2011-11-22 蓝蓝设计的小编
转载蓝蓝设计( www.lanlanwork.com )是一家专注而深入的设计机构 ,为期望卓越的国内外企业提供有效的 BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
阅读瞬间发生了什么?
当阅读行为发生时,如果能进入人脑,你会发现复杂的处理过程在瞬间发生。所以在谈论设计之前,让我们先来看看阅读表格时,人的大脑都会处理哪些任务。
阅读标题
:用户在阅读表格时通常会简单略过行或列的表头。
通读全篇
:用户也许会先花时间扫描全篇,了解表格的整体结构,数据分类以及复杂性。
视觉搜索
:为了找到数据,用户会顺着一行或者一列直到发现交叉点的有用信息,当用户对表格的结构熟悉,或者上下文的表格结构相同的时候,视觉搜索会更迅速的完成。
信息提取
:找到目标数据后,用户就从表中提取了一条基本信息。
理解
:用户倾向用他们已有的知识去理解已从表格中获取的信息。
确定类别和趋势
:用户会从感知层面对相似的数据进行归类并寻找变化趋势。
比较
:用户将会比较数据,并发现规律。
推断
:为了更深层次的理解数据变化,用户往往会推断一些结论
解释
:用户将会从自身的知识库中提取信息,来解释数据的意义。
回忆
:用户会需要记住表格中的一些信息,以便在将来使用这些信息。
决策
:用户会以他们对数据含义的解释为基础,进行相关决策。
什么影响了表格的可用性?
表格是否好用,取决于读表人是否熟悉表格结构,以及表格数据的复杂性和表格的设计与其目标是否相符。
在1977年Ehrenberg发表的启发性文章“算数入门(Rudiments of Numeracy)”中,作者这样定义一个好的表格的标准,“数据的规律性和例外情况应该一目了然,至少看一次后,人们就知道他们的含义”。他的观点是人们总是在不断的阅读表格,好的表格设计应该让人们在熟悉结构的基础上,很容易的就理解信息。而理解的含义就是明白数据之间的相互关系。
设计指南
当你已经确认了需要展示的数据信息,并且了解了表格设计的目的和在阅读时人们头脑中发生的一切,遵循如下的指南会让你的表格更有效。

1. 满足阅读者的期望
