2022-4-17 ui设计分享达人


作为一枚设计小萌新,对上述场景,是否似曾相识呢?此些尴尬的情况,也映射出了不少问题:数据化设计意识薄弱,数据基础知识模糊,缺乏系统的体验评估模型和度量方法等等。
那么,我们该从哪些维度进行数据分析呢?数据的基础知识又有什么呢?常见的数据分析方法又有哪些?诸位看官抓好扶好,入门版航班即将起飞,让我们一起走进数据的世界,掌握一定的数据分析能力,告别“我要我觉得”的任性决策。

增量尚不明确,存量博弈的下半场,都以去肥增瘦的方式,宣告着精细化运营的时代到来,似乎也对设计师同学提出更高专业的要求。数据意识作为能力象限中的某个小瓦块,虽然细微,但也是专业输出的切入点。
在面对产品功能迭代、用户行为分析、日常监测、设计决策以及效果评估等等问题时,单纯的从视觉维度进行推导,会稍显单薄。而基于客观数据的分析,可以更科学准确的辅助我们进行决策。


所谓的“数据指标”,简单来说就是可将某个事件量化,且可形成数字,来衡量目标。在一定程度上,“数据指标”能揭示出产品用户的行为和业务水平状况。
目前市面上的产品种类繁多,大致都围绕“用户是谁、做了何事、结果如何”进行归纳整合,分别对应着用户数据、行为数据、业务数据三类指标。

