

千呼万唤始出来,犹戴口罩半遮面
要说上周什么消息最激动人心,那绝对是全国7月20日低风险地区电影院重开无疑了

消息一出,蛰伏数月的电影爱好者们,纷纷倾巢出动在央妈的评论区里为电影提前打Call。

各种网络段子也是应声齐飞:什么待业电影院员工急售餐车抢复工;上座率不超30%,情侣们也得分开坐

想必各位鸭脖听闻也是激动难耐特别是海报设计师们,终于不用因为没活儿继续挨饿了
趁此机会,先来看看电影海报,一来可解相思之苦,顺便排一排雷,还能边挑边学设计技巧,三全其美,岂不快哉:
1. 误杀
重映时间—7月20日
近年来难得一见的国产剧情好电影,单从海报上就可见一斑。
「看1000部电影」不能助你飞黄腾达,却能让你将世人的眼睛玩弄于股掌,既然生活是一部电影,那就没有什么是不能人为去剪辑的。

表面上束手就擒的一家人,实则齐心协力,暗度陈仓。

如果你认为孩子画的案发现场,将成为如山铁证,那么恭喜你,人都还没进影院,就已经陷入了导演的叙事诡计。

2. 第一次的离别
上映时间—7月20日
发生在新疆男孩与母亲间的温情故事,母亲患病无法言语,更时常离家出走,两小无猜的男孩女孩,毅然穿越漫漫黄沙,踏上寻母的道路。