阅读者对表格越熟悉,他们就能越快的提取有用信息。满足阅读者的期望,我们就应该遵循表格在不同使用目的下的一贯的设计风格,例如我们在报纸的表格中会采用的艺术字体就永远不该出现在年度报告的数据表格中。
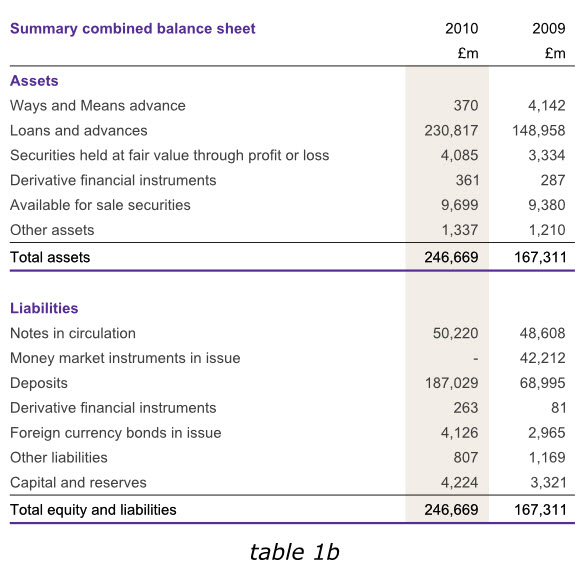
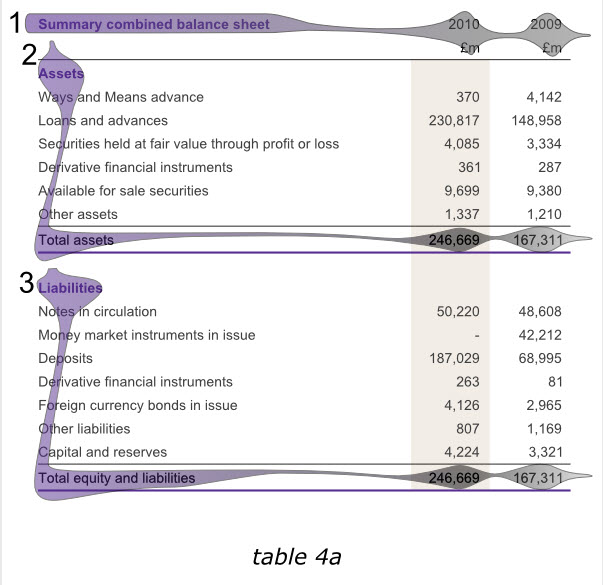
下面两幅表格展现的是英格兰银行2010年年报中完全相同的一组数据信息,然而,我们大多会选择阅读后者,因为他比前者传递了更清楚的信息。
在这里,读者预期的关键因素是一个阅读年报的人可能已经有过大量的阅读经验,并形成了年报信息展示的期望形式。事实上年报出版物中包含了大量有用的和重要的数据,而阅读这些数据的人们往往不再看上下文或者其他内容。
鉴于此,我们需要采用其他年报惯用的展示方式,以符合读者的阅读习惯,保证数据展示的清晰准确。请注意,下表中更清晰的那副,是基本上完全根据英格兰银行2010年年报格式制作,是清晰展示数据表格的优秀样本。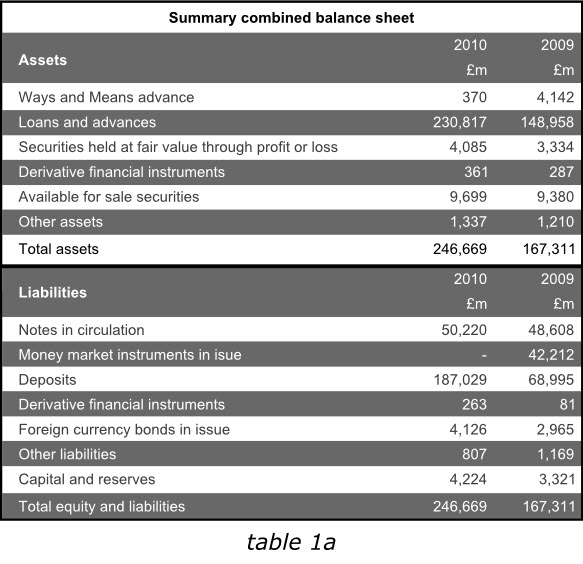
2. 依据设计目标,合理排序
结构化安排表格中的数据将有助于达到设计目的。如果表格的目的是比较中心城市的人口数量,那么我们就应该按照从大到小的顺序而不是开头字母的顺序排列数据。如果目的是展现学院一年以来的成本增长情况,那么就应该按照时间安排数据。
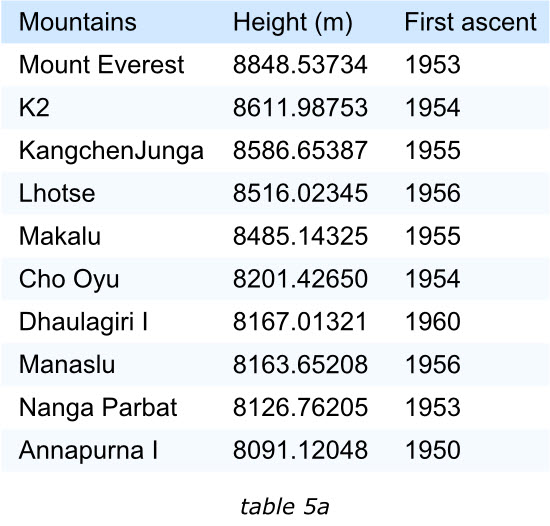
表格中的项目应该通过某种排序的手段来满足阅读者的兴趣。我们来看下面的两个表格,左面的展示了世界上最高的十座山峰,鉴于“高度”最受关注,那么表格的项目就是按照这个字段降序排列的。这样最受关注的信息能够排在表格的最前面。
然而,如果读者实际关注的是山峰首次登顶的时间,那么在左面的表格中,读者就需要费一番力气去找到第一个被登顶的山峰。显然右侧的表格排序方式将会更合理。
请注意,最被关注的字段应该放在最左面,越往左面排,重要性应该越高,虽然最左面的一列往往保留给项目名称或者关键字段,其后应该按顺序排列其他项目数据或数值。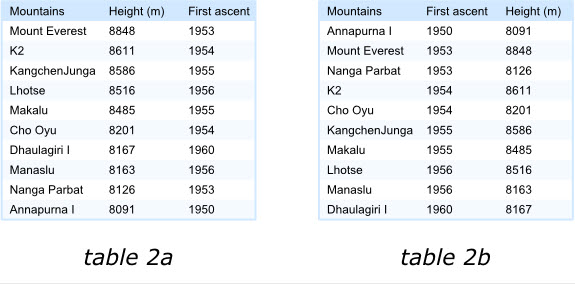
3. 移除无用元素