1. 存量:反映某一时间段内活跃的用户数。以日活(DAU)、周活(WAU)、月活(MAU)维度进行统计。其中,Active需以关键用户的自发行为来进行定义,常见的动作有登录、浏览内容等。
2. 增量:一般用新增用户数来反映,同样分为日新增(DNU)、周新增(WNU)、月新增(MNU)三类统计维度。其中,增量的定义相对模糊,需提前与渠道确认好新增指标,建议根据内部的账号体系进行指标的取舍,选择新增注册用户还是新增设备数。
3. 来源:用户从何而来,包含自然搜索、产品导流、好友邀请等多种渠道。结合不同渠道用户的数据表现,可以指导后续的推广方案。
4. 留存:通过留存率来评判产品的健康程度,表示新用户在一定时间段内,某些行为重复发生的比率。其中,日留存和月留存的评判分析作用又有所不同:
日留存:作为衡量用户渠道质量的重要依据,如老王的公众号在站酷、知乎、微信群进行导流宣传,通过分析不同渠道的用户留存表现,从而优化受众用户的投放来源。
月留存:作为用户粘性的重要判断,通过指标来分析产品对用户是否长期有吸引力。也可用作产品上新后,功能迭代是否符合预期的判断依据。
1. 访问深度:用户单次浏览页面的过程中,浏览了页面的数量越多,表示用户访问深度越深,产品粘性较好。
2. 转化率:指在一个统计周期内,完成转化行为的次数占总访问次数的比率。转化率=(转化次数/点击量)×100%。如在电商、理财等产品中,转化率是衡量产品优秀与否的重要指标之一。