沙漠中,只要三个人影在孤独地行走路的尽头,究竟是与人别离,还是要跟童年别离,或许,二者都是。

3. 璀璨薪火
上映时间—7月20日
作为非物质文化遗产纪录片的海报一只饱经风霜的粗糙的手,谈不上精妙创意,甚至颇有些质朴。

但别忘了,正是这一双双沉稳的手,日复一日,年复一年守护着国人傲立世界的文化的骄傲。

4. 妙先生
上映时间—7月31日
年度话题大作《大护法》的姊妹篇有关「善良」的深刻讨论,如果每次拯救恶人,都要牺牲好人,那这种所谓的拯救,究竟还值不值。

温馨提示,内有大汉「聚众赏菊」是成年人画给成年人看的动画片。

5. 呆瓜兄弟
上映时间—7月31日
从1976年开播的第一集就让观众捧腹大笑的木偶短片。

40年后重聚的不光是这两只呆瓜更是荧幕前的观众与自己的童年。

1. 我想静静
上映时间—8月07日
号称「国内首部动物喜剧电影」海报却疑似「宠物店」素材打底。

以上动物皆不会出现在电影中怕不光是「首部宠物喜剧」更是「首部魔幻现实主义作品」

2. 荞麦疯长
上映时间—8月25日
神似一年一度感动中国的构图展现着上世纪90年代,三个相互交织串联的青年人生。

在人们热衷讨论00后、05后的当下导演将镜头对准70、80,在建的东方明珠,既是时代的挽歌也是对一代青年人美好未来的赞美。

3. 我在时间尽头等你
上映时间—8月25日
偶然间获得的超能力让男主能够回到过去,挽救爱情却被命运捉弄,始终都不得圆满

与《时空恋旅人》同样的科幻题材海报当中,也有十分相似的一场雨,希望如同《流浪地球》,国人能再次拍出不输经典的高水准。

4. 小妇人
上映时间—8月待定
女性可以柔弱,也可以拥有高傲的头颅南北战争中的四姐妹,在清苦生活中活出了不一样的坚强人生。

5. 急先锋
上映时间—8月待定
角落里熊熊燃烧的美国核动力航母身后高耸入云的迪拜塔,没有一处不在透露着这是部大制作。

从沙漠到瀑布,剧情搭不搭且不说至少光是海报就搭了不少真金白银。

上映时间—8月待定
一心想揭露社会阴暗丑恶的新闻记者处处与人为善的老好人,矛盾的二者相遇,会是场何样的闹剧。

上一秒促膝长谈,下一秒皮鞋横飞「邻里间的美好」或许本身就是伪命题。

6. 许愿神龙
上映时间—8月待定
上海少年误打误撞唤醒沉睡神龙却发自己与龙有着上千年的代沟,西式画风,中式温情,一人一龙的冒险故事,值得一看。

7. 无名狂
上映时间—9月25日
一部诞生于摩点众筹的众筹电影片名叫《无名狂》,海报却写满了赞助的网友的名字。

围绕万历年间两大刺客门派所展开的一场场腥风血雨,平静海报之下,山呼海啸,风雨欲来。

除此之外,还有不少电影尚未排期,全年随时可能上映。其中自然也不缺乏优秀的海报创意,比如从路人视角,见证抗战历史的《八佰》。

克味十足,容易联想到哈利波特系列的《刺杀小说家》

单靠海报配色就能让人陷入迷惑的《抵达之谜》

颇有08年阿迪达斯海报味道的《夺冠》


用风卷云涌展现中式诸神之战的《封神三部曲》

居然还能拍出第二部的《爵迹2》

正看是海浪,倒看是山峦的《一直游到海水变蓝》

近看是悬崖,远看是枪口的《悬崖之上》

六小龄童老师参与动捕制作今年下半年…可能会上映的《真假美猴王》

希望别播完片头就播staff名单的《一秒钟》

能把牛顿从棺材里吓活过来的《神秘访客》

进退两男、男上加男、满身大汉的《唐人街探案3》

生死一线间淡定到面带微笑的《紧急救援》

以及万众期待的封神宇宙大片《姜子牙》

好了,以上就是2020年将要上映以及可能上映的电影的海报大合集。看完了这些精彩的海报焦急的等待之情是否缓解了一些?
倒也正应了那句老话,只要熬过低谷,后面都是更好的一天。
文章来源:优设 作者:你丫才美工
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
我们应该学习 webpack 吗 ?
如今,CLI工具(如create-react-app或Vue -cli)已经为我们抽象了大部分配置,并提供了合理的默认设置。
即使那样,了解幕后工作原理还是有好处的,因为我们迟早需要对默认值进行一些调整。
在本文中中,我们会知道 webpack可以做什么,以及如何配置它以满足我们的日常需求。
什么是 webpack?
作为前端开发人员,我们应该熟悉 module 概念。 你可能听说过 AMD模块,UMD,Common JS还有ES模块。
webpack是一个模块绑定器,它对模块有一个更广泛的定义,对于webpack来说,模块是:
Common JS modules
AMD modules
CSS import
Images url
ES modules
webpack 还可以从这些模块中获取依赖关系。
webpack 的最终目标是将所有这些不同的源和模块类型统一起来,从而将所有内容导入JavaScript代码,并最生成可以运行的代码。
entry
Webpack的 entry(入口点)是收集前端项目的所有依赖项的起点。 实际上,这是一个简单的 JavaScript 文件。
这些依赖关系形成一个依赖关系图。
Webpack 的默认入口点(从版本4开始)是src/index.js,它是可配置的。 webpack 可以有多个入口点。
Output
output是生成的JavaScript和静态文件的地方。
Loaders
Loaders 是第三方扩展程序,可帮助webpack处理各种文件扩展名。 例如,CSS,图像或txt文件。
Loaders的目标是在模块中转换文件(JavaScript以外的文件)。 文件成为模块后,webpack可以将其用作项目中的依赖项。
Plugins
插件是第三方扩展,可以更改webpack的工作方式。 例如,有一些用于提取HTML,CSS或设置环境变量的插件。
Mode
webpack 有两种操作模式:开发(development)和生产(production)。 它们之间的主要区别是生产模式自动生成一些优化后的代码。
Code splitting
代码拆分或延迟加载是一种避免生成较大包的优化技术。
通过代码拆分,开发人员可以决定仅在响应某些用户交互时加载整个JavaScript块,比如单击或路由更改(或其他条件)。
被拆分的一段代码称为 chunk。
Webpack入门
开始使用webpack时,先创建一个新文件夹,然后进入该文件中,初始化一个NPM项目,如下所示:
mkdir webpack-tutorial && cd $_
npm init -y
接着安装 webpack,webpack-cli和 webpack-dev-server:
npm i webpack webpack-cli webpack-dev-server --save-dev
要运行 webpack,只需要在 package.json 配置如下命令即可:
"scripts": {
"dev": "webpack --mode development"
},
通过这个脚本,我们指导webpack在开发模式下工作,方便在本地工作。
Webpack 的第一步
在开发模式下运行 webpack:
npm run dev
运行完后会看到如下错误:
ERROR in Entry module not found: Error: Can't resolve './src'
webpack 在这里寻找默认入口点src/index.js,所以我们需要手动创建一下,并输入一些内容:
mkdir src
echo 'console.log("Hello webpack!")' > src/index.js
现在再次运行npm run dev,错误就没有了。 运行的结果生成了一个名为dist/的新文件夹,其中包含一个名为main.js的 JS 文件:
dist
└── main.js
这是我们的第一个webpack包,也称为output。
配置 Webpack
对于简单的任务,webpack无需配置即可工作,但是很快我们就会遇到问题,一些文件如果没有指定的 loader 是没法打包的。所以,我们需要对 webpack进行配置,对于 webpack 的配置是在 webpack.config.js 进行的,所以我们需要创建该文件:
touch webpack.config.js
Webpack 用 JavaScript 编写,并在无头 JS 环境(例如Node.js)上运行。 在此文件中,至少需要一个module.exports,这是的 Common JS 导出方式:
module.exports = {
//
};
在webpack.config.js中,我们可以通过添加或修改来改变webpack的行为方式
entry point
output
loaders
plugins
code splitting
例如,要更改入口路径,我们可以这样做
const path = require("path");
module.exports = {
entry: { index: path.resolve(__dirname, "source", "index.js") }
};
现在,webpack 将在source/index.js中查找要加载的第一个文件。 要更改包的输出路径,我们可以这样做:
const path = require("path");
module.exports = {
output: {
path: path.resolve(__dirname, "build")
}
}
这样,webpack将把最终生成包放在build中,而不是dist.(为了简单起见,在本文中,我们使用默认配置)。
打包 HTML
没有HTML页面的Web应用程序几乎没有用。 要在webpack中使用 HTML,我们需要安装一个插件html-webpack-plugin:
npm i html-webpack-plugin --save-dev
一旦插件安装好,我们就可以对其进行配置:
const HtmlWebpackPlugin = require("html-webpack-plugin");
const path = require("path");
module.exports = {
plugins: [
new HtmlWebpackPlugin({
template: path.resolve(__dirname, "src", "index.html")
})
]
};
这里的意思是让 webpack,从 src/index.html 加载 HTML 模板。
html-webpack-plugin的最终目标有两个:
加载 html 文件
它将bundle注入到同一个文件中
接着,我们需要在 src/index.html 中创建一个简单的 HTML 文件:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Webpack tutorial</title>
</head>
<body>
</body>
</html>
稍后,我们会运行这个程序。
webpack development server
在本文第一部分中,我们安装了webpack-dev-server。如果你忘记安装了,现在可以运行下面命令安装一下:
npm i webpack-dev-server --save-dev
webpack-dev-server 可以让开发更方便,不需要改动了文件就去手动刷新文件。 配置完成后,我们可以启动本地服务器来提供文件。
要配置webpack-dev-server,请打开package.json并添加一个 “start” 命令:
"scripts": {
"dev": "webpack --mode development",
"start": "webpack-dev-server --mode development --open",
