对一个产品的最初印象和整体体验。毫不夸张的说,好的产品信息架构是产品成功的一半。
那么到底什么是产品的信息架构呢?该如何设计产品的信息架构?如何评判一个产品信息架构的好坏?我们接着往下看:
让我们来看一个例子:

一个饭店需要有哪些设施,如果你是饭店的老板如何合理的排布这些设施,可以让客户感觉很舒服的用餐,这个过程就是一个信息架构的过程。他可以让客户对你的饭店产生好感,从而下次用餐的时候还会想到来你这里吃饭。
在排布饭店设施的过程中我们要遵循一些规范,比如用户的习惯或者施工规范等,正是因为需要遵循这些规范,所以我们需要一个信息架构来体现这些。
比较官方的信息架构解释是这样的:信息架构设计是对信息进行结构、组织以及归类的设计,好让使用者与用户容易使用与理解的一项艺术与科学。
简单来说,信息架构设计就是让用户可以 容易地理解你的产品是怎样的。让他们在使用你产品的时候可以更顺利更自然。就像一进入饭店就会有一种感觉,门口是等餐的地方,进去就应该吃饭,如果找洗手间一定不会往门口走,而会往深处走。这就是信息架构的好处:他让用户使用同类产品时更容易上手和理解,让产品更容易被接受。
那对于线上产品来说为什么需要合理的信息架构呢?大家来看下边3组 app 的 tab栏截图。你能仅仅从 tab栏就看出这款 app 是什么类型的 app,如何使用吗?

很明显的,第一个是一款购物类 app,第二个是一款图片社交类的 app,第三个是微信的 tab,虽然首页名称是微信,但是我相信如果把名称换成「聊天」,你还是能认出这是微信的 tab栏。
从底部标签栏就可以大致看出产品是用来干嘛的,这就是信息架构的作用。一个合理的信息架构可以让产品非常容易被用户理解,可以让用户第一眼对产品有一个简单的认知,指导自己可以用产品做什么事,指导产品提供什么服务。
再看一组反例:

这三组 tab栏就让人很困惑了,看了半天你也许根本不知道这几款 app 是做什么用的,以及如何使用。如果你让用户很困惑,他会分分钟抛弃你的 app。
所以信息架构的核心目标是为用户提供更好的体验,获得更高的留存率。
一款信息架构良好的产品必然遵循以下两个标准:
我们通过这两个标准来印证下上边3个正面案例的信息架构:

相信你能很快速的识别出这款软件的用途和用法,这就给提升留存提供了基础。
那么如果信息架构像架构一个饭店一样简单,那么信息架构为何需要设计?

因为你的实际产品功能可能有这么多:

毕竟我们不是支付宝,没办法把功能像豆腐块一样堆叠起来,我们需要一些科学的设计方法。
合理的信息架构设计需要考虑5个步骤:

下面我来分步讲解一下。
首先你的产品是给到用户用,你当然要最大限度的了解你的用户,我们先来看下一个概念:「心智模型」。

心智模型是经由经验及学习,脑海中对某些事物发展的过程,所写下的剧本。人类在经历或学习某些事件之后,会对事物的发展及变化,归纳出一些结论,然后像是写剧本一样,把这些经验浓缩成一本一本的剧本,等到重复或类似的事情再度发生,我们便不自觉的应用这些先前写好的剧本,来预测事物的发展变化。心智模型是你对事物运行发展的预测。再说得清楚一点,你「希望」事物将如何发展,并不是心智模型,但你「认为」事物将如何发展,就是你的心智模型了。
假设你从没见过 iPad,而我刚递给你一台并告诉你可以用它来看书。在你打开 iPad 使用它之前,你头脑里会有一个在 iPad 上如何阅读的模型。你会假想书在 iPad 屏幕上是怎样的,你可以做什么事情,比如翻页或使用书签,以及这些事情的大致做法。即使你以前从没有使用过 iPad,你也有一个用 iPad 看书的「心智模型」。你头脑里的心智模型的样式和运作方式取决于很多因素。
用户往往带着以往使用 APP 的一些习惯来使用产品;线下做同一件事的习惯、生活习惯、心智模型等。要考虑哪些是可以创新的,哪些是用户习惯,要在不妨碍用户习惯的情况下作出更能让用户接受的创新。
你要考虑清楚4个问题:
用户通常用你的产品做什么?
用户用你的产品来做什么?用来看新闻还是用来聊天?一定要考虑清楚用户的核心流程。从核心流程中提取信息架构的基础形式。
用户用这类产品最关心什么?
用新闻app 时咨询的真实性实效性,购物类app 精准搜索和售后功能,就是你的用户关注点在哪里,这是一个很好的突破口。
用户有哪些思维定式?
和用户年龄身份相关的属性,产品体验符合相应用户的思维模式,心智模型,用户就会比较容易接受。
用户用什么类似的产品?
类似的产品也会带来一些用户习惯,迎合这些习惯也会让用户快速上手接受产品。
了解了你的用户场景和使用习惯之后你会知道如何做出符合用户心智的,容易被接受的产品,你不需要担心做的产品没有差异性或者没有竞争力,我们可以在核心流程之外做出创新点,让用户觉得你的产品又好用又有些不一样。
这里的业务包括与产品接触的内部及外部的人提出的需求,比如公司的运营,市场,销售,BD,公司的外部合作伙伴等。
这些人的需求我们也要收集,比如运营人员想更方便的管理注册用户,销售想更多的添加广告位,市场推广人员要求能统计不同渠道带来产品的下载量,注册数,活跃数,合作伙伴需要进行账号,内容互通等,总之只要与业务有关的人的意见,尽可能的在产品设计前多收集,即使做不了,也告诉他们原因,要不然产品上线后就等着被他们吐槽吧。
在做一款 app 时,我们面临了和无数竞品争抢用户的局面,这时候分析竞品就非常必要,我们需要在知己知彼的前提下,做好核心流程功能,再思考如何在差异功能上做好突破。
首先我们需要把竞品功能梳理成思维导图:

其实思维导图就是信息架构比较基础的形式了,但是光有思维导图没用,我们需要对思维导图进行分析。
我以前做过的一款人脉 app 为例,当初对比了领英、赤兔和脉脉,分析了这4款 app 的思维导图后得出的共性和差异点:

共性就是要符合用户使用习惯的地方,如果你调研的3-5个产品都这么做了,很可能这里是产生用户习惯的地方,是我们需要去遵循的,这是获得用户好感度的基础。
分析产品时你一定也会得出一些产品差异的地方,而这些差异就是你的产品竞争点,也是别人用你的 app 不用其他 app 的理由。比如人脉软件都会有社交相关的功能,但是脉脉会比较注重职场招聘、直播等互联网职场人比较关心的点,这样对应的用户群体就比较会吃你这套,会提升用户的粘性。
相信你在梳理了竞品的信息架构,总结了共性和差异点之后对产品的信息架构已经有一个比较清晰的认知了,在做自己产品信息架构的时候也会更胸有成竹。但是最后还有一件事我们可以做,就是对我们的要做的产品功能做卡片分类。

卡片分类法是我们工作中常用到的一种方法,它可以在用户侧再一次印证和检测我们的产品信息架构。
卡片分类法就是让用户对功能卡片进行分类,组织,并给相关功能的集合重新定义名称的一种自下而上的整理方法。
说直白点就是准备一堆卡片,在这些卡片上写上你所需要包含的功能名称,然后给到用户侧,让用户进行分类,让用户进行组织,来了解用户到底觉得这些功能应该怎么合并怎么归类的一种方法。它可以帮助你站在用户角度去了解用户是怎么认定这些功能的,也可以在卡片分类法的过程中更加了解用户是怎么想的。
卡片分类法大概的步骤和注意点是这样的:

卡片分类法最终会产出这样的一个树形图:

其实到这一步信息架构大概的雏形已经有了,你可以用 axure 或者类似 mindnode 的软件把信息架构梳理出来。
接下来你要对信息架构进行重要性分级,这样在产品开发的前期可以帮助梳理产品研发的优先级,集中精力解决用户的最大痛点。在产出页面时也可以更好的把控页面元素的大小层级,位置关系等。