3. 跳出率:访问了单个页面的用户占全部访问用户的百分比,可用来衡量访问质量,高跳出率通常表示内容或体验与用户目标脱节。
4. 停留时长:用户游逛的时间长度,需要区分对待内容消费与工具效率场景,高停留时长并非全是正向反馈。
5. 次数:包含页面访问次数(PV)和用户访问次数(UV),通过页面或者用户作为计数单位,但需进行相应数据去重,保证数据的真实性。
6. 点击率:CTR(Click-Through-Rate)即点击通过率,某一内容被点击的次数与被显示次数之比,CTR是衡量互联网广告效果的一项重要指标。影响用户点击的因子较多,作为入口级内容,却具备较大的设计发挥空间,可通过信息的布局与核心利益点的外化,实现行为号召(Call to Action)
1. 总成交量:GMV(Gross Merchandise Volume)属于电商平台企业成交类指标,主要指订单的总金额,包含付款与未付款两部分
2. 人均消费金额:ARPU(Average Revenue Per User)即每用户平均收入。这个指标计算的是某时间段内平均每个活跃用户为应用创造的收入。
3. 续费率:指的是在订阅期结束时,选择续费的用户占所有应续费用户的百分比
4. 付费率:付费用户占活跃用户的比例。
5. 用户周期价值:LTV(life time value)是产品从用户获取到流失所得到的全部收益的总和,当LTV大于平均获客成本和后续的运营成本时,产品获得净收益。

对上述数据类别有所了解之后,我们在面对纷纭复杂的应用类型与数据概念时,到底该怎么选取合适的指标进行衡量和分析呢?接下来,让我们进入下一个知识点-指标建模。我们大致可以按照以下方法进行关键指标的选取。
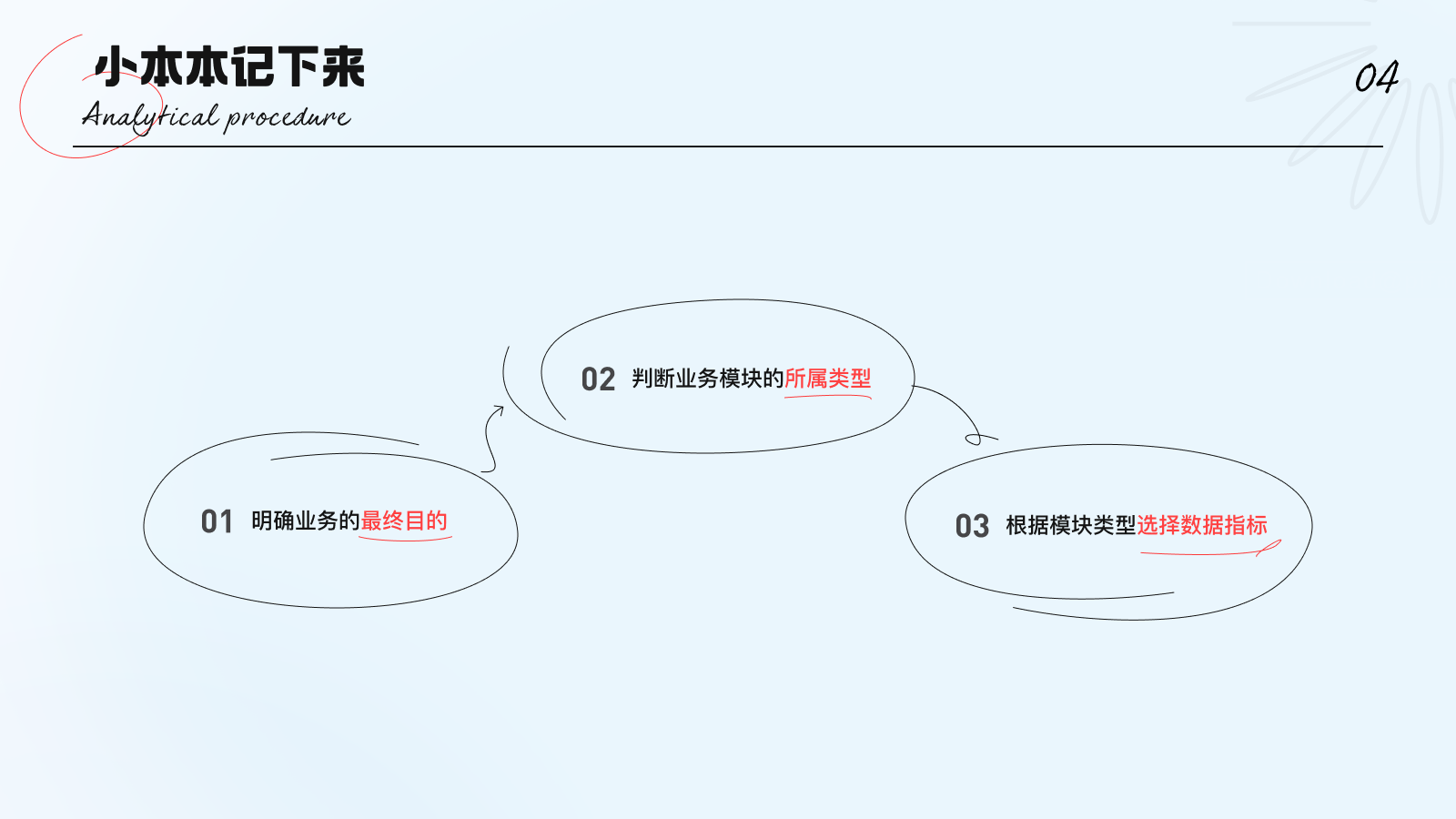
① 明确业务的最终目的;
② 判断业务模块所属类型;
③ 根据模块类型选择数据指标;
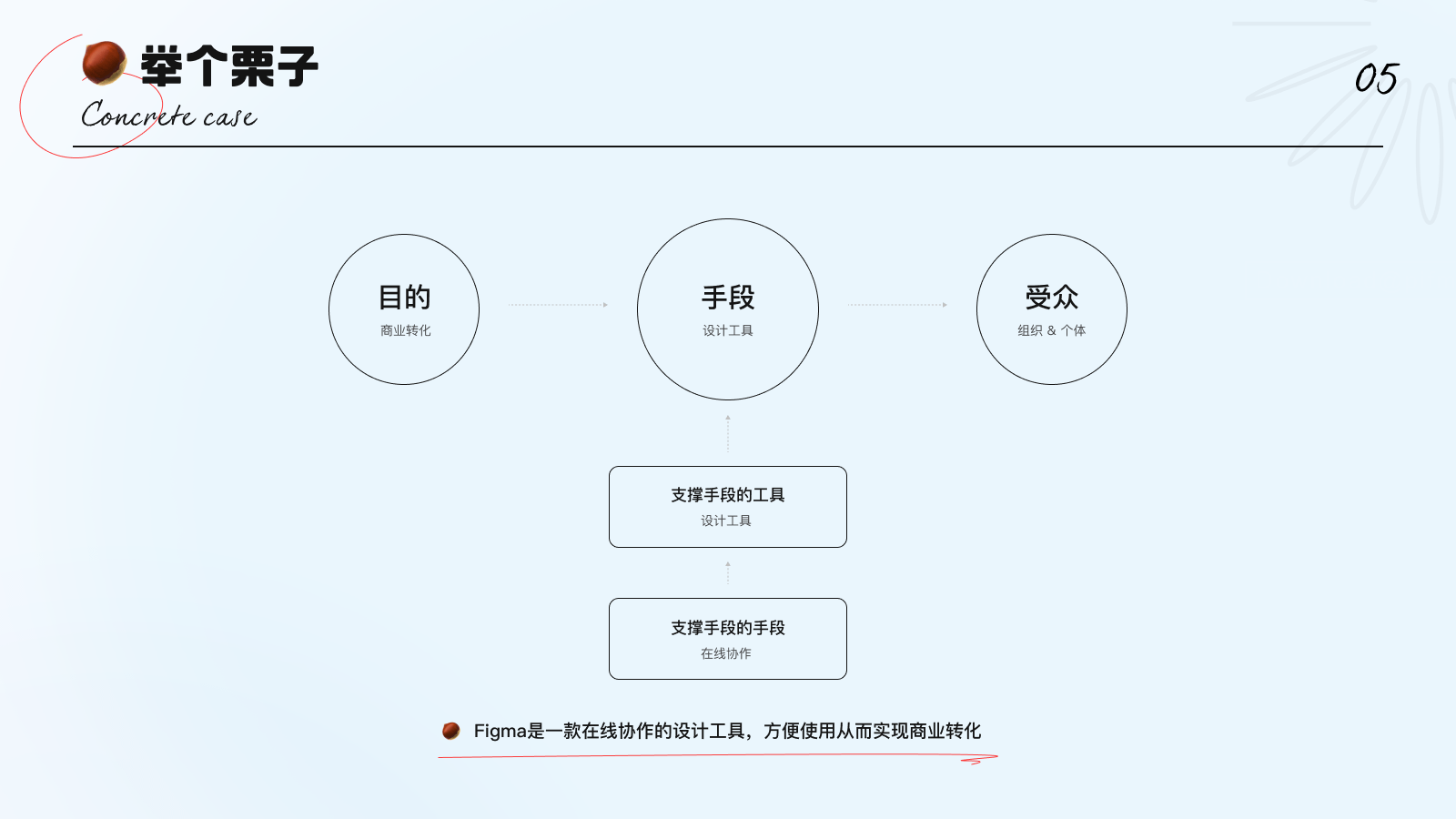
任何产品都有其商业或生存目的,且通常会使用一些支撑手段的工具、或是支撑手段的手段来达成目的。我们以“设计软件-Figma”为例,进行业务目的与手段的拆解。
1. 目的:Figma 是一个基于浏览器的协作式 UI 设计工具,其最终目的是完成商业变现,让更多用户付费购买。
2. 手段:为达成这一目标,而采用基于web的模式这一手段,极大的方便了团队协作办公的需求,继而备受青睐,普及率节节攀升。
3. 支持手段的工具:此外,借助开源的插件及完善的组件功能,为设计创作者提供更便捷的工具支持。