},
有了 start 命令,我们来跑一下:
npm start
运行后,默认浏览器应打开。 在浏览器的控制台中,还应该看到一个 script 标签,引入的是我们的 main.js。
clipboard.png
使用 webpack loader
Loader是第三方扩展程序,可帮助webpack处理各种文件扩展名。 例如,有用于 CSS,图像或 txt 文件的加载程序。
下面是一些 loader 配置介绍:
module.exports = {
module: {
rules: [
{
test: /\.filename$/,
use: ["loader-b", "loader-a"]
}
]
},
//
};
相关配置以module 关键字开始。 在module内,我们在rules内配置每个加载程序组或单个加载程序。
对于我们想要作为模块处理的每个文件,我们用test和use配置一个对象
{
test: /\.filename$/,
use: ["loader-b", "loader-a"]
}
test 告诉 webpack “嘿,将此文件名视为一个模块”。 use 定义将哪些 loaders 应用于些打包的文件。
打包 CSS
要 在webpack 中打包CSS,我们需要至少安装两个 loader。Loader 对于帮助 webpack 了解如何处理.css文件是必不可少的。
要在 webpack 中测试 CSS,我们需要在 src 下创建一个style.css文件:
h1 {
color: orange;
}
另外在 src/index.html 添加 h1 标签
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Webpack tutorial</title>
</head>
<body>
<h1>Hello webpack!</h1>
</body>
</html>
最后,在src/index.js 中加载 CSS:
在测试之前,我们需要安装两个 loader:
css-loader: 解析 css 代码中的 url、@import语法像import和require一样去处理css里面引入的模块
style-loader:帮我们直接将css-loader解析后的内容挂载到html页面当中
安装 loader:
npm i css-loader style-loader --save-dev
然后在webpack.config.js中配置它们
const HtmlWebpackPlugin = require("html-webpack-plugin");
const path = require("path");
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: ["style-loader", "css-loader"]
}
]
},
plugins: [
new HtmlWebpackPlugin({
template: path.resolve(__dirname, "src", "index.html")
})
]
};
现在,如果你运行npm start,会看到样式表加载在HTML的头部:
clipboard.png
一旦CSS Loader 就位,我们还可以使用MiniCssExtractPlugin提取CSS文件
Webpack Loader 顺序很重要!
在webpack中,Loader 在配置中出现的顺序非常重要。以下配置无效:
//
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: ["css-loader", "style-loader"]
}
]
},
//
};
此处,“style-loader”出现在 “css-loader” 之前。 但是style-loader用于在页面中注入样式,而不是用于加载实际的CSS文件。
相反,以下配置有效:
module.exports = {
module: {
rules: [
{
test: /\.css$/,
use: ["style-loader", "css-loader"]
}
]
},
//
};
webpack loaders 是从右到左执行的。
打包 sass
要在 webpack 中测试sass,同样,我们需要在 src 目录下创建一个 style.scss 文件:
@import url("https://fonts.googleapis.com/css?family=Karla:weight@400;700&display=swap");
$font: "Karla", sans-serif;
$primary-color: #3e6f9e;
body {
font-family: $font;
color: $primary-color;
}
另外,在src/index.html中添加一些 Dom 元素:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Webpack tutorial</title>
</head>
<body>
<h1>Hello webpack!</h1>
<p>Hello sass!</p>
</body>
</html>
最后,将 sass 文件加载到src/index.js中:
import "./style.scss";
console.log("Hello webpack!");
在测试之前,我们需要安装几个 loader:
sass-loader:加载 SASS / SCSS 文件并将其编译为 CSS
css-loader: 解析 css 代码中的 url、@import语法像import和require一样去处理css里面引入的模块
style-loader:帮我们直接将css-loader解析后的内容挂载到html页面当中
安装 loader:
npm i css-loader style-loader sass-loader sass --save-dev
然后在webpack.config.js中配置它们:
const HtmlWebpackPlugin = require("html-webpack-plugin");
const path = require("path");
module.exports = {
module: {
rules: [
{
test: /\.scss$/,
use: ["style-loader", "css-loader", "sass-loader"]
}
]
},
plugins: [
new HtmlWebpackPlugin({
template: path.resolve(__dirname, "src", "index.html")
})
]
};
注意loader的出现顺序:首先是sass-loader,然后是css-loader,最后是style-loader。
现在,运行npm start,你应该会在HTML的头部看到加载的样式表:
clipboard.png
打包现代 JavaScrip
webpack 本身并不知道如何转换JavaScript代码。 该任务已外包给babel的第三方 loader,特别是babel-loader。
babel是一个JavaScript编译器和“编译器”。 babel 可以将现代JS(es6, es7...)转换为可以在(几乎)任何浏览器中运行的兼容代码。
同样,要使用它,我们需要安装一些 Loader:
babel-core :把 js 代码分析成 ast ,方便各个插件分析语法进行相应的处理
babel-preset-env:将现代 JS 编译为ES5
babel-loader :用于 webpack
引入依赖关系
npm i @babel/core babel-loader @babel/preset-env --save-dev
接着,创建一个新文件babel.config.json配置babel,内容如下:
{
"presets": [
"@babel/preset-env"
]
}
最后在配置一下 webpack :
const HtmlWebpackPlugin = require("html-webpack-plugin");
const path = require("path");
module.exports = {
module: {
rules: [
{
test: /\.scss$/,
use: ["style-loader", "css-loader", "sass-loader"]
},
{
test: /\.js$/,
exclude: /node_modules/,
use: ["babel-loader"]
}
]
},
plugins: [
new HtmlWebpackPlugin({
template: path.resolve(__dirname, "src", "index.html")
})
]
};
要测试转换,可以在 src/index.js中编写一些现代语法:
import "./style.scss";
console.log("Hello webpack!");
const fancyFunc = () => {
return [1, 2];
};
const [a, b] = fancyFunc();
现在运行npm run dev来查看dist中转换后的代码。 打开 dist/main.js并搜索“fancyFunc”:
\n\nvar fancyFunc = function fancyFunc() {\n return [1, 2];\n};\n\nvar _fancyFunc = fancyFunc(),\n _fancyFunc2 = _slicedToArray(_fancyFunc, 2),\n a = _fancyFunc2[0],\n b = _fancyFunc2[1];\n\n//# sourceURL=webpack:///./src/index.js?"
没有babel,代码将不会被转译:
\n\nconsole.log(\"Hello webpack!\");\n\nconst fancyFunc = () => {\n return [1, 2];\n};\n\nconst [a, b] = fancyFunc();\n\n\n//# sourceURL=webpack:///./src/index.js?");
注意:即使没有babel,webpack也可以正常工作。 仅在执行 ES5 代码时才需要进行代码转换过程。
在 Webpack 中使用 JS 的模块
webpack 将整个文件视为模块。 但是,请不要忘记它的主要目的:加载ES模块。
ECMAScript模块(简称ES模块)是一种JavaScript代码重用的机制,于2015年推出,一经推出就受到前端开发者的喜爱。在2015之年,JavaScript 还没有一个代码重用的标准机制。多年来,人们对这方面的规范进行了很多尝试,导致现在有多种模块化的方式。
你可能听说过AMD模块,UMD,或CommonJS,这些没有孰优孰劣。最后,在ECMAScript 2015中,ES 模块出现了。
我们现在有了一个“正式的”模块系统。
要在 webpack 使用 ES module ,首先创建 src/common/usersAPI.js 文件:
const ENDPOINT = "https://jsonplaceholder.typicode.com/users/";
export function getUsers() {