最后你需要注意层和度的平衡:层一般不超过5层,超过操作困难。度过多会让用户认知成本增加,容易找不到想找的内容。这里的度指的是同一页面展示的信息量。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务。
如果您想订阅本博客内容,每天自动发到您的邮箱中, 请点这里
1、简介
retrofit是一个封装okhttp请求的网络请求库,可以通过Rxjava适配返回信息。
我们通过Retrofit.Builder建造者模式创建一个Retrofit实例对象
public static final class Builder {
/**
*Android线程切换的类
*/
private final Platform platform;
private @Nullable okhttp3.Call.Factory callFactory;
private HttpUrl baseUrl;
private final List<Converter.Factory> converterFactories = new ArrayList<>();
private final List<CallAdapter.Factory> callAdapterFactories = new ArrayList<>();
private @Nullable Executor callbackExecutor;
private boolean validateEagerly;
Builder(Platform platform) {
this.platform = platform;
}
public Builder() {
this(Platform.get());
}
Builder(Retrofit retrofit) {
platform = Platform.get();
callFactory = retrofit.callFactory;
baseUrl = retrofit.baseUrl;
converterFactories.addAll(retrofit.converterFactories);
// Remove the default BuiltInConverters instance added by build().
converterFactories.remove(0);
callAdapterFactories.addAll(retrofit.callAdapterFactories);
// Remove the default, platform-aware call adapter added by build().
callAdapterFactories.remove(callAdapterFactories.size() - 1);
callbackExecutor = retrofit.callbackExecutor;
validateEagerly = retrofit.validateEagerly;
}
public Builder client(OkHttpClient client) {
return callFactory(checkNotNull(client, "client == null"));
}
public Builder callFactory(okhttp3.Call.Factory factory) {
this.callFactory = checkNotNull(factory, "factory == null");
return this;
}
public Builder baseUrl(String baseUrl) {
checkNotNull(baseUrl, "baseUrl == null");
HttpUrl httpUrl = HttpUrl.parse(baseUrl);
if (httpUrl == null) {
throw new IllegalArgumentException("Illegal URL: " + baseUrl);
}
return baseUrl(httpUrl);
}
public Builder baseUrl(HttpUrl baseUrl) {
checkNotNull(baseUrl, "baseUrl == null");
List<String> pathSegments = baseUrl.pathSegments();
if (!"".equals(pathSegments.get(pathSegments.size() - 1))) {
throw new IllegalArgumentException("baseUrl must end in /: " + baseUrl);
}
this.baseUrl = baseUrl;
return this;
}
public Builder addConverterFactory(Converter.Factory factory) {
converterFactories.add(checkNotNull(factory, "factory == null"));
return this;
}
public Builder addCallAdapterFactory(CallAdapter.Factory factory) {
callAdapterFactories.add(checkNotNull(factory, "factory == null"));
return this;
}
public Builder callbackExecutor(Executor executor) {
this.callbackExecutor = checkNotNull(executor, "executor == null");
return this;
}
public List<CallAdapter.Factory> callAdapterFactories() {
return this.callAdapterFactories;
}
public List<Converter.Factory> converterFactories() {
return this.converterFactories;
}
public Builder validateEagerly(boolean validateEagerly) {
