

如果您想订阅本博客内容,每天自动发到您的邮箱中, 请点这里
出于安全考虑,浏览器有一个同源策略。浏览器中,异步请求的地址与目标地址的协议、域名和端口号三者与当前有不同,就属于跨域请求。
限制跨域访问是浏览器的一个安全策略,因为如果没有这个策略,那么就有被跨站攻击的危险。比如,攻击者在自己的网站A放置一个表单,这个表单发起DELETE请求,删除某个用户在B网站上的个人资料。如果没有同源策略保护,那么在同一个浏览器内,如果用户已经登录了B网站,这个删除的请求就会被接受,导致在用户不知情的情况下自己在B网站中的资料被删除。
浏览器的同源策略提升了安全性,但是给需要在不同域名下开发的开发者带来了跨域问题。
解决跨域的问题主要有:
jsonp和cors。jsonp是利用 script 标签可以跨域加载的特性而创造出来的一种非正式的跨域解决方案。在实际开发中,推荐使用cors,即在服务端返回时加入允许跨域的请求头,允许指定域名的跨域访问。
千万要小心!这种直接加 * 号的做法是相当危险的,千万别这么做!
response.addHeader("Access-Control-Allow-Origin", "*");
正确的做法:
/**
* 使用Filter的方式解决跨域问题
*/ public class CorsFilter implements Filter { private static final List<String> ALLOW_ORIGINS = Config.getListString("allowOrigins", ","); private static final String REQUEST_OPTIONS = "OPTIONS"; @Override public void init(FilterConfig filterConfig) throws ServletException {
} @Override public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) servletRequest;
HttpServletResponse response = (HttpServletResponse) servletResponse;
String orgHeader = request.getHeader(HttpHeaders.ORIGIN); if (orgHeader != null && ALLOW_ORIGINS.contains(orgHeader)) { // 允许的跨域的域名 response.addHeader("Access-Control-Allow-Origin", orgHeader); // 允许携带 cookies 等认证信息 response.addHeader("Access-Control-Allow-Credentials", "true"); // 允许跨域的方法 response.addHeader("Access-Control-Allow-Methods", "POST, GET, OPTIONS, DELETE, PATCH, PUT, HEAD"); // 允许跨域请求携带的请求头 response.addHeader("Access-Control-Allow-Headers", "Content-Type, Content-Length, Authorization, Accept, X-Requested-With"); // 返回结果可以用于缓存的最长时间,单位是秒。-1表示禁用 response.addHeader("Access-Control-Max-Age", "3600"); // 跨域预检请求,直接返回 if (REQUEST_OPTIONS.equalsIgnoreCase(request.getMethod())) { return;
}
}
filterChain.doFilter(request, response);
} @Override public void destroy() {
}
}
<filter> <filter-name>corsfilter</filter-name> <filter-class>com.bj58.crm.plus.filter.CorsFilter</filter-class> </filter> <filter-mapping> <filter-name>corsfilter</filter-name> <url-pattern>/*</url-pattern> <dispatcher>REQUEST</dispatcher> </filter-mapping>
http-util.js
let axios = require("axios"); let qs = require("qs");
axios.defaults.withCredentials = true;
axios.defaults.headers.post["Content-Type"] = "application/x-www-form-urlencoded"; function post(url, param) { return axios.post(url, qs.stringify(param))
} function get(url, param) { axios.get(url, {params: param})
}
export default {