为了保证快速浏览,集中展现最重要的数据,请避免在表格周边堆砌各种不相干元素。如果想让表格中的数据自己说话,就不要让他被周边的装饰所淹没。在下面的黑白表格中,每一个数据上还有自己的单元格边框,这通常是HTML语言中默认的表现形式,但却给表格中的数据带来了不必要的杂乱感觉。
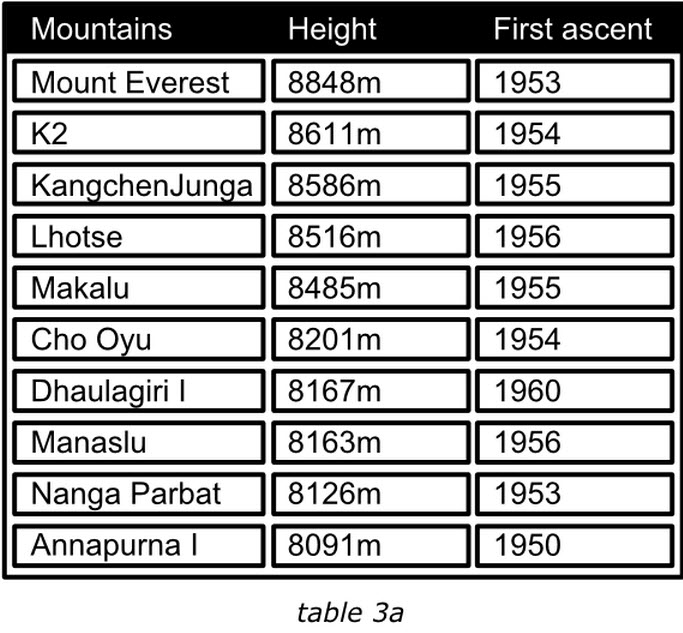
各种无用元素应该从表格的单元格、行、列、表头甚至表格周边内容中移除,以使表格呈现其本来面目。去除各种装饰后,表格的各个部分的重要性都将得到提升。例如在表格1b中,作为人们最感兴趣的一列,当年的经营业绩被简单清晰的突出显示,而其总和也被轻微的加粗。表3a就是一个非常典型的例子,由于使用了多余的单边各边框,使得数字和背景之间缺乏差异化,大大降低了有效信息在噪音中的比例,相比之下,表3b就好了很多。
4. 创造视觉层级
我们可以使用格式排版来标注重点并引导读者注意力,例如标题可以放大或者加粗,高亮可以引起注意。视觉记号可以使表格变得易读,使读者知道哪些内容更重要。
下面的英格兰银行2010年年报的一组信息被分成了两个表格,但仍然体现为一个整体。紫色的表头清晰的给出了标题,标题行仅用了一次表头(2009、2010)和单位(英镑)。两个表格采用同种颜色加粗的字体作为标题,清晰而相互独立。两表各自的最后一行也采用了同样颜色的下划线。
两个表格仅仅通过2010年一列的背景颜色相互连接,这不但实现了表格的联通,而且突出了2010年数据的重要性。表头以及最后一行的加总数据采用了粗重字体,并使用了行装饰线,能够导引阅读者的注意力到这些数据信息,因为2010年度的汇总数据是这个表格中最重要的数据。
阅读者可以不费力气的找到表格中的重要信息,以下的路径就表现出在分析相关表头和标签(紫色)和数据(黑色和灰色)过程中,读者目光扫描分成了三个快速独立的动作,而路径变粗的部分就是读者关注点所在。
5. 大多数人只看整数
用四舍五入后的整数填充表格更容易阅读并关注变化趋势,虽然这样对于专家们的科学数据来说会不太,但是大多数表格是为公众制作的,他们不需要那样的细节。表格设计者应该在考虑数据用途的基础上来决定是否进行四舍五入。统计学家Howard Wainer也建议我们,多数情况下,都不需要使用超过一位小数。