this.validateEagerly = validateEagerly;
return this;
}
public Retrofit build() {
if (baseUrl == null) {
throw new IllegalStateException("Base URL required.");
}
okhttp3.Call.Factory callFactory = this.callFactory;
if (callFactory == null) {
callFactory = new OkHttpClient();
}
Executor callbackExecutor = this.callbackExecutor;
if (callbackExecutor == null) {
callbackExecutor = platform.defaultCallbackExecutor();
}
// Make a defensive copy of the adapters and add the default Call adapter.
List<CallAdapter.Factory> callAdapterFactories = new ArrayList<>(this.callAdapterFactories);
callAdapterFactories.add(platform.defaultCallAdapterFactory(callbackExecutor));
// Make a defensive copy of the converters.
List<Converter.Factory> converterFactories =
new ArrayList<>(1 + this.converterFactories.size());
// Add the built-in converter factory first. This prevents overriding its behavior but also
// ensures correct behavior when using converters that consume all types.
converterFactories.add(new BuiltInConverters());
converterFactories.addAll(this.converterFactories);
return new Retrofit(callFactory, baseUrl, unmodifiableList(converterFactories),
unmodifiableList(callAdapterFactories), callbackExecutor, validateEagerly);
}
}
通过Retrofit.Builder中build方法创建一个Retrofit实例对象,在创建Retrofit时会判断用户创建OkhttpClient对象,没有创建Retrofit会创建一个默认okhttpClient对象,然后设置Platform中的主线程线程池,设置线程池处理器交给主线程Looper对象。然后创建一个Retrofit对象。我们通过Retrofit.create创建一个接口代理类
public <T> T create(final Class<T> service) {
Utils.validateServiceInterface(service);
if (validateEagerly) {
eagerlyValidateMethods(service);
}
return (T) Proxy.newProxyInstance(service.getClassLoader(), new Class<?>[] { service },
new InvocationHandler() {
private final Platform platform = Platform.get();
@Override public Object invoke(Object proxy, Method method, @Nullable Object[] args)
throws Throwable {
// If the method is a method from Object then defer to normal invocation.
if (method.getDeclaringClass() == Object.class) {
return method.invoke(this, args);
}
if (platform.isDefaultMethod(method)) {
return platform.invokeDefaultMethod(method, service, proxy, args);
}
ServiceMethod<Object, Object> serviceMethod =
(ServiceMethod<Object, Object>) loadServiceMethod(method);
OkHttpCall<Object> okHttpCall = new OkHttpCall<>(serviceMethod, args);
return serviceMethod.adapt(okHttpCall);
}
});
}
在调用Creater方法时,通过代理类创建Service实例对象,当我们通过接口实例对象调用方法时,通过invoke方法时,通过Method创建一个ServiceMethod对象,然后把ServiceMethod存储起来
public ServiceMethod build() {
callAdapter = createCallAdapter();
responseType = callAdapter.responseType();
if (responseType == Response.class || responseType == okhttp3.Response.class) {
throw methodError("'"
+ Utils.getRawType(responseType).getName()
+ "' is not a valid response body type. Did you mean ResponseBody?");
}