get,
post
};蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
下图所示线上故障,你的产品线是否曾经中招或者正在中招?同样的问题总是在不同产品线甚至相同产品线不同系统重复上演,这些故障有个共同特点,就是线下常规测试很难发现,即便线上验证也不易暴露。但是总是在“无变更安全日”悄然爆发,严重影响系统稳定性指标。
面对这些看似并无规律的故障,Case by case的分析无疑是低效而且不系统的,无法全面扫除稳定性测试盲区,也无法阻止悲剧在其他产品线再一次发生。为此笔者把问题聚类,根据问题特点寻求通用测试手段,并在产品线各个系统落地验证,效果显著,现把个人经验融合前辈经验产出,供大家参考,有则改之,无则加勉。
首先,为了让大家更好了解这些故障对业务系统稳定性的影响程度,需了解下何为稳定性,衡量指标就是系统可用性= MTBF / (MTBF + MTTR) , 其中MTBF, Mean Time Between Failure, 是平均无故障时间, 而MTTR, Mean Time To Repair,是平均修复时间,参考下表更加直观。

从如上数字看,5个9的故障时间月故障时间只有25s,3个9的可用性月故障时间也只有40多分钟,回想我们平时处理过的线上问题,开发和测试质量把控不过关,然后再把期望寄托在半人肉处理故障的运维团队,显然无法达到线上产品稳定性要求。
为了保障系统稳定性,提前消除风险势在必行。产品质量风险类型很多,产品研发流程的各个阶段都可能引入和存在风险,每个阶段的风险的类型和发现手段都不尽相同,为此产出如下风险模型。按照风险发生的阶段及原因,风险类型可分为:架构设计风险、编码风险、安全风险、流程规范风险、运维风险和监控风险。
本文主要讲解架构设计风险,接下来介绍的每个风险都会说明风险定义,影响,以及通过什么技术手段来进行风险识别,最后总结风险消除方案。另外每个风险都会有具体的例子来讲解,这些例子都是发生在百度内部的真实故事。
架构设计风险是QA最容易忽略的,该类风险出现在研发阶段的早期,我们都知道缺陷越早的暴露后期研发的维护成本越低,而且一旦架构设计上出现了问题,影响面是涉及整个模块甚至系统的,修复代价必然非常高,因此对于架构设计的风险更要提前了解和避免。
根据既往经验,架构设计风险大概可以分为以下几个维度:交互、依赖、耦合。
交互类常见风险:重复交互、高频交互、冗余/无用交互、接口不可重用、超时重试设置不合理、IP直连、跨机房等。
依赖类常见风险:不合理强弱依赖、无效依赖、忽略第三方依赖、缓存依赖失效等。
耦合类常见风险:架构耦合不合理、缓存耦合不合理等。
2、风险影响
重复交互增加接口耗时,降低接口性能,当重复的是跨机房交互会使得性能急剧下降影响系统稳定性,增加对下游服务的压力(模块压力增加一倍,下游服务压力增加几倍)。
3、风险识别
如果两个交互具有完全相同的请求服务对象(尤其是mysql、redis、memcache这类数据存储服务)、请求数据、返回数据,那么这两个交互就判定为重复交互;对于获取不到交互数据时也可以通过数据包size进行初判。这里可以借助开源trace系统,采集业务测试时的调用链信息,根据上面的判断规则进行风险自动识别。
4、风险消除
在对实时性要求可控的前提下,将第一次查询信息缓存下来。
真实案例一:系统间重复交互。11次重复请求session,对于前端一次请求就要对session模块产生几十倍的流量冲击,所有这些交互都是完全重复的,极大的降低的了接口性能和session的负载能力。
真实案例二:mysql/redis重复交互。mysql/redis作为系统中性能瓶颈,这样的重复请求无疑加速了其性能瓶颈的到达。
1、风险定义
一次用户发起的请求,如果在模块之间的交互次数完全依赖于后端返回的数据条数,会给下游造成极大压力的同时,也降低了系统的稳定性。相同业务请求的模块交互次数多少不一,原因通常是代码中循环操作内部存在网络交互,总交互次数受到循环迭代的次数影响。这样的情况在模块上线初期,可能因为数据量比较小、pv比较小很容易被人忽视,当某天上线一些大数据、大客户,将会给予致命一击。
2、风险影响
循环请求次数过多会导致下游压力倍增(前端pv增加一倍,后端pv增加几十倍),接口性能不稳定,降低系统处理能力。系统稳定性完全依赖于数据的代码逻辑非常脆弱,当遇到某一个大数据时将会出现模块假死、系统雪崩、功能失败。
3、风险识别
基于上游传来的数据或某个子请求返回的数据量(通常是一个数组),针对每个数组元素进行网络请求,遍历并没有错,但是要对这个遍历的数组元素个数有限制,否则循环遍历的次数就完全依赖于数据。这里也可以借助开源trace系统,采集业务测试时的调用链信息,根据上面的判断规则进行风险自动识别。
4、风险消除
数据量要可控,结合产品业务需求,比如请求返回结果要有上限;批量请求替代逐个请求。
真实案例:查询某商户物料详情,当该商户拥有大量物料,就出现了如下场景,用户的一次查询就造成服务与db之间156次交互,那该接口的性能就可想而知了,平均耗时都在3s+,用户体验极差。
1、风险定义
交互依赖的数据已出现异常,还继续执行后续交互,使得后续的交互是没有任何意义的冗余交互。这些依赖的数据,可能是上游传递而来,也可能是与下游模块请求得来。
2、风险影响
冗余交互会占用系统资源,降低接口性能,从而影响系统稳定性和性能。
3、风险识别