return fetch(ENDPOINT)
.then(response => {
if (!response.ok) throw Error(response.statusText);
return response.json();
})
.then(json => json);
}
在 src/index.js中,引入上面的模块:
import { getUsers } from "./common/usersAPI";
import "./style.scss";
console.log("Hello webpack!");
getUsers().then(json => console.log(json));
生产方式
如前所述,webpack有两种操作模式:开发(development )和(production)。 到目前为止,我们仅在开发模式下工作。
在开发模式中,为了便于代码调试方便我们快速定位错误,不会压缩混淆源代码。相反,在生产模式下,webpac k进行了许多优化:
使用 TerserWebpackPlugin 进行缩小以减小 bundle 的大小
使用ModuleConcatenationPlugin提升作用域
在生产模式下配 置webpack,请打开 package.json 并添加一个“ build” 命令:
现在运行 npm run build,webpack 会生成一个压缩的包。
Code splitting
代码拆分(Code splitting)是指针对以下方面的优化技术:
避免出现一个很大的 bundle
避免重复的依赖关系
webpack 社区考虑到应用程序的初始 bundle 的最大大小有一个限制:200KB。
在 webpack 中有三种激活 code splitting 的主要方法:
有多个入口点
使用 optimization.splitChunks 选项
动态导入
第一种基于多个入口点的技术适用于较小的项目,但是从长远来看它是不可扩展的。这里我们只关注第二和第三种方式。
Code splitting 与 optimization.splitChunks
考虑一个使用Moment.js 的 JS 应用程序,Moment.js是流行的时间和日期JS库。
在项目文件夹中安装该库:
npm i moment
现在清除src/index.js的内容,并引入 moment 库:
import moment from "moment";
运行 npm run build 并查看控制的输出内容:
main.js 350 KiB 0 [emitted] [big] main
整个 moment 库都绑定到了 main.js 中这样是不好的。借助optimization.splitChunks,我们可以从主包中移出moment.js。
要使用它,需要在 webpack.config.js 添加 optimization 选项:
const HtmlWebpackPlugin = require("html-webpack-plugin");
const path = require("path");
module.exports = {
module: {
// ...
},
optimization: {
splitChunks: { chunks: "all" }
},
// ...
};
运行npm run build 并查看运行结果:
main.js 5.05 KiB 0 [emitted] main
vendors~main.js 346 KiB 1 [emitted] [big] vendors~main
现在,我们有了一个带有moment.js 的vendors〜main.js,而主入口点的大小更合理。
注意:即使进行代码拆分,moment.js仍然是一个体积较大的库。 有更好的选择,如使用luxon或date-fns。
Code splitting 与 动态导入
Code splitting的一种更强大的技术使用动态导入来有条件地加载代码。 在ECMAScript 2020中提供此功能之前,webpack 提供了动态导入。
这种方法在 Vue 和 React 之类的现代前端库中得到了广泛使用(React有其自己的方式,但是概念是相同的)。
Code splitting 可用于:
模块级别
路由级别
例如,你可以有条件地加载一些 JavaScript 模块,以响应用户的交互(例如单击或鼠标移动)。 或者,可以在响应路由更改时加载代码的相关部分。
要使用动态导入,我们先清除src/index.html,并写入下面的内容:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Dynamic imports</title>
</head>
<body>
<button id="btn">Load!</button>
</body>
</html>
在 src/common/usersAPI.js中:
const ENDPOINT = "https://jsonplaceholder.typicode.com/users/";
export function getUsers() {
return fetch(ENDPOINT)
.then(response => {
if (!response.ok) throw Error(response.statusText);
return response.json();
})
.then(json => json);
}
在 src/index.js 中
const btn = document.getElementById("btn");
btn.addEventListener("click", () => {
//
});
如果运行npm run start查看并单击界面中的按钮,什么也不会发生。
现在想象一下,我们想在某人单击按钮后加载用户列表。 “原生”的方法可以使用静态导入从src/common /usersAPI.js加载函数:
import { getUsers } from "./common/usersAPI";
const btn = document.getElementById("btn");
btn.addEventListener("click", () => {
getUsers().then(json => console.log(json));
});
问题在于ES模块是静态的,这意味着我们无法在运行时更改导入的内容。
通过动态导入,我们可以选择何时加载代码
const getUserModule = () => import("./common/usersAPI");
const btn = document.getElementById("btn");
btn.addEventListener("click", () => {
getUserModule().then(({ getUsers }) => {
getUsers().then(json => console.log(json));
});
});
这里我们创建一个函数来动态加载模块
const getUserModule = () => import("./common/usersAPI");
现在,当你第一次使用npm run start加载页面时,会看到控制台中已加载 js 包:
clipboard.png
现在,仅在单击按钮时才加载/common/usersAPI:
clipboard.png
对应的 chunk 是 0.js
通过在导入路径前面加上魔法注释/ * webpackChunkName:“ name_here” * /,可以更改块名称:
const getUserModule = () =>
import(/* webpackChunkName: "usersAPI" */ "./common/usersAPI");
const btn = document.getElementById("btn");
btn.addEventListener("click", () => {
getUserModule().then(({ getUsers }) => {
getUsers().then(json => console.log(json));
});
});
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
准备工作
//借助插件
npm install babel-plugin-import --save-dev
// .babelrc
{
"plugins": [["import", {
"libraryName": "view-design",
"libraryDirectory": "src/components"
}]]
}
在main.js中引入
import "view-design/dist/styles/iview.css";
import { Button, Table } from "view-design";
const viewDesign = {
Button: Button,
Table: Table
};
Object.keys(viewDesign).forEach(element => {
Vue.component(element, viewDesign[element]);
});
先用google浏览器打开正常,以上操作猛如虎,IE浏览器打开250,好了不废话,下面是解决方案
解决方案
//vue.config.js中配置
chainWebpack: config => {
//解决iview 按需引入babel转换问题
config.module
.rule("view-design") // 我目前用的是新版本的iview ,旧版本的iview,用iview代替view-design
.test(/view-design.src.*?js$/)
.use("babel")
.loader("babel-loader")
.end();
}
问题原因
为什么会有如上问题呢? 这个就和babel转换问题有关了,按需引入时,那些组件里js文件未进行babel转换或转换不彻底就被引入了,ie11对es6+的语法支持是很差的,所以以上方法就是让引入文件前就对view-design的src下的所有js文件进行babel转换,举一反三,当按需引入第三方框架时出现这个问题,都可用这方法解决了,只要把规则和正则中view-design进行替换。
延伸扩展
//全局引入
import ViewUI from "view-design";
Vue.use(ViewUI);
import "view-design/dist/styles/iview.css";
tips:在全局引入时,一定要记住不要在.babelrc文件里配置按需导入,会导致冲突
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
用户隐私安全在产品设计中是很重要的一个环节,本文从用户体验角度切入,从匿名模式、减少永久性和减少公开性三个方面展开分析。
我们先看⼀组来⾃⽪优的2019年6⽉的调研数据:70%的美国⼈认为,与5年前相⽐个⼈信息变得更不安全。尤其是⾼学历⾼收⼊群体。由此可⻅⽤户对个⼈信息数据的隐私担忧⽐以往更甚。
⽤户隐私安全很重要,涉及的范围和⻆度也很多。本次的分析从⽤户体验⻆度切⼊,涉及如下三个⽅⾯:
下图是Google系App(Google AppChromeYouTubeandGoogle Map)匿名模式切换,从交互体验上来说有如下⼏个特点:

匿名模式不是最近才流⾏的功能,最早提供隐匿模式的是苹果safari浏览器,早在 2005年就⽀持了匿名模式。Chrome浏览器在2008年就开始⽀持此模式。虽然由来已久,为什么到了2020年,匿名模式依然是国外互联⽹⼀⼤趋势呢?
我们看⼀组数据:
这是来⾃DuckDuckGo 2019年9⽉的调研(DuckDuckGo是美国的⼀款不记录⽤户⾏为保护⽤户隐私的搜索引擎)。样本来⾃美国、英国、德国和澳⼤利亚的成年⼈⽤户,共计3,411⼈的调研得出。各国⽤户对使⽤搜索引擎的个⼈隐私安全⾮常在意(是否搜集个⼈的数据和记录搜索⾏为)。
2020年5⽉DuckDuckGo⽇均搜索次数为6200万。对⽐看2019年11⽉底⽇均搜索次数4900万,2018年10⽉是2900万。
最近⼏年的持续活跃度⾼幅增⻓证明了不记录个⼈隐私的搜素引擎越来越受到⽤户的⻘睐。
国内,头条、UC浏览器在搜索框输⼊状态也提供了「⽆痕浏览」⼊⼝。
不仅是搜索引擎领域,保护⽤户隐私也成为Facebook最重要的战略⽅向之⼀。Facebook CEO Mark Zuckerberg在2019年 F8开发者⼤会上喊出「THE FUTURE IS PRIVATE」。2019年3⽉Mark Zuckerberg发⽂,主题就是《聚焦于保护隐私的社交⽹络》。