responseConverter = createResponseConverter();
for (Annotation annotation : methodAnnotations) {
parseMethodAnnotation(annotation);
}
if (httpMethod == null) {
throw methodError("HTTP method annotation is required (e.g., @GET, @POST, etc.).");
}
if (!hasBody) {
if (isMultipart) {
throw methodError(
"Multipart can only be specified on HTTP methods with request body (e.g., @POST).");
}
if (isFormEncoded) {
throw methodError("FormUrlEncoded can only be specified on HTTP methods with "
+ "request body (e.g., @POST).");
}
}
int parameterCount = parameterAnnotationsArray.length;
parameterHandlers = new ParameterHandler<?>[parameterCount];
for (int p = 0; p < parameterCount; p++) {
Type parameterType = parameterTypes[p];
if (Utils.hasUnresolvableType(parameterType)) {
throw parameterError(p, "Parameter type must not include a type variable or wildcard: %s",
parameterType);
}
Annotation[] parameterAnnotations = parameterAnnotationsArray[p];
if (parameterAnnotations == null) {
throw parameterError(p, "No Retrofit annotation found.");
}
parameterHandlers[p] = parseParameter(p, parameterType, parameterAnnotations);
}
if (relativeUrl == null && !gotUrl) {
throw methodError("Missing either @%s URL or @Url parameter.", httpMethod);
}
if (!isFormEncoded && !isMultipart && !hasBody && gotBody) {
throw methodError("Non-body HTTP method cannot contain @Body.");
}
if (isFormEncoded && !gotField) {
throw methodError("Form-encoded method must contain at least one @Field.");
}
if (isMultipart && !gotPart) {
throw methodError("Multipart method must contain at least one @Part.");
}
return new ServiceMethod<>(this);
}
private CallAdapter<T, R> createCallAdapter() {
/**
*获取方法返回值类型
*/
Type returnType = method.getGenericReturnType();
if (Utils.hasUnresolvableType(returnType)) {
throw methodError(
"Method return type must not include a type variable or wildcard: %s", returnType);
}
if (returnType == void.class) {
throw methodError("Service methods cannot return void.");
}
//获取注解信息
Annotation[] annotations = method.getAnnotations();
try {
//noinspection unchecked
return (CallAdapter<T, R>) retrofit.callAdapter(returnType, annotations);
} catch (RuntimeException e) { // Wide exception range because factories are user code.
throw methodError(e, "Unable to create call adapter for %s", returnType);
}
}
在创建ServiceMethod时,获取我们okhttp请求是否有返回值,没有返回值抛出异常,然后获取注解信息,然后获取retrofit中CallAdapter.Factory,然后调用get方法,我们在通过rxjavaFactoryAdapter.create创建的就是实现CallAdapter.Factory对象,然后调用CallAdapter.Factory中respenseType方法,然后通过我们传递converter对数据进行序列化,可以通过gson和fastjson进行实例化对象,然后通过parseMethodAnnomation解析请求类型
private void parseHttpMethodAndPath(String httpMethod, String value, boolean hasBody) {
if (this.httpMethod != null) {
throw methodError("Only one HTTP method is allowed. Found: %s and %s.",
this.httpMethod, httpMethod);