如果交互A依赖数据B(比如交互A的请求数据中需要传入B),在B异常(比如数据为空、null、false等)情况下,还是发生了交互A,那么就认为A是冗余交互;如果操作A依赖于操作B的成功执行,当B异常时,还是发生了操作A,那么A也认为是冗余交互。可以借助开源trace系统,采集业务测试时的调用链信息,根据上面的判断规则进行风险自动识别。
4、风险消除
代码中增加异常逻辑判断:当交互依赖的数据异常时不进行该交互。
真实案例:如下调用链正常场景是先查询团单list,然后用团单list去查询每个团单的优惠。但是当查询团单列表为空时,就没有必要再调用marketing查询团单的优惠信息了,应该立即返回错误码。这里增加无效交互无疑降低了接口性能。
1、风险定义
相同请求发给模块再次处理,不能保证结果一致,符合预期。
2、风险识别
相同请求,模块返回结果不一致亦或重复写操作产生脏数据。这里可以利用录制工具,重放请求,验证结果正确性。
3、风险消除
对于防重入可总结三点,前端加入防重复点击设置,接口层加入锁机制,db层需要加入唯一键设置。
真实案例
在商家会员卡充值购买的流程中,nmq故障情况下,购买结果页显示充值失败,但是卡中余额却一直在直线增加,原因是充值接口没有做到可重入,这个case幸好在线下及时发现,否则后果不堪设想。
商家会员卡涉及到的购买流程如右下图所示:
用户提交订单并且钱包处理完成后,钱包回调交易模块的payresult接口,交易模块验证通过之后,会调用商家会员卡的rechargemoney接口给商家会员卡充值。为了提高充值接口的可用性,与交易模块有个约定了一个机制:若调用rechargemoney返回的errno不为0 ,则投入nmq重试三分钟,三分钟之内的重试均没有成功,才触发自动退款。商家会员卡模块的充值接口rechargemoney的流程图如下图所示:
在rechargemoney接口处理过程中,有一个防频繁重入的判定redis锁过程,expireTime设置时间为10s,10s内会拦截过来的重复请求,直接返回。
上述过程可以看到,前端是有无限重试策略的,因此可以认为前端无防重入,那么看接口层锁机制,重试时间3min明显大于锁有效时间10s,因此相同请求10s后锁机制也失效,再看db层,插入order_id和其他营销信息,数据库中并没有设置order_id为唯一键,因此该接口彻底失守,没有做到可重入,相同订单可以重复插入成功,从而导致业务表现为同一订单多次重复充值。
对于该案例,改进方案是首先将锁有效时间设置大于一切来源的重试时间,其次在db充值记录表中将orderid设置为主键,双重保护该接口做到可重入。
1、风险定义
顾名思义,就是超时并没有根据系统真实表现科学的设置。
2、风险影响
就像下图化学反应一样,不合理的超时实际设置并不会产生真正影响,但是遇到网络故障,依赖超时时,后果不堪设想。
模块交互必设超时,这是基本要求,但是超时设置过长、过短可能会适得其反。不合理超时设置主要表现为①交互超时时间设置过长,比如5s甚至10s的超时②下游超时时间大于上游超时时间。
交互超时重试时间过长,在下游偶尔出现网络抖动时连接被hang住,接口耗时增加,并且降级模块处理能力。下游超时>上游超时,上游超时后断开连接引发重试,下游还在继续上次运算(此时已经没有意义),下游负载增加N倍(取决于重试次数设置和发生重试的层数),使得系统性能急剧下降甚至雪崩。
3、风险识别
①超时时间设置过长(比如数据库connect超时1s,模块读写超时5s)
②下游超时时间大于上游超时时间。
4、风险消除
从系统整体考虑,并且结合重试和本模块计算时间的影响。下游超时<上游超时;超时时间不宜过长,根据下游接口性能设置;对于弱依赖的服务交互,超时时间更不能过长,以免弱依赖阻塞主流程。
真实案例:如下图,该接口调用redis超时时间超过2s,然而Redis性能极好,单线程阻塞性server,这种长耗时会阻塞其他请求,很容易引起系统雪崩,应该把redis连接超时时间修改适当小。
1、风险定义
顾名思义,就是重试并没有根据系统真实表现科学的设置。
2、风险影响
任何网络交互都可能失败,为了保证最终交互成功,通常交互失败/超时、数据错误后再次与该模块交互,即发生了重试。重试的次数设置不当,轻者交互成功率不达标,业务失败率增高,严重者引发系统雪崩。
3、风险识别
查看框架配置文件中重试次数配置,是否简单粗暴的经验值设定重试次数,比如一律重试3次,查看代码中逻辑控制的重试限制(这种很隐蔽)。
4、风险消除
相对于固定的重试序列,随机重试序列也可能给系统带来风险,例如可能会降低下游模块的cache命中率,降低系统性能,甚至引起雪崩。
评估重试机制:
1) 真的需要在每一层都努力重试吗?
2) 真的需要这么多次重试吗?
3) 真的需要在连接,写,读这三者失败后都重试吗?
按照业务需求和模块性能设置重试次数
弱依赖不用重试也可以
下游模块性能好,基本不会超时,也可以不重试
大部分情况下,重试次数为1已经足够
真实案例
如图为某产品线的架构,整个系统中,上游模块对下游模块所有的交互,重试次数都是设成3次,交互失败包括连接失败,写失败,读失败这三种情形。如果是写和读失败,那么要关闭当前连接,再重新发起连接。
如果一台bs假死,到该bs的请求会超时。(注意区分模块假死和真死,假死情况下,模块端口打开,能够接收上游连接,但是由于各种原因(如连接队列满,工作线程耗尽,陷入死循环等),不会返回任何应答,上游模块必须等待超时才知道失败,连接超时,写超时和读超时都有可能。而在真死情况下,模块端口关闭,或者干脆程序退出,上游模块连接它会很快得到失败返回码,这个返回码由下游模块的操作系统协议栈返回的,如ECONNREFUSED错误码代表端口不存在,连接被拒绝。)