多余的数字是另外一种形式的无用元素,在那些读者对绝对没有兴趣的情况下,多余的细节会降低读者视觉扫描的速度。
例如:找到最接近8500米的山峰,第二章表格要远比第一个表格容易。山的高度到毫米显然没有必要,他使得读者误认为这些数据的确是经过精准测量,然而事实有可能不是这样。根据读者的需要提供数据的准确程度,并不会削弱数据的有效性。当然又少部分人会质疑第二章表格的准确性,但是大部分人会想山峰的高度能够被测量的如此吗?(山峰每年移动的距离就远不止于此),甚至还会对从整体上对数据的有效性以及及时性提出质疑。

6. 为读者做好计算
尽可能的不要让读者费心去进行数学计算或者思维转换,而应该通过在每一行或列的末尾提供汇总信息,例如“合计”或者“平均值”,这将大大提升理解和判断速度。
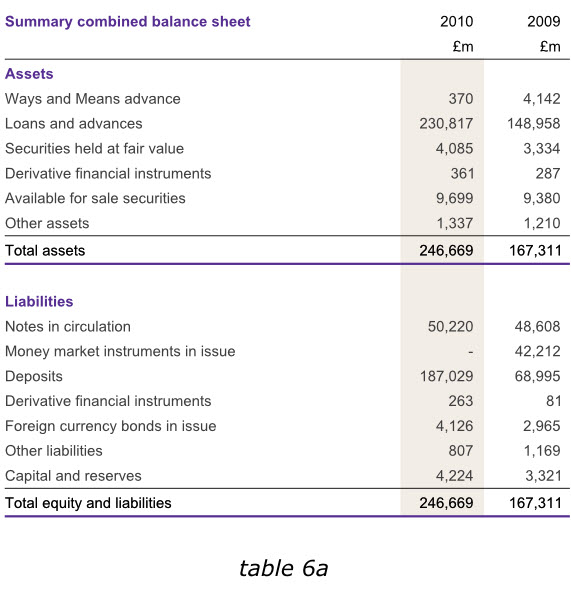
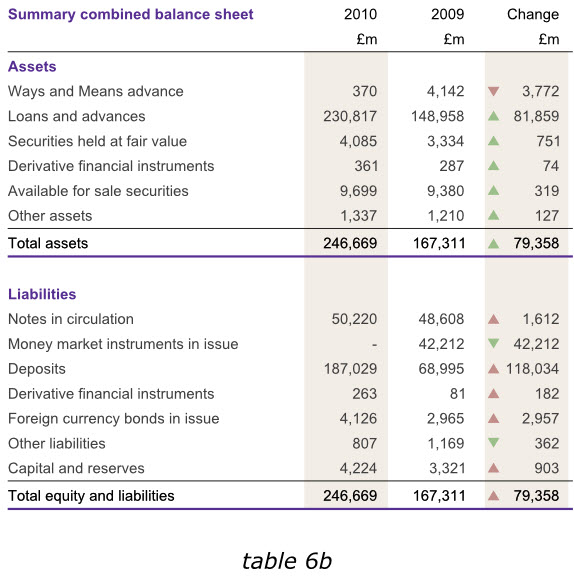
在英格兰银行2010年度报告中,尽管我们不能通过改变数据来达到读者的期望,但是在其他同样的报告中,我们在末尾增加一列有用的数据,以避免用户在比较各年度数据的时候,还需要自行计算增长或减少的幅度。下面第一个表格6a已经增加了总资产和总负债数据,而表格6b则在右侧增加了新的一列,使我们更容易分析出哪些领域的经营成果发生了实质性变动。
7. 保证前后风格一致
在表格中寻找信息时,读者希望前后采用同样风格,你应该保证对同类元素使用同样的字体,对同类数据使用同种对齐方式,还有诸如“列标题”等各种突出显示元素的一致性。看一下下面的表格7a,他展示了和前面表格1b同样的英格兰银行2010年度数据信息。但是使用了有区分的表头字体,标签以及加总格式,表头采用了居中格式而不是和数据一样右对齐,加总数据也没有与数据严格对齐,同时为了区别资产和负债表格,他分别采用了不同颜色的字体,和表格中间粗细不同的线条。而所有这些实际上都让我们产生一种不连贯的感觉,从而给浏览表格,把握重点带来难度。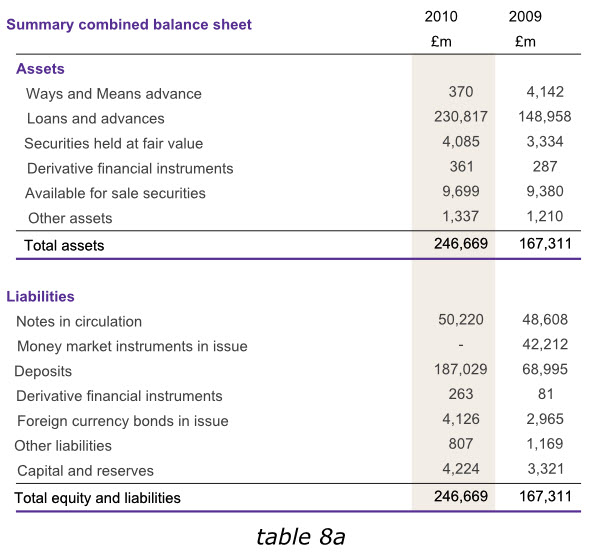
8. 有条理的对齐
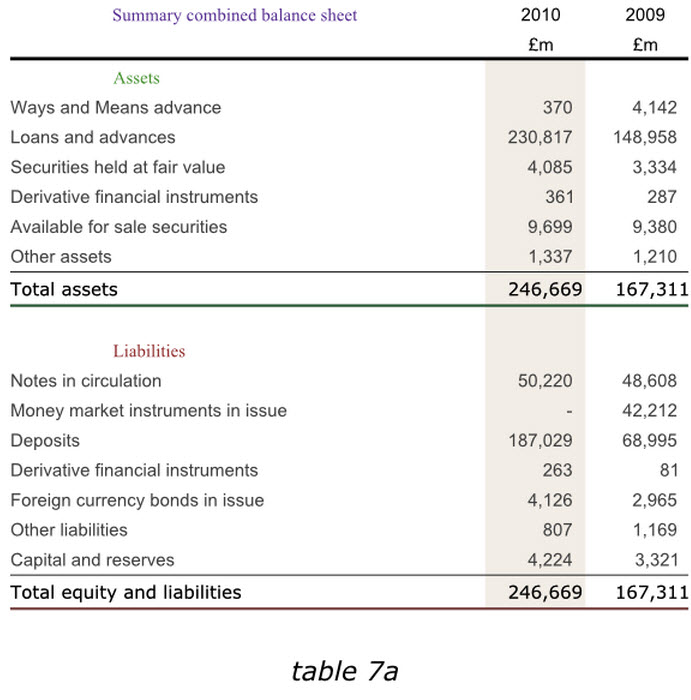