我们先看国外社交媒体Stories(⼩故事)产品形态的流⾏。
⼈们总是对于所分享的内容永远记录在⽹上感到担忧。Stories 24⼩时消失缓解了⼈们的隐私顾虑,这让⽤户更安⼼地⾃然分享。
Stories由Snapchat⾸创,由 Facebook发扬光⼤。早在2019年4⽉,Facebook+Messenger Stories, Instagram Stories⽇活⽤户数就突破5亿。 2020年2-3⽉LinkedIn,Twitter也先后宣布将上线类似功能。

来⾃⽪优的调研报告:41%的美国⼈经历过⽹络骚扰,最常⻅的就是在社交媒体上。23%的⽤户最近经历的⽹络骚扰来⾃评论区的评论内容。27%的⽤户经历⽹络骚扰后决定不再发布任何内容。

我们以限定评论互动的公开性为例:
2020年5⽉Twitter上线了新的评论功能,可以限定谁可以回复帖⼦的功能,提供了三种选项:谁都可以评论,只有被关注者可以评论,只有被提及者可以评论三种公开度的限定。
Instagram也在测试「评论限制」新功能,批量屏蔽/限制评论。⽬前已经上线的⼀个例⼦:⽤户(评论发布者)如果发布的评论含有攻击性敏感词,发布前伴有提示,提醒评论含有攻击性敏感词是否真的要发布。

注重隐私提供仅好友可⻅/仅⾃⼰可⻅/仅作者可⻅/等多重维度的隐私设定有助于⽤户更安⼼地参与互动。
另外⼀个例⼦是付费频道会员:付费频道会员-限定频道的公开性让内容创作者减轻隐私顾虑不仅能获得⼴告收⼊,也能得到来⾃会员、会费的收⼊,形成「忠实粉丝」社区,有助于内容⽣态的社区化建设。
我们主要看YouTube的频道会员案例:
YouTube有两种会员模式。⼀种是YouTube整个平台的付费会员,去⼴告,看原创美剧影视,消费⾳乐,可下载内容的模式。第⼆种模式是Youtuber个⼈频道付费会员,吸引忠实粉丝加⼊。我想说的就是第⼆种。

为什么⼤V⽹红有意愿开通频道会员?
除了获得忠实粉丝收⼊变现的商业价值以及付费频道会员可以为忠实粉丝提供各种专属功能,背后也和⽹红⼤V对个⼈隐私顾虑有关。
⽹红⼤V在完全公开的社交⽹络上需要始终保持⾜够克制谨慎,避免引起争议。但在忠实粉丝付费频道专属会员群中,⽹红⼤V会减轻隐私顾虑,更加回归⾃我。
⽐如在频道会员中发布更多与个⼈⽣活相关的内容,表达更多不便在完全公开的社交⽹络中的想法和感受等,因为忠实粉丝通常更具包容度,更不容易引起争议。
YouTube频道会员费⽤可以从三种会费(按⽉)区间选择,⽀持多选:
频道会员功能在2018年开始测试,⾯向粉丝数过10万的YouTuber开放。
以上综述,我们可以说:
1. 匿名模式:
虽然匿名模式由来已久,但仍然是当前的⼀⼤基本⽤户体验设计趋势,尤其是匿名模式的切换便捷性⾮常重要。
2. 减少永久性:
Stories⼩故事24⼩时消失缓解了⼈们的隐私顾虑,这让⽤户更安⼼地⾃然分享,已经成为国外社交媒体平台的必备功能,Facebook, Instagram平台的最主要、最具影响⼒的功能之⼀。
3. 减少公开性:
⽤户总是对在社交媒体平台发表评论有所顾忌,限定评论的公开性能够有助于促进⽤户发帖表达,其他⽤户也可以更安⼼地参与互动。
付费频道会员可以限定频道的公开性,让内容创作者减轻隐私顾虑不仅能获得⼴告收⼊,也能得到来⾃会员会费的收⼊,形成「忠实粉丝」社区,有助于内容⽣态的社区化建设。
从UE⻆度,我们可以为频道会员提供专属身份设计例如专属徽章,专属表情等。
THE FUTURE IS PRIVATE, 注重⽤户隐私的体验设计越来越重要!
文章来源:优设 作者:
百度MEUX
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
最近在项目中遇到这样一个问题