那么as有1/3的概率需要重试,as重试的过程中,ui可能早就认为as已经超时了,所以ui也开始重试,ui重试的过程中,webserver可能认为ui已经超时了,所以webserver也开始重试……就这样,整个系统的负载急剧增加,到达bs的qps会是平时的27倍,直到系统崩溃为止。
1、风险定义
A,B两个系统交互,B系统分布式部署,A-B连接是通过配置B系统所有IP方式。
2、风险影响
当B系统分布式服务中某一台挂掉时,不能做到failover,导致故障影响扩大。
3、风险消除
通过bns或者组的方式进行连接。
真实案例
某产品线依赖服务redis调用均采用ip列表的方式,如果redis proxy出现单机故障,需要人工介入进行切流量止损。单机发单重启修复周期有时会达小时级别,因此线上服务在故障期间会长时间处于切流量状态,高峰期单机房容量会存在风险。如同时有其他机房服务异常,则无法执行既定预案止损。并且如想下掉故障proxy,只能采用发上线单修改线上配置的方式。止损操作复杂,周期长,效率低下,具体case如下:
(1)用户中心redisproxy单机故障,人工切流量止损,恢复服务花费2小时,期间线上处于切流量状态。
(2)商品中心redis proxy单机故障,会存在扣除库存失败的风险。恢复服务花费半小时,后续又再次发生宕机,发单下掉故障proxy。
如上对应前面讲的故障时间,该服务sla月可用性已不足3个9。
1、风险定义
交互的两个模块分别部署在不同机房。
2、风险影响
跨机房交互由于存在网络延时,严重影响接口性能、请求成功率,极大的降低了系统稳定性。
3、风险识别
①配置错误(ODP框架)ral-service中配置的服务后端IP的Tag不能为空(在ral中,会将Tag为空的也认为是本机房)②上游传入idc错误,Idc是完全匹配,nj和nj02就不相同,因此如果上游传入nj02,当前模块的idc是nj,就会找不到对应的Tag而只能使用default。
4、风险消除
主要关注配置是否合理,由于线上配置很难在线下验证正确性,肉眼排查难免遗漏,因此可通过线上机房流量切换演练验证。
1、风险定义
所谓强依赖就是,请求链路中某个服务失败/结果异常/无结果后,核心逻辑必失败,否则就认为是弱依赖。不合理的强弱依赖有两类,本应该是弱依赖的设置为强依赖,本应该是强依赖的设置为弱依赖。
2、风险影响
系统稳定性取决于调用链中所有依赖稳定性最差的依赖,如果将稳定性较差的服务作为强依赖将严重影响稳定性
3、风险识别
强弱依赖的合理性是需要结合业务判断的,如果业务返回结果不可或缺该依赖,那么就该设置强依赖;如何判断该依赖是否为强依赖可以通过故障模拟验证,如果模拟该依赖异常时导致调用异常,则判断其为强依赖。
4、风险消除
①调整不合理的强弱依赖关系,将业务非强依赖服务降级;②通过系统优化及运维优化等手段提高强依赖的稳定性。③对强依赖结果进行全面校验,保证强依赖故障能够及时被发现。
真实案例
用户下单请求到trade模块,是通过消息队列nmq保证下单后的商户通知功能,通知商户是借助公共服务云推送,这里云推送被实现成了强依赖,也就是当云推送如果失败,返回给本次请求失败。
某次下单高峰期时,云推送出现故障,无法给ios用户推送消息,nmq收到请求失败后,会持续不断的重发,nmq的通道堵塞之后也影响了trade模块向nmq的请求故障不断往上层蔓延,最后用户无法下单。
对于如上案例,工程师最后去掉对云推送强依赖代码,服务才慢慢恢复,但已造成非常大的损失。
1、风险定义
服务启动流程中与该依赖建立了连接,但是整个逻辑处理过程中无需依赖该服务,无任何业务关联性。
2、风险影响
其实该风险是不合理依赖的一个特例,无业务关联性的依赖应该及时去除,否则会影响整体服务稳定性。
3、风险识别
与依赖服务只有一次链接交互,无其他交互,就可以初步判断该依赖为无效依赖,为了准确评估可再结合代码排查。
真实案例
某产品线由于配置管理较乱,有个服务每次启动都会判断多个与业务完全不依赖的服务启动情况,这几个依赖服务处于无人维护状态,非常不稳定,从而导致该服务启动失败率非常高。
1、风险定义
请求的完成,需要依赖产品外的其他服务,都称之为第三方(tp)依赖,按照公司又分为公司外第三方,比如糯米酒店依赖携程服务;公司内第三方,比如passport相对于手百。
2、风险影响
第三方服务的性能,正确性,稳定性直接影响自身服务,尤其是第三方强依赖,当第三方依赖出现异常,很可能导致自身产品受到损失;公司外第三方依赖有些是小型公司,技术和运维能力有限,其服务的性能,正确性、稳定性不是很高。
3、风险识别
第三方依赖的可靠性是不可控的也是我们系统建设中不可避免的,那么只能尽量降低第三方依赖不稳定对自身的影响。
4、风险消除:
尽量避免第三方强依赖;
超时设置,重试设置结合第三方容量,平均响应时间,部署情况;
增加第三方依赖挂掉,假死,接口变更的校验及容错降级处理,从架构和云微商做到各个TP方与自身业务的解耦;
运维上,提高第三方依赖可靠性,使用内网bns,vip请求,且避免跨机房交互。
真实案例
某产品线依赖A,B,C三个tp方数据进行汇总展示,每次都需要调用三方都有结果时再进行聚合,否则认为整个流程失败,而三个tp方稳定性不尽相同,其中B是个小公司,经常出现故障,导致自身服务经常故障。
对此工程师对各个TP方加上了全面校验,当验证故障后自动调用降级操作,去掉该tp依赖。从此服务稳定性大大提升。
1、风险定义