}
this.httpMethod = httpMethod;
this.hasBody = hasBody;
if (value.isEmpty()) {
return;
}
// Get the relative URL path and existing query string, if present.
int question = value.indexOf('?');
if (question != -1 && question < value.length() - 1) {
// Ensure the query string does not have any named parameters.
String queryParams = value.substring(question + 1);
Matcher queryParamMatcher = PARAM_URL_REGEX.matcher(queryParams);
if (queryParamMatcher.find()) {
throw methodError("URL query string \"%s\" must not have replace block. "
+ "For dynamic query parameters use @Query.", queryParams);
}
}
this.relativeUrl = value;
this.relativeUrlParamNames = parsePathParameters(value);
}
通过注解类型获取到请求类型时,通过调用相关方法解析获取到请求url,然后通过注解获取方法中是否有注解字段,有注解信息存储到Set集合中。然后创建一个OkhttpCall对象,通过调用serviceMethod.adapt方法做网络请求,serviceMethod.adapt调用是callAdapter中的adapt方法,如果用户没有设置callAdapter模式使用的是ExecutorCallAdapterFactory中的adapt方法
public CallAdapter<?, ?> get(Type returnType, Annotation[] annotations, Retrofit retrofit) {
if (getRawType(returnType) != Call.class) {
return null;
} else {
final Type responseType = Utils.getCallResponseType(returnType);
return new CallAdapter<Object, Call<?>>() {
public Type responseType() {
return responseType;
}
public Call<Object> adapt(Call<Object> call) {
return new ExecutorCallAdapterFactory.ExecutorCallbackCall(ExecutorCallAdapterFactory.this.callbackExecutor, call);
}
};
}
}
在ExectorCallAdapterFactory中调用组装的Call方法中enqueue方法调用异步网络请求,成功后通过Platform中MainThreadExecutor切换到主线程。在调用callback中的enqueue,onResponse和onFairlure方法时实际是调用到OkhttpCall方法的onResponse方法,在OkHttpCall.enqueue中重新组建OkHttp.Call url和参数信息,然后封装请求,请求成功后通过parseResponse解析返回信息状态,然后把返回信息状态成ResponseBody对象,调用ServiceMethod.toResponse解析,在toResponse中实际是我们设置ConverterFactory对象解析数据,完成后调用callBack中onSuccess方法。
@Override public void enqueue(final Callback<T> callback) {
checkNotNull(callback, "callback == null");
okhttp3.Call call;
Throwable failure;
synchronized (this) {
if (executed) throw new IllegalStateException("Already executed.");
executed = true;
call = rawCall;
failure = creationFailure;
if (call == null && failure == null) {
try {
call = rawCall = createRawCall();
} catch (Throwable t) {
throwIfFatal(t);
failure = creationFailure = t;
}
}
}
if (failure != null) {
callback.onFailure(this, failure);
return;
}
if (canceled) {
call.cancel();
}
call.enqueue(new okhttp3.Callback() {
@Override public void onResponse(okhttp3.Call call, okhttp3.Response rawResponse) {
Response<T> response;
try {
response = parseResponse(rawResponse);
} catch (Throwable e) {
callFailure(e);
return;
}
try {
callback.onResponse(OkHttpCall.this, response);
} catch (Throwable t) {
t.printStackTrace();
}
}
@Override public void onFailure(okhttp3.Call call, IOException e) {
callFailure(e);
}
private void callFailure(Throwable e) {