有意识的采用对齐格式将使表格更加易读,请注意将所有的数字,逗号,小数点彼此对齐,同时调整表格结构,使数据和单元格以及整个表格都是对仗整齐的。
我们来看下面8a的表格中英格兰银行2010年度数据是如何排列的,然后再对照一下表1b。在8a中,数据是水平居中的,标签也错位了并没有和表头对齐,这些使表格各种组成元素成为了分散的个体,降低了表格数据作为整体的前后连贯性和浏览效率,不仅是2009和2010年之间,就连行与行之间的数据也很难进行比较,因为他们没有对齐。8b中的情况就好了很多,我们可以清晰的看出表格数据采用的对齐标尺。在没有对齐的情况下,各行各列的数据宽度拉的越大,浏览阅困难。
9. 采用适当对比度,区分数据和背景
为了增加易读性,请保证表格前景和背景色之间足够的对比度,尤其是当表格的行或者列采用了阴影的情况下。
保证前后合适的对比度,对于阅读者非常重要,通常人们通过给行或列加上颜色来实现这个目标,但是颜色选择失当将会使前景与背景混杂,反而会降低数据的可区分度。比较一下表格9a和9b。9a采用了蓝色,但数据文字和表格背景的对比水平较低,而9b的对比度较高,更加易读,因为眼睛更容易区分重要数据。表格行或者列的阴影应该刚好足够引导目光沿着直线浏览,而不能过于突出。而表头与主体相比也该足够醒目,但是不能影响了数据在前景作为主体的展示效果。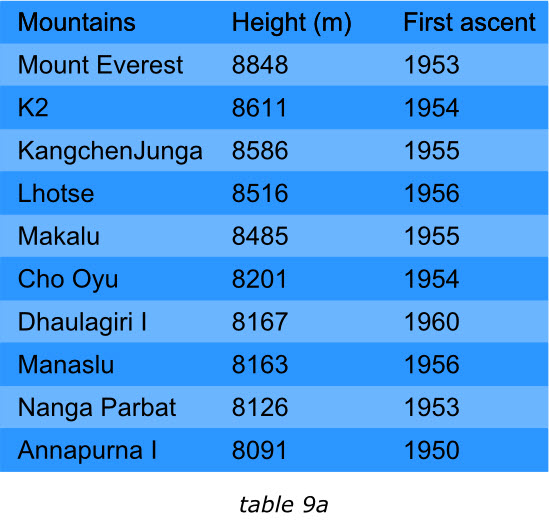

10. 给列数减肥
由于人们的视觉记忆有限,而且横向很难检索复杂信息,在可能的情况下,请尽量减少列的数量,如果需要的话,可以将表格分为两个。这样做是为了能让阅读者尽可能少的记忆和回忆信息。对于每一列,读者都需要记住上下文并浏览下面各行信息,读者可以很容易的纵向浏览单行数据,但横向浏览跨列数据时却相对困难。也正是为此,一般情况下,我们会隔行突出显示,而不是用列来引导目光浏览的方向。
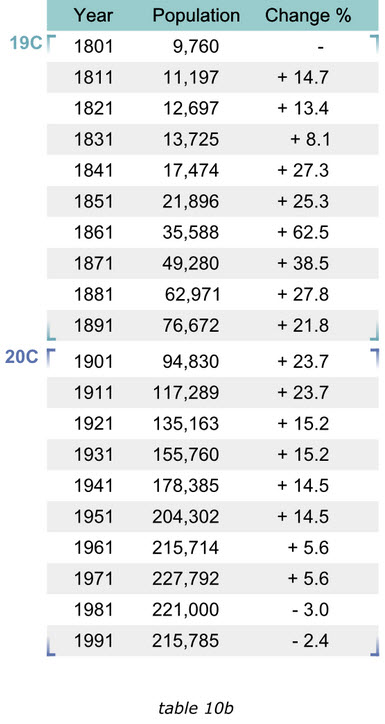
当我们在撰写wikipedia上的Trafford条目时,有一个1801至1991年的人口变化表格10a,他包含有2行20列,读者必须记住有关信息,并且不停的对照表头和数值来确认他们的关系,否则他们就无法获得趋势信息。