前端请求一个肯定不存在的key,导致每次请求都会请求后端原始数据,使得缓存被“穿透”,当该类请求高并发时,那么后端压力凸显。
2、风险影响
缓存穿透后,每个请求都会到达后端服务,对后端服务压力突增;当缓存穿透的并发较高(尤其是恶意攻击),后端服务很可能被压垮,导致整个系统瘫痪。
3、风险原因
一种可能是对于主从分离系统,缓存失效时间小于主从延迟时间,尤其是跨机房的主从分离,主从延迟在某些时候会达到数秒甚至数十秒,这是如果缓存时间设置过小,就会导致所有缓存读写记过均为失效结果,进而请求后端服务获取新的数据。另一种可能是查询结果为空的情况。
4、风险消除
对于查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存;
对于一定不存在的key进行过滤,把这些key放到一个大的bitmap上;
设计的时候考虑,当缓存失效时,系统服务的情况及应对措施。
1、风险定义
大量缓存同时过期失效,前端请求同时到达后端服务。
2、风险影响
当并发量足够大(比如秒杀,抢购),后端服务很可能被压垮,导致整个系统雪崩。
3、风险识别
缓存设置时间相同,失效周期也相同,导致多个缓存同时失效。
4、风险消除
不同的key,设置不同的过期时间,让缓存失效的时间点尽量散列均匀;
在缓存试下后,通过加锁或者队列来控制读数据库读写缓存的线程数量(比如对某个key只允许一个线程查询和写缓存,其他线程等待);
做二级缓存,A为原始缓存,A2位拷贝缓存,A1失效时,可以访问A2,A1缓存失效设置为较短,A2设置为长期。
真实案例
某产品线监控发现机器A机器的8688端口挂掉了,经追查发现一个广告配置下发的接口(/api/v1/ipid)挂掉了,据统计,前一天23点到当日9点之间,该接口被访问了400万+次,正常来讲,这种广告配置下发的接口一天最多几百个请求量。
经查,客户端有一个零点定时触发策略,零点会同时启动很多服务,平时并发请求会命中缓存,不会造成太大压力,可是当时正赶上缓存时间到期,大量请求将服务接口压死,端口挂掉。
对此临时方案是在接入层nginx配置文件中加入了流量控制机制,用lua脚本来将零点的请求屏蔽掉,长期方案是避免这种缓存集体失效的情况。
1、风险定义
系统架构和设计上存在着耦合,包括模块耦合、接口耦合、消息队列耦合。具体体现在,主次不分的功能在一个模块或者接口中实现,nmq中不同重要性的命令耦合在同一个module中。
2、风险影响
整个系统稳定性<最不稳定的功能稳定性,不重要的功能可能拖垮重要功能
3、风险消除
整体思路就是,重要与不重要拆分,实时与非实时拆分,在线与离线拆分,根本上解决就是架构解耦,但是系统发展到一定阶段再拆分代码成本很高,这里可以通过运维方法控制解耦,具体见如下案例。
真实案例
某产品线的一级服务和二级服务共同依赖一个基础服务,由于二级服务的一个bug拖垮基础服务,从而导致一级服务不可用,对此解决方案是通过运维将不同上游流量分开。
思想同2.1.14这里不再赘述。
本文给出了常见的15种架构设计风险,希望大家能够在实际工作中参考审视自己系统是否也存在同样的风险,尽早消除,提高稳定性!
UCDCHINA上海群友们这两年收集整理的校招面试题,包含目前国内几家顶尖互联网企业。适用于产品及设计岗的各位小伙伴参考学习。如果有任何想法,也欢迎在群里踊跃发言。反正说的不好也不罚钱╮(╯▽╰)╭
阿里的面试题
请系好安全带,有一大波阿里面试题正在向你涌来。。。
报告,我感觉我和阿里的面试题八字不合,可以看看其他公司的面试题吗?
腾讯的面试题
其他公司的面试题
是不是感觉很难?是不是感觉无从下手?多多参与群内讨论,众多大佬给你指点迷津!
好了~最后的压轴面试题来了,大家可以踊跃发表感想。答出来的可以找大佬要棒棒糖当奖励
web前端开发工程是是一个很新的职业,在国内乃至国际上真正开始受到重视的时间不超过五年。web前端开发,是从网页制作演变而来的,名称上有很明显的时代特征。随着人们对用户体验的要求越来越高,前端开发的技术难度越来越大,web前端开发工程师这一职业终于从设计和制作不分的局面中独立出来。
早期的前端其实就是table布局,后来发展到所谓的div+css网站重构,再到现在的让人眼花缭乱的各种各样的新技术,web前端技术发展是非常快速的,因此选择了前端这个行业就意味着不停的学习吧。让我们先看看张克军绘制的前端知识体系结构:
前端开发的核心是HTML+CSS+JavaScript。本质上他们构成了一个MVC框架,即HTML作为信息模型(Model),css控制样式(View),JavaScript负责调度数据和实现某种展现逻辑(Controller)。
HTML
1.标签的分类,
2.标签表示一个元素
3.按性质分类:block-level 和 inline-level
4.按语义分类:
Headings:h1,h2,h3,h4,h5,h6
paragraphs:p
Text formatting:em,strong,sub,del,ins,small
Lists:ul,li,ol,dl,dt,dd
Tables:table,thead,tbody,tr,th,td
Forms and input: form,input,select,textarea
Others:div,span,a,img,<!---->
HTML5:header,footer,article,section
XHTML
XHTML于2000年的1月26日成为W3C标准。W3C将XHTML定义为的HTML版本,XHTML将逐渐取代HTML。XHTML是通过把HTML和XML各自的长处加以结合形成的。XHTML语法规则如下:
属性名和标签名称必须小写
属性值必须加引号
属性不能简写
用ID属性代替name属性
XHTML元素必须被正确地嵌套
XHTML元素必须被关闭
标签语义化
为表达语义而标记文档,而不是为了样式,结构良好的文档可以向浏览器传达尽可能多的语义,不论是浏览器位于掌上电脑还是时髦的桌面图形浏览器。结构良好的文档都能向用户传达可视化的语义即使是在老的浏览器,或是在被用户关闭了CSS的现代浏览器中。同时结构良好的HTML代码也有助于搜索引擎索引你的网站。
不要使用table布局,table是用来表格显示的。
不要到处滥用div标签,div是用来分块用的。
不要使用样式标签,如font,center,big,small,b,i,样式可以用CSS来控制,b和i可以用strong和em来代替。
不要使用换行标签<br />和空格来控制样式,请用CSS。
尽量不要使用内联CSS
CSS
1.css基础知识
层叠和继承
优先级
盒模型
定位
浮动
2.css进阶
css sprite
浏览器兼容性
IE haslayout和block format content
css frameworks
css3
css性能优化
less and sass
css sprite主要用于前端性能优化的一种技术,原理是通过多张背景图合成在一张图片上从而减少http请求,加快载入速度。
浏览器兼容性
绝大部分情况下,我们需要考虑浏览器的兼容性,目前正在使用的浏览器版本非常多,IE6,IE7,IE8,IE9,IE10,Chrome,Firefox,Safari。
IE haslayout和block format content
IE haslayout是一个Internet explore for Windows的私有概念,他决定了一个元素如何显示以及约束其包含的内容、如何与其他元素交互和建立联系、如何响应和传递应用程序事件、用户事件等。而有些HTML元素则默认就有layout。目前只有IE6和IE7有这个概念。BFC是W3C css2.1规范中的一个概念,他决定了元素如何应对其内容进行定位。以及与其他元素的关系和相互作用。这个其实和浏览器的兼容性有关,因为决大部分的兼容性问题都是他们引起的。参考:css BFC和IE haslayout介绍。
css framework
css框架是一系列css文件的集合体,包含了基本的元素重置,页面排版、网格布局、表单样式,通用规则等代码块,用于简化web前端开发的工作,提高工作效率。目前常见框架有:
960 grid system
blueprint css
bluetrip
minimum page
还是一个比较出名的和特殊的框架是Twitter的bootstrap,bootstrap是快速开发web应用程序前端的工具包。它是一个css和HTML的集合,它使用了的浏览器技术,给你的web开发提供了时尚的版式,表单,buttons,表格,网格系统等等。它是基于less开发的,不支持IE6,在IE7和IE8里效果也不咋地。
css3
虽然css3还没有正式成为标准,但是IE9+,Chrome,Firefox等现代浏览器都支持css3。css3提供了好多以前需要用JavaScript和切图才能搞定的功能,目前主要功能更有:圆角、多背景、@font-face、动画与渐变、渐变色、box阴影、RGBa-加入透明色、文字阴影。
css性能优化
css代码是控制页面显示样式与效果的最直接“工具” ,但是在性能调优时他们通常会被web开发工程师所忽略,而事实上不规范的css会对页面渲染的效率有严重影响,尤其是对于结构复杂的web2.0页面,这种影响更是不可磨灭的。所以,写出规范的、高性能的css代码会极大地提高应用程序的效率。
less and sass
less和sass都是css预处理器,用来为css增加一些编辑的特性,无需考虑浏览器的兼容问题,例如你可以在css中使用变量、简单的程序逻辑、函数等等在编程语言中的一些基本技巧,可以让你的css更加简洁。适应性更强,代码更直观等诸多好处。
sass基于ruby开发,less既可以在客户端运行,也可以借助node.js或者rhino在服务器端运行。
如果您想订阅本博客内容,每天自动发到您的邮箱中, 请点这里
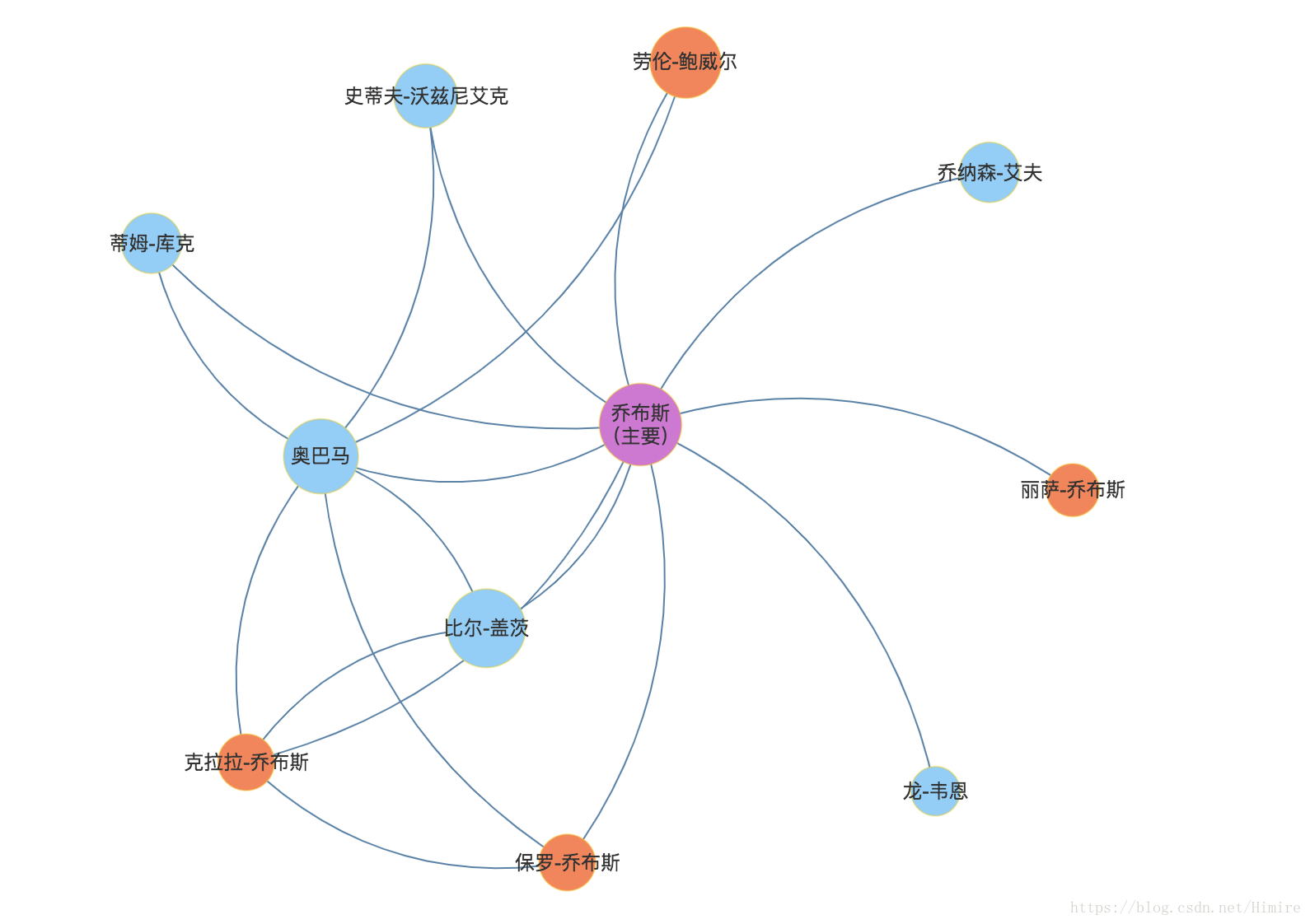
1.效果如上,官方示例简化
2.force1.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta name="description" content="ECharts"> <meta name="author" content="kener.linfeng@gmail.com"> <title>ECharts · Example</title> <script src="./js/echarts.js"></script> </head> <body> <div id="main" class="main" style="width: 800px;height: 800px"></div> <script src="./echartsExample.js"></script> </body> </html>
3.echartsExample.js