try {
callback.onFailure(OkHttpCall.this, e);
} catch (Throwable t) {
t.printStackTrace();
}
}
});
}如果您想订阅本博客内容,每天自动发到您的邮箱中, 请点这里
图片三个网站的图片搜索结果进行爬取和下载。
首先通过爬虫过程中遇到的问题,总结如下:
1、一次页面加载的图片数量各个网站是不定的,每翻一页就会刷新一次,对于数据量大的爬虫几乎都需要用到翻页功能,有如下两种方式:
1)通过网站上的网址进行刷新,例如必应图片:
url = 'http://cn.bing.com/images/async?q={0}&first={1}&count=35&relp=35&lostate=r
&mmasync=1&dgState=x*175_y*848_h*199_c*1_i*106_r*0'
2)通过selenium来实现模拟鼠标操作来进行翻页,这一点会在Google图片爬取的时候进行讲解。
2、每个网站应用的图片加载技术都不一样,对于静态加载的网站爬取图片非常容易,因为每张图片的url都直接显示在网页源码中,找到每张图片对应的url即可使用urlretrieve()进行下载。然而对于动态加载的网站就比较复杂,需要具体问题具体分析,例如google图片每次就会加载35张图片(只能得到35张图片的url),当滚动一次后网页并不刷新但是会再次加载一批图片,与前面加载完成的都一起显示在网页源码中。对于动态加载的网站我推荐使用selenium库来爬取。
对于爬取图片的流程基本如下(对于可以通过网址实现翻页或者无需翻页的网站):
1. 找到你需要爬取图片的网站。(以必应为例)
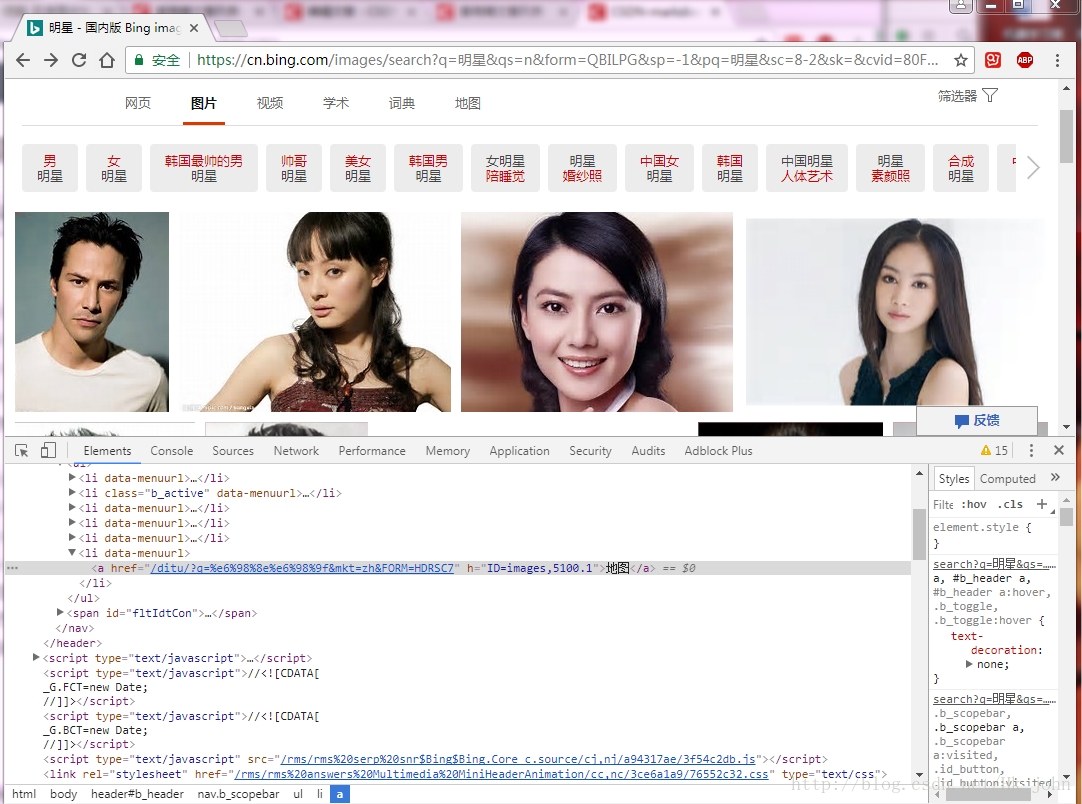
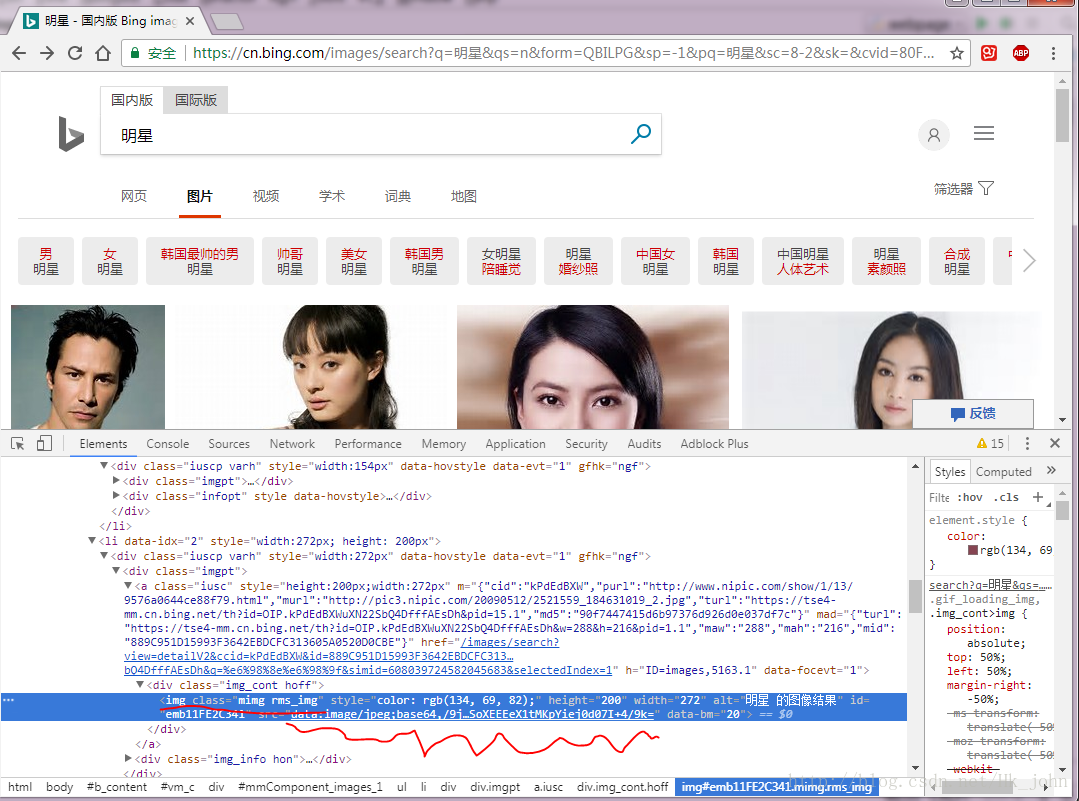
2. 使用google元素检查(其他的没用过不做介绍)来查看网页源码。
3. 使用左上角的元素检查来找到对应图片的代码。
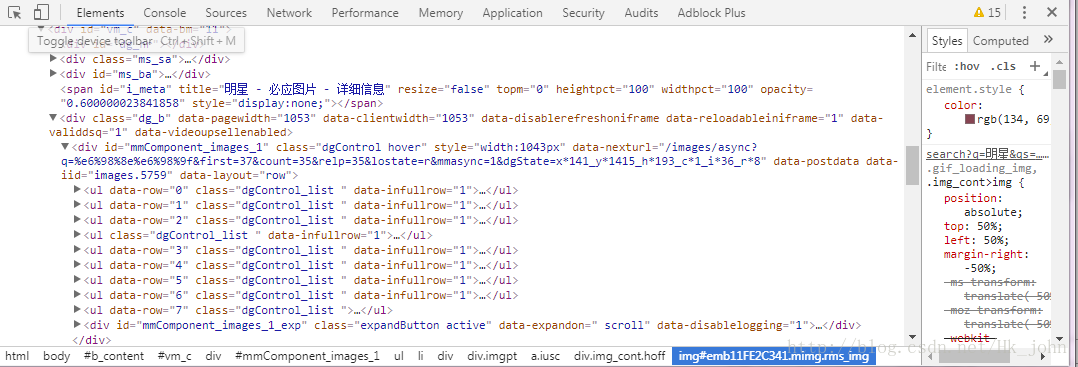
4. 通过观察找到翻页的规律(有些网站的动态加载是完全看不出来的,这种方法不推荐)
从图中可以看到标签div,class=’dgControl hover’中的data-nexturl的内容随着我们滚动页面翻页first会一直改变,q=二进制码即我们关键字的二进制表示形式。加上前缀之后由此我们才得到了我们要用的url。
5. 我们将网页的源码放进BeautifulSoup中,代码如下:
url = 'http://cn.bing.com/images/async?q={0}&first={1}&count=35&relp=35&lostate=r&mmasync=1&dgState=x*175_y*848_h*199_c*1_i*106_r*0' agent = {'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.165063 Safari/537.36 AppEngine-Google."}
page1 = urllib.request.Request(url.format(InputData, i*35+1), headers=agent)
page = urllib.request.urlopen(page1)
soup = BeautifulSoup(page.read(), 'html.parser')
我们得到的soup是一个class ‘bs4.BeautifulSoup’对象,可以直接对其进行操作,具体内容自行查找。
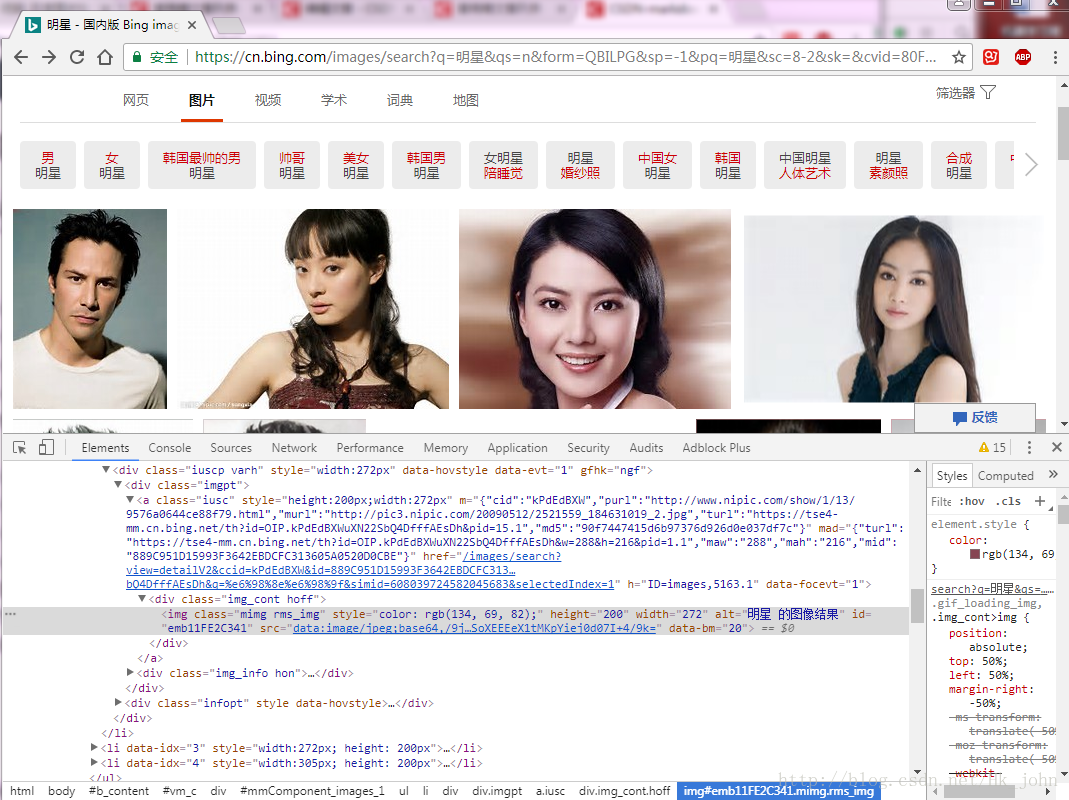
首先选取我们需要的url所在的class,如下图:
波浪线是我们需要的url。
我们由下面的代码得到我们需要的url:
if not os.path.exists("./" + word):#创建文件夹 os.mkdir('./' + word) for StepOne in soup.select('.mimg'):
link=StepOne.attrs['src']#将得到的<class 'bs4.element.Tag'>转化为字典形式并取src对应的value。 count = len(os.listdir('./' + word)) + 1 SaveImage(link,word,count)#调用函数保存得到的图片。
最后调用urlretrieve()函数下载我们得到的图片url,代码如下:
try:
time.sleep(0.2)
urllib.request.urlretrieve(link,'./'+InputData+'/'+str(count)+'.jpg') except urllib.error.HTTPError as urllib_err:
print(urllib_err) except Exception as err:
time.sleep(1)
print(err)
print("产生未知错误,放弃保存") else:
print("图+1,已有" + str(count) + "张图")
这里需要强调是像前面的打开网址和现在的下载图片都需要使用try except进行错误测试,否则出错时程序很容易崩溃,大大浪费了数据采集的时间。
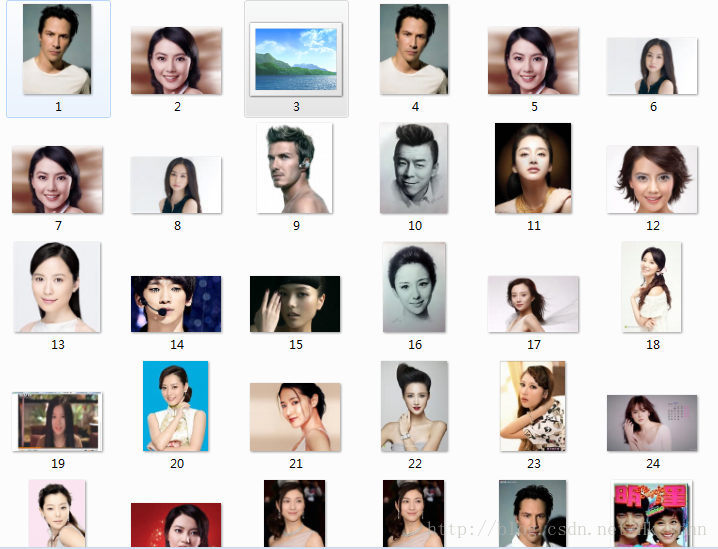
以上就是对单个页面进行数据采集的流程,紧接着改变url中{1}进行翻页操作继续采集下一页。
数据采集结果如下:
有问题请留言。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务。
如果您想订阅本博客内容,每天自动发到您的邮箱中, 请点这里
如何从众多的设计点中找到一个清晰的设计主线呢?只需从3个方面切入。小明的设计故事:身为设计师的小明,刚刚遇到下发的设计需求,看了半天需求,无从下手。于是疯狂寻找竞品去借鉴,去素材网站寻找素材拼凑。
如果在设计工作中遇到与小明相同的情况:没有设计头绪,大脑一片空白,画着不一定能过审的草稿时,请继续阅读下面的文章,希望大家能从作者的设计总结中有所启发。
目录:
什么是设计点?
设计点是设计师通过设计手段介入设计任务的一个节点,比如:设计目标 、设计风格 、用户行为 、用户情绪 、信息表达等都是设计的切入点,设计点能够影响设计的风格走向和设计师的创作思路。