而在表格10b中,同样的信息被改用多行来展示,读者可以很容易的从上到下浏览并掌握人口变化的规律。非正常的信息也能很快被发现,例如19世纪中期之后的人口爆炸。同时,看一下10b是如何按照世纪来给行数据分类的,采用精心设计的周边点缀,示意性的的将各组分开,同时又未影响整体列数据的展示效果。
11. 让数据更易于比较
相对于上下比较来说,人们似乎更习惯于左右比较。鉴于此,构建你的表格让他更易于列与列之间的比较。而且这种情况下,人们可以很快的浏览纵向数据,虽然有时也会使用手指作为引导。
在表格10a和10b中我们已经了解到,当数据处于一列的时候,人们很容的可以比较数据并发现趋势。浏览者可以快速的从上之下扫描纵向数据,而对于长距离的横向数据,浏览就会遇到困难。然而我们再来看一下表格11a,去掉了所有的装饰框,当我们比较2009年和2010年数据的时候,数据横向摆放要比11b中的上下摆放容易的多。
那么我们什么时候应该采用横向或者纵向的摆位呢?这里,我们首先应该遵守第10条,尽量减少列的数量,由于人们通常认为不同的列之间展示的是不同的数据类别,表格11a看上去是两个组数据,而11b看上去则好像是8组数据。为了让大脑的短期记忆更好的处理数据,表格应该选择尽量少的数据组数,因此2009和2010的两组数据采用同样是两组的摆放形式时,阅读的体验是最好的,比较起来最容易。
另外一个例子,当我们的行数与列数相等的时候,我们就迫使大脑进行分组,如表格11c是一个简单的算术乘法表,没有表头而且行列间距相同。而表格11d我们缩小了行间距,增大了列间距,11e我们缩小了列间距而增大了行间距,在11d和11e中,我们仍然有等同的行列数量——6行6列,但是分组暗示更加明显,便于人们区分不同的条目。
因此,应该最先考虑的是减少列的数量,但当其他情况都相同的情况下,对于大量同组数据应该选择纵向摆放,更容易发现规律和趋势。而不同组别的少量数据条目采用左右放置更好。按照这样的方式组织你的数据,你会发现其中的益处,别总是采用一种明暗交替的方式来设计你的表格了。

(待续)
【本文由VenturTech 授权译言网呈现,如需转载请与VenturTech联系】