var myChart; var domMain = document.getElementById('main'); function requireCallback (ec) { echarts = ec; if (myChart && myChart.dispose) { myChart.dispose();
} myChart = echarts.init(domMain); window.onresize = myChart.resize; myChart.setOption(option, true); window.onresize = myChart.resize;
} var option = { title : { text: '人物关系:乔布斯', subtext: '数据来自人立方', x:'right', y:'bottom' }, tooltip : { trigger: 'item', formatter: '{a} : {b}' }, toolbox: { show : true, feature : { restore : {show: true}, magicType: {show: true, type: ['force', 'chord']}, saveAsImage : {show: true}
}
}, legend: { x: 'left', data:['家人','朋友']
}, series : [
{ type:'force', name : "人物关系", ribbonType: false, categories : [
{ name: '人物' },
{ name: '家人' },
{ name:'朋友' }
], itemStyle: { normal: { label: { show: true, textStyle: { color: '#333' }
}, nodeStyle : { brushType : 'both', borderColor : 'rgba(255,215,0,0.4)', borderWidth : 1 }, linkStyle: { type: 'curve' }
}, emphasis: { label: { show: false // textStyle: null // 默认使用全局文本样式,详见TEXTSTYLE }, nodeStyle : { //r: 30 }, linkStyle : {}
}
}, useWorker: false, minRadius : 15, maxRadius : 25, gravity: 1.1, scaling: 1.1, roam: 'move', nodes:[
{category:0, name: '乔布斯', value : 10, label: '乔布斯\n(主要)'},
{category:1, name: '丽萨-乔布斯',value : 2},
{category:1, name: '保罗-乔布斯',value : 3},
{category:1, name: '克拉拉-乔布斯',value : 3},
{category:1, name: '劳伦-鲍威尔',value : 7},
{category:2, name: '史蒂夫-沃兹尼艾克',value : 5},
{category:2, name: '奥巴马',value : 8},
{category:2, name: '比尔-盖茨',value : 9},
{category:2, name: '乔纳森-艾夫',value : 4},
{category:2, name: '蒂姆-库克',value : 4},
{category:2, name: '龙-韦恩',value : 1},
], links : [
{source : '丽萨-乔布斯', target : '乔布斯', weight : 1, name: '女儿'},
{source : '保罗-乔布斯', target : '乔布斯', weight : 2, name: '父亲'},
{source : '克拉拉-乔布斯', target : '乔布斯', weight : 1, name: '母亲'},
{source : '劳伦-鲍威尔', target : '乔布斯', weight : 2},
{source : '史蒂夫-沃兹尼艾克', target : '乔布斯', weight : 3, name: '合伙人'},
{source : '奥巴马', target : '乔布斯', weight : 1},
{source : '比尔-盖茨', target : '乔布斯', weight : 6, name: '竞争对手'},
{source : '乔纳森-艾夫', target : '乔布斯', weight : 1, name: '爱将'},
{source : '蒂姆-库克', target : '乔布斯', weight : 1},
{source : '龙-韦恩', target : '乔布斯', weight : 1},
{source : '克拉拉-乔布斯', target : '保罗-乔布斯', weight : 1},
{source : '奥巴马', target : '保罗-乔布斯', weight : 1},
{source : '奥巴马', target : '克拉拉-乔布斯', weight : 1},
{source : '奥巴马', target : '劳伦-鲍威尔', weight : 1},