那如何从众多的设计点中找到一个清晰的设计主线呢?只需从3个方面切入。
下图是阿里巴巴UED 的设计理论,同程序员提倡的「不造重复的轮子」一样,设计理论也没有必要去反复总结类似的。目前阿里的这个设计理论,很好的支持了包含大型项目到中型项目的各个环节,易于理解,且和我们的工作认知贴近,是一个很好的入门方法。
我们通过定义业务目标和聚焦设计目标,来最终实现设计的产出。

下图是平台营销活动的设计5个要义,其核心也是业务目标。

通过几个的设计方法的展示,我们可以看出,处于上游业务目标的重要性。
只有业务目标和设计目标一致的时候,我们的设计工作才有意义。当我们评判我们的设计结果时,除了设计的数据指标外,能快速判断设计方案比迭代之前更优的指标就是是否符合业务目标,是否更贴近用户的诉求。
1. 切入模型

根据工具模型我们从业务目标出发,去定义设计目标从而得出设计方向。
2. 明确业务诉求

3. 得出业务目标
用分享讲义的策略给用户带来学习交流机会和学习成就感,达到拉新和活跃用户目的。
4. 视觉推导


5. 案例

视觉设计师,尤其是运营设计师一定要具有交互思维,作为全链路设计目标的我们,掌握交互思维,能更好的理解产品文档和规避更多的设计错误,从而准确引导用户操作路径。
方法:了解页面中的功能交互流程,梳理用户操作行为路径,可以对行为步骤中的信息内容进行归类分组提供依据。
切入模型:

常见的方法有:情感化、原子化、组件化、游戏化等等。
方法:分解设计需求,归纳设计模块,运用已知的设计类型进行视觉化设计。

1. 提取仪式感设计点-晒成绩项目
仪式感的作用:通过用户在体验过程中由产品功能实现—交互操作—体验心理变化建立,形成对价值观的建立,是给用户带来更高层次的享受。
从四个层面理解仪式感:权威感、尊重存在感、期待感、荣誉感的意义。通过分解设计内容来发现机会点,插入仪式感设计方法。

视觉推导:

案例:

2. 提取情感化设计点

情感化设计3要素:

案例:



3. 提取游戏化设计点
将游戏机制运用于非游戏场景。比如:要想鼓励用户多参与交互,你可以在 APP 加入「挑战」这类的游戏元素,用户可以参与挑战,通过连续抽奖,并获得相应奖赏,从而达到预期目的。

案例:

寻找设计点就是拆解与分析的过程。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务。
如果您想订阅本博客内容,每天自动发到您的邮箱中, 请点这里
专注于做好一件小事,哪怕是做不好也用心去做,小到搭建一个精美的网格系统,做好一个字体的拐角……先看一下我的往期设计案例。

对于很多刚接触字体设计的同学经常会遇到一种情况那就是想法高大上,结果很悲伤,为什么会造成这样的结果?归根结底是对字体设计本身了解还不够细致就照葫芦画瓢直接上,为了避免这种尴尬的结果,我们应该在开始着手做字体之前要做好各项准备工作,不断去浏览优秀的字体设计从中寻找设计的感觉,确定感觉后建立网格系统,开始逐步设计字体。我在做字体设计的时候会把握几个步骤「建网格」——「选字体」——「拆字体」——「绘笔画」——「绑骨架」——「粗与细」——「取与舍」——「磨细节」——「去感受」。
下面我们就以大家最常见的矩阵字体为例来给大家分享如何制作字体。
1. 建网格
建立网格系统,万丈高楼平地起,要做一款扎实的字体离不开网格系统的规范。

2. 拆字体
以「燃」为例——选取一个默认字体,按照字体结构对笔画进行拆分。

3. 绘笔画
将拆分出的笔画用横线和竖线在网格系统里进行笔画重绘,此时不要做细节,撇、捺和点根据自身走向和结构特点也归属为横竖线。

4. 绑骨架
拆分绘制的字体笔画就是字体的骨骼,笔画间的连接处可以理解成是人体的关节,关节的意义在于保证字体稳固的同时又灵活多变,字体的笔画可以根据视觉需要围绕关节在一定范围内做活动,也可调整长短比例。

5. 粗与细
笔画的粗细与硬度由你想要的字体气质来决定,细笔画与曲笔画柔美气质,粗笔画与直笔画沉稳大气,虽说设计是一种感觉,但是这种感觉对于初学者来说很难把控,所以跟大家共享一下常用的几种笔画的粗细,在1000PX*1000PX画板里采用6px,10px和20px为基础笔画粗细,根据想要的业务气质选取即可。

6. 解与构
常见的字体结构有「上下结构」「上中下结构」「左右结构」「左中右结构」「半包围结构」和「全包围结构」。其中「上下结构」中着重强调占比较小的那部分笔画,进而达到字体本身的平衡,例如「感」字着重设计心字;「上中下结构」中一般会在不影响识别性的前提下去掉中间部分横行笔画,进而达到字体本身的平衡,例如「享」字着重设计口字;左中右结构中在不影响识别性的前提下会简化左边部分笔画,进而达到字体本身的平衡,例如「燃」字着重设计火字。

7. 取与舍
笔画变粗后整个字体笔画间的空间比例会受到一定影响,因此为了字体的美观度和透气性我们会对字体结构进行一些取舍和整合。

8. 磨细节
为了让字体看起来更加舒适,我们将字体的拐角做圆,做圆角的同时也要根据网格系统来调整圆的度数。

9. 去感受
打磨整体字体,继续刻画细节。

注意:在一组字里,每个单字的结构都存在差异,适当调整字体内部的比例,形成感官上舒适的笔势,对保持视觉上大小一致很重要。汉字字体类型繁多,但是如果我们用几何法则来划分字体类型其实大致可以归纳为三种:方形,圆形和三角形,从面积上来看方形和圆形的面积最大,三角形次之,所以我们为了保持字重大小的一致性需要调整他们之间的大小比例,做到大小均匀,笔画一致,结构严谨和间隙适中。

△ 图源:ElethomHunter
为了拉出字体的气质,一般会把字体做的稍微偏瘦长一些。

字体设计的手段是多种多样的,每个设计师都有自己擅长的切入点,最后的结果是自己想要的就好。上述的分享希望能给字体设计初学者一点帮助,也欢迎各位同行大神交流切磋。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务。
蓝蓝设计的小编 http://www.lanlanwork.com