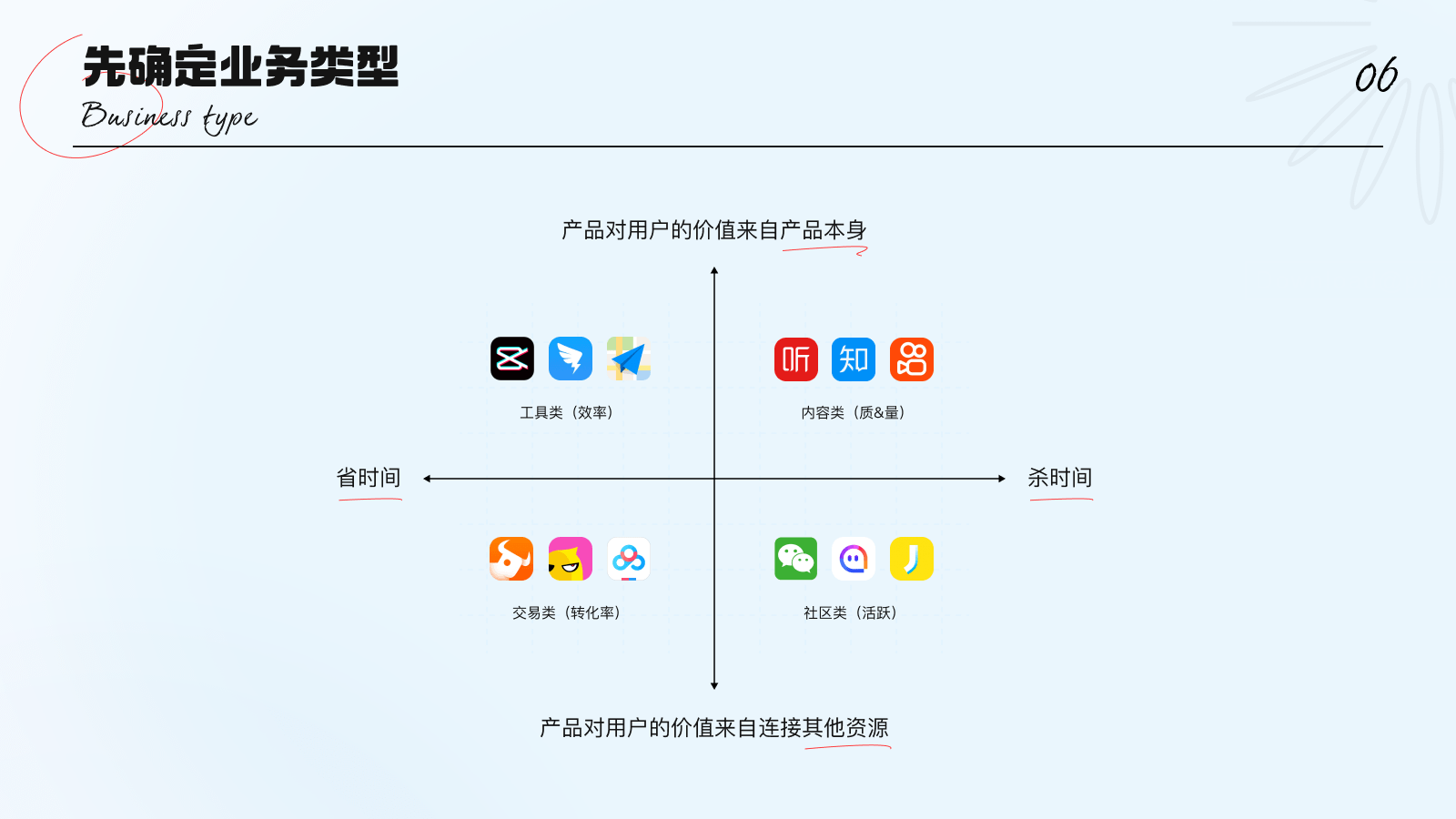
在从业务的最终目的出发,梳理业务模块后,可进一步的拆解该业务模块的具体类型。为方便理解,可以按照产品价值,将功能模块分为4种类别:工具、内容浏览、社区、交易。
1. 针对本身自带价值属性的产品,按照帮助用户节省时间和消磨时间可分为:
工具类:剪映、轻颜相机、飞书文档及翻译查词等
内容浏览类:各类图、文、音视频体裁的消费内容,如短视频、喜马拉雅、知乎等
2. 另一类产品本身不产生价值,通过自身的平台属性来连接资源,同样按照帮助用户节省时间和消磨时间可分为:
社区类:小红书、即刻、微博等
交易类:电商板块、会员付费板块以及直播打赏充值等
按照时间与价值维度,将产品划分为4类模块,每类都有各自需要核心关注的指标要素
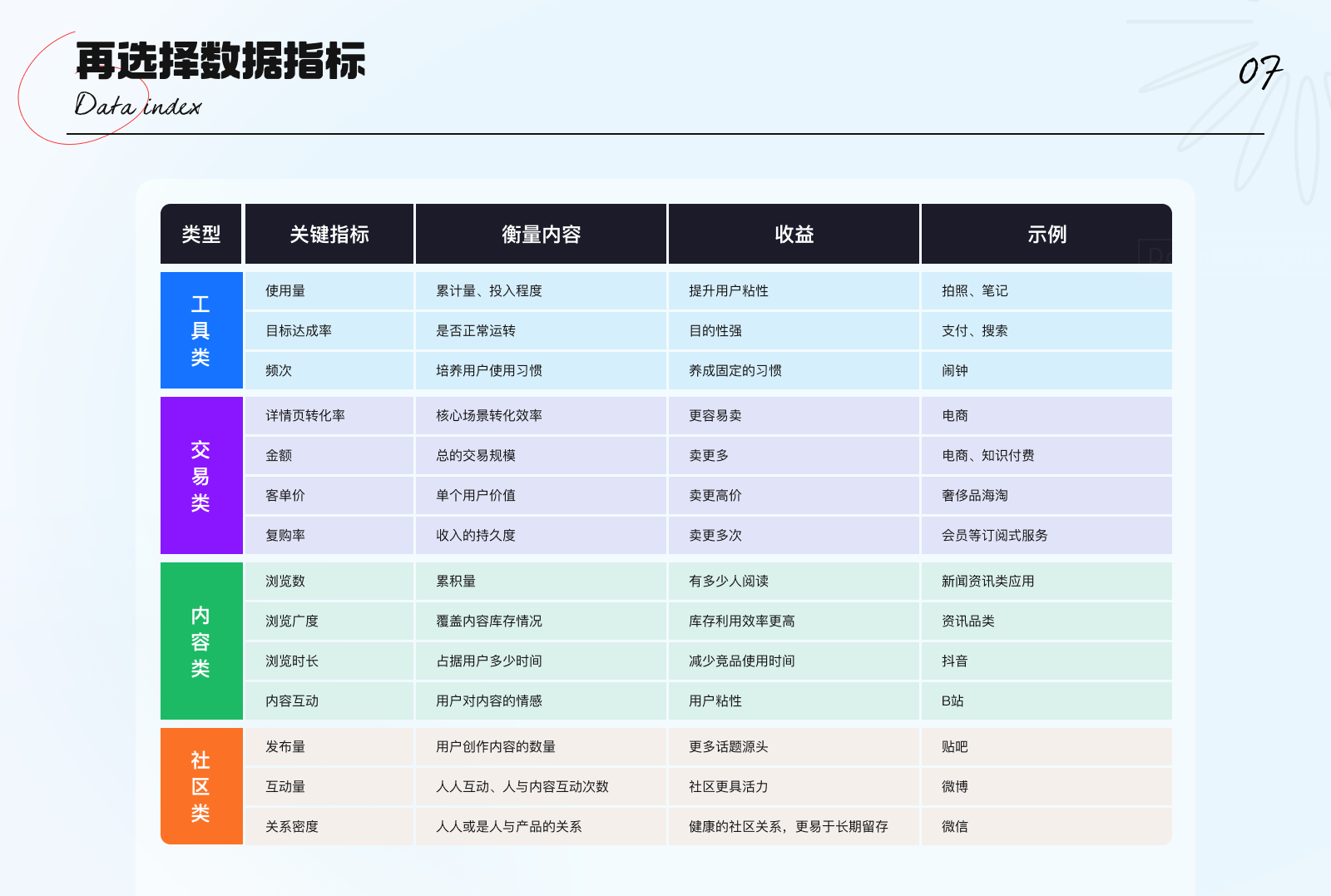
下面对4种分类的功能模块,分别介绍如何选取指标体系
1. 工具类:通过产品达成个人目标,高频的使用行为,可以培养用户的固定习惯。因而可主要关注使用量、目标达成率、频次数据指标。(示例:剪映)

2. 交易类:以详情页作为用户购买动机的诱因,实现付费转化。倘若能多次反复的购买商品或服务,整体转化效果更佳。因而,可选取详情页转化率、客单价、复购率作为衡量指标。(示例:百度网盘)