当页面加载完毕后由于选项卡的另外两张属于display:none;状态 所以另外两张选项卡内echarts的宽高都会变成默认100*100
查阅了很多网上的案例,得出一下一些解决方案:
1:
原因很简单,在tab页中,图表的父容器div是隐藏的(display:none),图表在执行js初始化的时候找不到这个元素,所以自动将“100%”转成了“100”,最后计算出来的图表就成了100px
解决办法:
找一个在tab页的切换操作中不会隐藏的父容器,把它的宽度的具体值取出后在初始化图表之前直接赋给图表
1 $("#chartMain").css('width',$("#TabContent").width());//获取父容器的宽度具体数值直接赋值给图表以达到宽度100%的效果 2 var Chart = echarts.init(document.getElementById('chartMain')); 3 4 // 指定图表的配置项和数据 5 option = { ...配置项和数据 }; 6 7 // 使用刚指定的配置项和数据显示图表。 8 Chart.setOption(option);
2:mychart.resize() 重新渲染高度
3: 后来我想到了问题所在,既然高度是因为display:none;导致的 那大可不必设置这个属性,但是在页面渲染完毕后加上即可
所以取消了选项卡的display:none; 但在页面加载完毕后
window.οnlοad=function(){
根基id在添加css display:none;
}
即可解决,
分割线
---------------------------------------------------------------------
接下来解决一下ifram内外通讯 互相通讯赋值ifram src 和高度问题
统一资源定位符,缩写为URL,是对网络资源(网页、图像、文件)的引用。URL指定资源位置和检索资源的机制(http、ftp、mailto)。
举个例子,这里是这篇文章的 URL 地址:
https://dmitripavlutin.com/parse-url-javascript
很多时候你需要获取到一段 URL 的某个组成部分。它们可能是 hostname(例如 dmitripavlutin.com),或者 pathname(例如 /parse-url-javascript)。
一个方便的用于获取 URL 组成部分的办法是通过 URL() 构造函数。
在这篇文章中,我将给大家展示一段 URL 的结构,以及它的主要组成部分。
接着,我会告诉你如何使用 URL() 构造函数来轻松获取 URL 的组成部分,比如 hostname,pathname,query 或者 hash。
1. URL 结构
一图胜千言。不需要过多的文字描述,通过下面的图片你就可以理解一段 URL 的各个组成部分:
image
2. URL() 构造函数
URL() 构造函数允许我们用它来解析一段 URL:
const url = new URL(relativeOrAbsolute [, absoluteBase]);
参数 relativeOrAbsolute 既可以是绝对路径,也可以是相对路径。如果第一个参数是相对路径的话,那么第二个参数 absoluteBase 则必传,且必须为第一个参数的绝对路径。
举个例子,让我们用一个绝对路径的 URL 来初始化 URL() 函数:
const url = new URL('http://example.com/path/index.html');
url.href; // => 'http://example.com/path/index.html'
或者我们可以使用相对路径和绝对路径:
const url = new URL('/path/index.html', 'http://example.com');
url.href; // => 'http://example.com/path/index.html'
URL() 实例中的 href 属性返回了完整的 URL 字符串。
在新建了 URL() 的实例以后,你可以用它来访问前文图片中的任意 URL 组成部分。作为参考,下面是 URL() 实例的接口列表:
interface URL {
href: USVString;
protocol: USVString;
username: USVString;
password: USVString;
host: USVString;
hostname: USVString;
port: USVString;
pathname: USVString;
search: USVString;
hash: USVString;
readonly origin: USVString;
readonly searchParams: URLSearchParams;
toJSON(): USVString;
}
上述的 USVString 参数在 JavaScript 中会映射成字符串。
3. Query 字符串
url.search 可以获取到 URL 当中 ? 后面的 query 字符串:
const url = new URL(
'http://example.com/path/index.html?message=hello&who=world'
);
url.search; // => '?message=hello&who=world'
如果 query 参数不存在,url.search 默认会返回一个空字符串 '':
const url1 = new URL('http://example.com/path/index.html');
const url2 = new URL('http://example.com/path/index.html?');
url1.search; // => ''
url2.search; // => ''
3.1 解析 query 字符串
相比于获得原生的 query 字符串,更实用的场景是获取到具体的 query 参数。
获取具体 query 参数的一个简单的方法是利用 url.searchParams 属性。这个属性是 URLSearchParams 的实例。
URLSearchParams 对象提供了许多用于获取 query 参数的方法,如get(param),has(param)等。
下面来看个例子:
const url = new URL(
'http://example.com/path/index.html?message=hello&who=world'
);
url.searchParams.get('message'); // => 'hello'
url.searchParams.get('missing'); // => null
url.searchParams.get('message') 返回了 message 这个 query 参数的值——hello。
如果使用 url.searchParams.get('missing') 来获取一个不存在的参数,则得到一个 null。
4. hostname
url.hostname 属性返回一段 URL 的 hostname 部分:
const url = new URL('http://example.com/path/index.html');
url.hostname; // => 'example.com'
5. pathname
url. pathname 属性返回一段 URL 的 pathname 部分:
const url = new URL('http://example.com/path/index.html?param=value');
url.pathname; // => '/path/index.html'
如果这段 URL 不含 path,则该属性返回一个斜杠 /:
const url = new URL('http://example.com/');
url.pathname; // => '/'
6. hash
最后,我们可以通过 url.hash 属性来获取 URL 中的 hash 值:
const url = new URL('http://example.com/path/index.html#bottom');
url.hash; // => '#bottom'
当 URL 中的 hash 不存在时,url.hash 属性会返回一个空字符串 '':
const url = new URL('http://example.com/path/index.html');
url.hash; // => ''
7. URL 校验
当使用 new URL() 构造函数来新建实例的时候,作为一种副作用,它同时也会对 URL 进行校验。如果 URL 不合法,则会抛出一个 TypeError。
举个例子,http ://example.com 是一段非法 URL,因为它在 http 后面多写了一个空格。
让我们用这个非法 URL 来初始化 URL() 构造函数:
try {
const url = new URL('http ://example.com');
} catch (error) {
error; // => TypeError, "Failed to construct URL: Invalid URL"
}
因为 http ://example.com 是一段非法 URL,跟我们想的一样,new URL() 抛出了一个 TypeError。
8. 修改 URL
除了获取 URL 的组成部分以外,像 search,hostname,pathname 和 hash 这些属性都是可写的——这也意味着你可以修改 URL。
举个例子,让我们把一段 URL 从 red.com 修改成 blue.io:
const url = new URL('http://red.com/path/index.html');
url.href; // => 'http://red.com/path/index.html'
url.hostname = 'blue.io';
url.href; // => 'http://blue.io/path/index.html'
注意,在 URL() 实例中只有 origin 和 searchParams 属性是只读的,其他所有的属性都是可写的,并且会修改原来的 URL。
9. 总结
URL() 构造函数是 JavaScript 中的一个能够很方便地用于解析(或者校验)URL 的工具。
new URL(relativeOrAbsolute [, absoluteBase]) 中的第一个参数接收 URL 的绝对路径或者相对路径。当第一个参数是相对路径时,第二个参数必传且必须为第一个参数的基路径。
在新建 URL() 的实例以后,你就能很轻易地获得 URL 当中的大部分组成部分了,比如:
url.search 获取原生的 query 字符串
url.searchParams 通过 URLSearchParams 的实例去获取具体的 query 参数
url.hostname获取 hostname
url.pathname 获取 pathname
url.hash 获取 hash 值
那么你最爱用的解析 URL 的 JavaScript 工具又是什么呢?
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
随着车内屏幕越来越多,越来越大,驾驶者在开车过程中因操作屏幕而分心机率逐渐升高。众多汽车制造商均希望探索出一种降低或避免「驾驶员分心」的安全性技术。
手势,是指人手、手和手臂结合产生的动作,作为解决「驾驶者分神」这个痛点的解决方案之一,正在全世界的汽车制造商中掀起「热浪」。
你只需要随意的挥一挥手,就能挂断电话;将手指向顺时针或者逆时针方向移动,就能调整音量大小。
汽车手势的出现,源于对车内屏幕的操作。而这些操作均来自于移动端的设计标准,比如苹果IOS设计规范中的标准手势或者谷歌Mertiral Design中的标准手势。