{source : '奥巴马', target : '史蒂夫-沃兹尼艾克', weight : 1},
{source : '比尔-盖茨', target : '奥巴马', weight : 6},
{source : '比尔-盖茨', target : '克拉拉-乔布斯', weight : 1},
{source : '蒂姆-库克', target : '奥巴马', weight : 1}
]
}
]
}; var echarts; require.config({ paths: { echarts: './js' }
}); launchExample(); var isExampleLaunched; function launchExample() { if (isExampleLaunched) { return;
} // 按需加载 isExampleLaunched = 1; require(
[ 'echarts', 'echarts/chart/force', 'echarts/chart/chord',
], requireCallback );
}
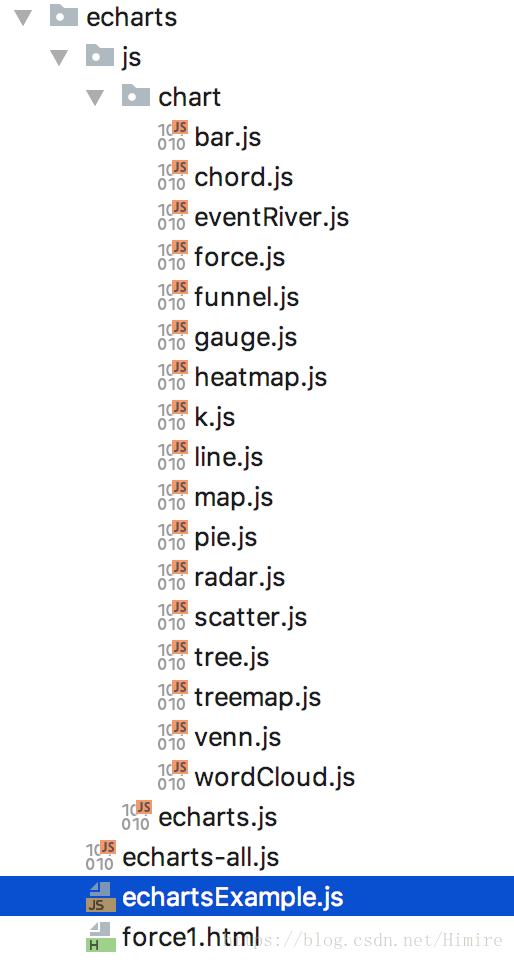
4.目录文件结构
话不多说,先上代码:
for(var j=0;j<10;J++){
setTimeout(function(){console.log(j);},5000)
}
看到这三行代码,你也许会不耐烦道:又要讲闭包?要吐槽了好么?别急,让我们先来思考一下,这段代码在浏览器中的执行结果是什么?
<!-- more -->
甲:顺序打印0到9?
乙:这题我见过,打印十个10!
哪个答案正确?
执行结果显示,浏览器打印出十个10,貌似乙对了,但是如果你足够细心,你会发现几个问题:为什么会循环打印十个10,而不是0到9?
从结果来看,for循环执行完跳出之后,才开始执行setTimeout(所以j才等于10),为什么不是每次迭代都执行一次setTimeout呢?
1、为什么会循环打印十个10?
许多人习惯用第二个问题中的执行结果来回答这个问题:“for循环执行完毕跳出之后才开始执行setTimeout,所以才打印了十个10”。这样的答案,只能说是既应付了自己,又应付了别人。其实,要解答第一个问题,首先要解答第二个问题。
2、为什么不是每一次迭代都执行一次setTimeout?
大家都知道,JavaScript在ES6出现以前,是没有块状作用域的,这就意味着,在for循环中用var定义的变量j,其实是属于全局的,那其实整个全局作用域中只有一个j,每次for循环都是更新这个j。
那么现在的关键问题在于,为什么整个for循环会先于setTimeout执行,而不是我们正常理解的,一次迭代执行一次。这就涉及到了JavaScript的核心特性:单线程。
JavaScript设计的初衷,是浏览器用来与用户进行交互和DOM操作的,这就决定了它必须是单线程的。设想JavaScript同时有两个线程,一个线程在DOM节点内添加内容,一个线程删除该节点,浏览器就会出现混乱。所以,为了避免复杂性,从一诞生,JavaScript就是单线程,这已经成为了这门语言的核心特征,将来也不会改变。
单线程就意味着,所有任务需要排队,前一个任务结束,才会执行下一个任务,如果前一个任务耗时很长,后一个任务就不得不一直等着。
为了优化单线程的性能,JavaScript将任务分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)。同步任务指的是,在主线程上排队执行的任务,只有前一个任务执行完毕,才能执行后一个任务;异步任务指的是,不进入主线程,而进入“任务队列(task queue)”的任务,只用主线程中的同步任务执行完毕,异步任务才会进入执行队列执行。只要主线程空了,就会去读取“任务队列”,这就是JavaScript的运作机制。这个过程会不断重复。
而setTimeout就被JavaScript定义为异步任务。每次for循环的迭代,都将setTimeout中的回调函数加入任务队列等待执行。也就是说,只有同步任务中的for循环完全结束,主线程中才会去任务列表中找到尚未执行的十个setTimeout(十次迭代)回调函数并顺序执行(先进先出)。而此时,j已经经过循环结束变成了10,所以此时主线程执行的,是十个一模一样的打印i的回调函数,即打印十个10,。至此完美回答了第一和第二个问题,文章开头的代码与下面的代码其实是等价的:
for(var i=0;i<10;i++){
setTimeout(console.log(i),5000);
setTimeout(console.log(i),5000);
setTimeout(console.log(i),5000);
setTimeout(console.log(i),5000);
setTimeout(console.log(i),5000);
setTimeout(console.log(i),5000);
setTimeout(console.log(i),5000);
setTimeout(console.log(i),5000);
setTimeout(console.log(i),5000);
setTimeout(console.log(i),5000);
}
小小的一个setTimeout,牵扯出了很多JavaScript的深层次问题,可见JavaScript还有许多地方是值得深入探究的。
蓝蓝设计的小编 http://www.lanlanwork.com