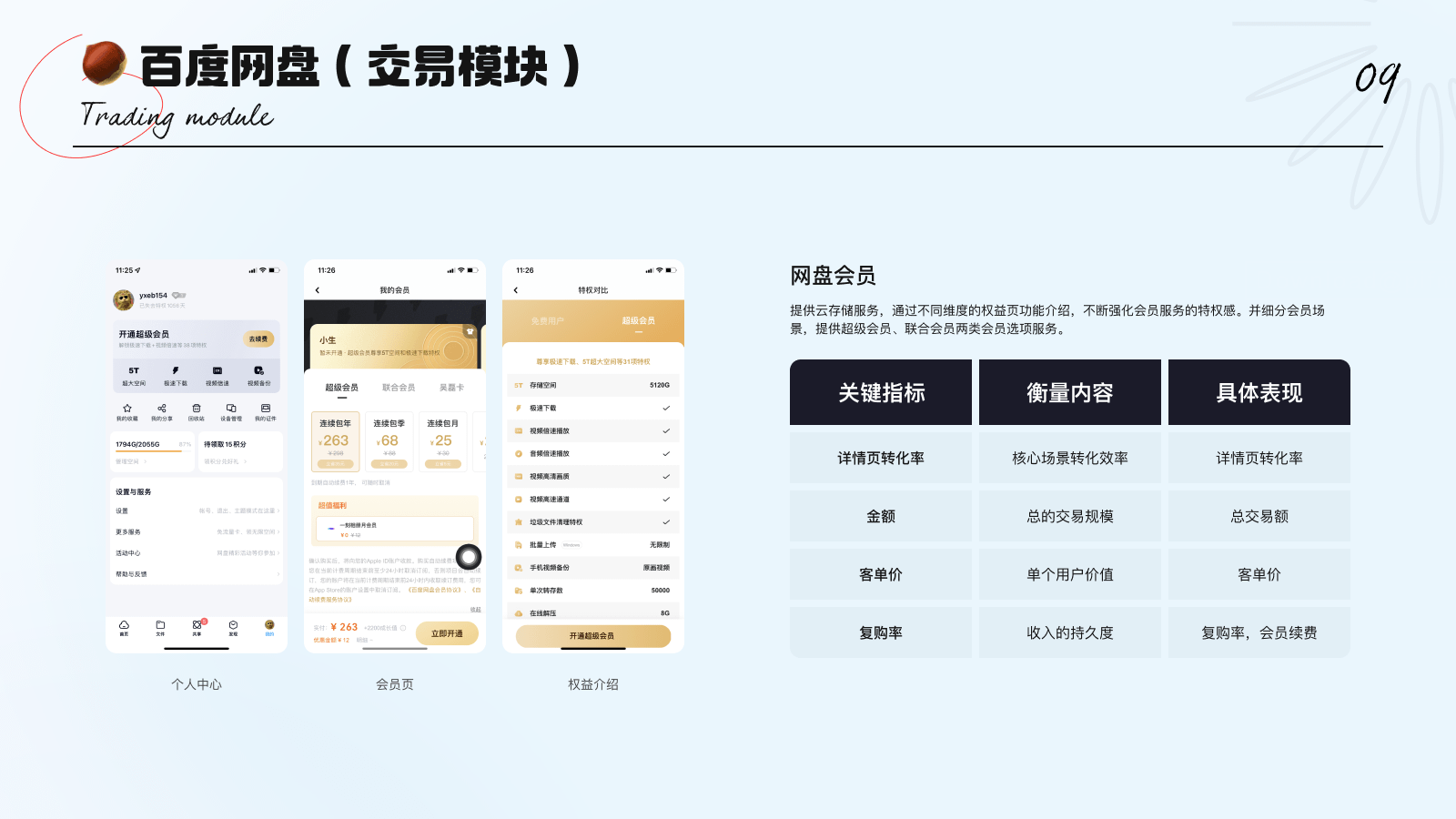
3. 内容浏览类:用户是否已获得更优质的内容,愿意投入更多的时间浏览内容,并能触发与内容的互动行为。因而可选取浏览数、浏览广度、浏览时长和互动行为作为衡量指标。(示例:快手)

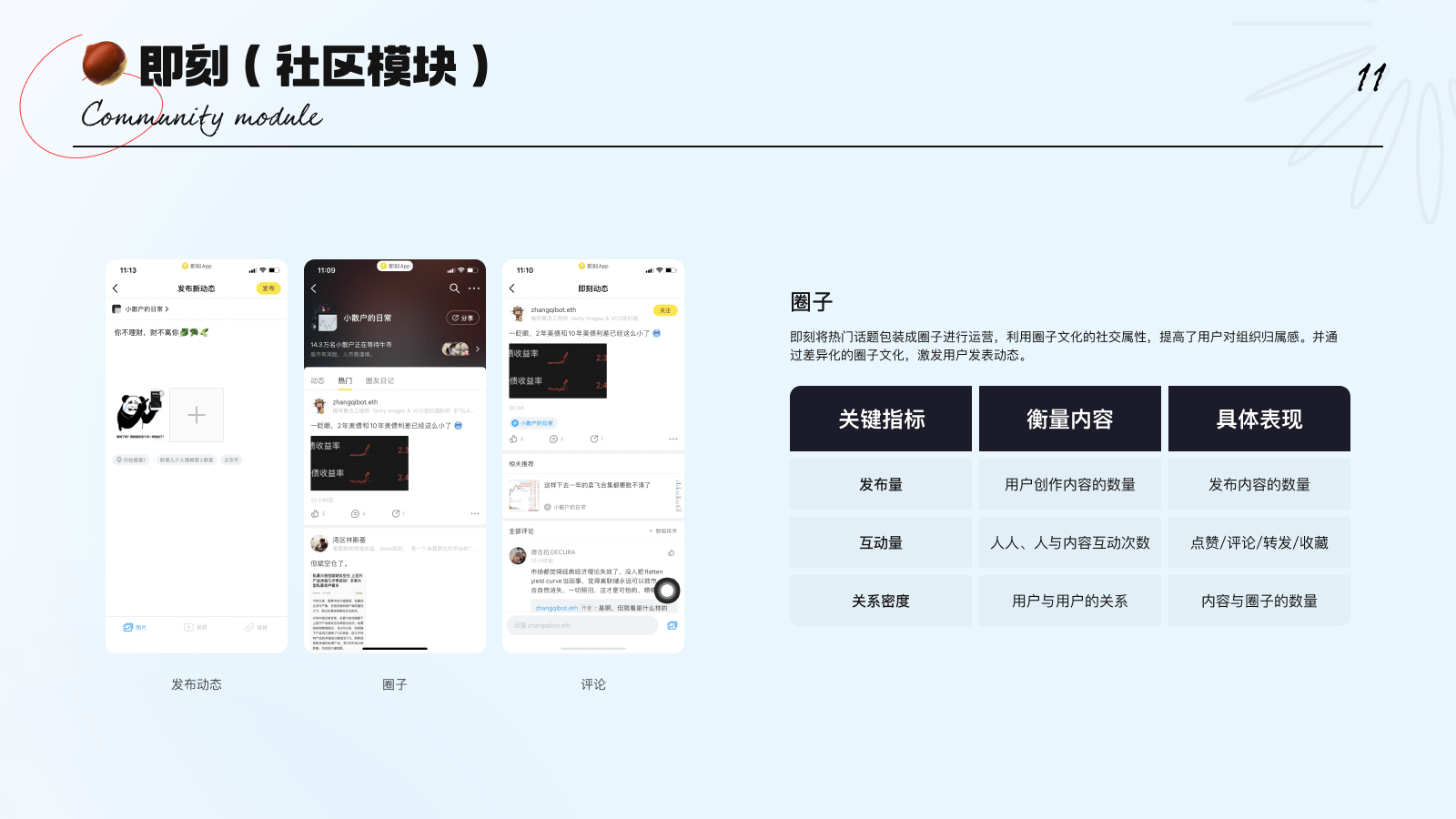
4. 社区类:社区环境主要受人与内容、以及人与人之间的关系影响。鼓励用户发布内容,以创造的内容来吸引其他用户产生共鸣,从而进行内容创造与互动行为。因而,可选取发布量、互动量、用户间的关系密度作为衡量指标。(示例:即刻)

在产品迭代发展的过程中,掌握有效的数据分析方法,能让冰冷客观的数据鲜活起来,为决策提供判断依据。接下来,就给大家推荐两类高频数据分析方法,请注意查收。
由Dave McClure 2007提出的客户生命周期模型,可以帮助大家更好地理解获客和维护客户的原理。其核心为AARRR漏斗模型,对应着实现用户增长的5个指标:
1. 获取(Acquisition):用户如何发现(并来到)你的产品?
2. 激活(Activation):用户的第一次使用体验如何?
3. 留存(Retention):用户是否还会回到产品(重复使用)?
4. 收入(Revenue):产品怎样(通过用户)赚钱?
5. 传播(Refer):用户是否愿意告诉其他用户?
我们在进行数据分析的时候,应该考虑用户正处于AARRR模型的哪个部分、关键数据指标是什么、对应的分析方法又是什么?

科学反映用户行为状态以及从起点到终点各阶段用户转化率情况,是一种重要的分析模型。广泛应用于网站和App用户行为分析的流量监控、电商行业、零售的购买转化率、产品营销和销售等日常数据运营与数据分析的工作中。
例如:在完成电商购物行为时,共包含浏览选择、查看详情、添加购物车、生成订单、支付等环节。通过监控用户在流程上的行为路径,漏斗能够展现各个环节的转化率,直观地发现和说明问题所在,更快定位出某个环节的具体问题。


除了需要了解分析方法之外,还需要提防以下数据分析常见谬误,避免落入陷阱之中,从而做出错误的决策。
1. 数据偏⻅
在分析数据时受个⼈偏⻅和动机的影响,即仅选择⽀持你声明的数据,同时丢弃不⽀持声明的部分。“数据偏⻅”将让数据的客观性荡然⽆存。 避免这种谬误的⽅法是在分析数据时,尽可能收集相关数据,并询问他⼈意⻅。
2. 采样偏差
在做抽样分析时,选取的样本不够随机或不够有代表性。例如,互联网圈的人极少会使用PDD,为何该应用还会有这么好的市值表现?
3. 因果相关谬误
将两个同时发生的事件,判断为因果关系,忽略了其中间变量。例如,隔壁老王生了个孩子,同时种了一棵树。孩子和树都随着时间的推移而长高,在一定时间内,如果使用相关性分析,可以得出这两个变量具有相关性。然而我们都很清楚,孩子长高和树长高之间,并不具有因果关系。
4. ⾟普森悖论
即在某个条件下的两组数据,分别讨论时都会满足某种性质,可是一旦合并考虑,却可能导致相反的结论。避免“辛普森悖论”给我们带来的误区,就需要斟酌个别分组的权重,以一定的系数去消除以分组资料基数差异所造成的影响。
5. 定义谬误
在看某些报告或者公开数据时,经常会有人鱼目混珠。「网站访问量过亿」,是指的访问用户数还是访问页面数?
6. 比率谬误
谈论此类型指标时,都需要明确分子和分母是什么。另一方面,在讨论变化的百分比时,需注意基数大小。如小王和小刘体重都上涨了10%,但二者的体重基数分别为60kg、90kg。
文章来源:站酷 作者:美工李大强
分享此文一切功德,皆悉回向给文章原作者及众读者.
免责声明:蓝蓝设计尊重原作者,文章的版权归原作者。如涉及版权问题,请及时与我们取得联系,我们立即更正或删除。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务