△ 移动端常见交互手势
常见的手势如上图,分别为
为了满足手机屏幕外观改变,屏内显示内容越来越多元化的需求,设计师们也在探索屏内手势的新玩法。

△ android底部导航栏按键从左至右分别为:返回上一级、返回主页、多任务
2017年iPhoneX的发布,正式开启了全面屏时代。为了替代Home键及android底部导航栏,各大手机厂商相继开始拥抱「全面屏手势交互」。
在车机系统中,部分汽车制造商也在积极迎接变化,比如理想one采用「三指下滑」的手势交互替代「返回主页」的图标按键。

△ 「 三指下滑」表示返回主页
2019年的Google I/O大会上,新版本Android Q选择与IOS采用一样的手势操作逻辑,即在屏幕下方提供一个指示条,用户在左侧页面边缘右滑代表「返回上一级」、提示条区域上滑代表「返回主页」、提示条区域上滑并悬停代表「多任务」。

△ android系统中的三种全面屏手势
随着全面屏手势在手机端的操作交互上达成一致,相信在不久的将来,也将越来越频繁的在车机端看到全面屏手势的「身影」。
当汽车与数字屏幕相遇,如何让屏幕与内饰结合的更加完美,又能突显品牌特性,似乎给内饰设计师带来了许多挑战与机遇,「一字屏」、「T字屏」、「7字屏」、「旋转屏」应运而生。

△ 拜腾M-Byte 一字屏

△ 理想one的T字屏

△ 合创007的7字屏

△ 比亚迪王朝系列的旋转屏
与此同时,因为成本及技术的限制,汽车制造商的量产车型不得不在屏幕上做出妥协。理想one的妥协方案是利用3块屏幕组合,在视觉上形成「大长屏」的既视感。

要让3块屏幕「变」成一块屏幕,仅仅在视觉上做足功夫显然还不够,多屏联动手势交互也不能「缺席」。
事实上,多屏联动手势交互依旧来源于IOS及android系统中的标准手势,它将不同的手势进行组合,并与页面联动显示,形成了多屏联动手势。
理想one在停车模式下,用户长按并向左滑动,即可将副驾娱乐屏上的信息「甩动」至中控屏。

天际ME7不仅有3块屏幕组合而成的前排「一字屏」,还有2块后排乘客娱乐屏,5屏联动的手势交互,天际采用「手势+屏幕显示」来解决。

在中控屏、副驾娱乐屏和后排娱乐屏上采用五指抓取手势进入多屏互动页面,比如想把中控屏上的内容分享给副驾娱乐屏,第一步是单击选中副驾娱乐屏,第二步按住并拖动中控屏至副驾娱乐屏位置,第三步在副驾娱乐屏中点击确认。
视频版交互演示:https://v.qq.com/x/page/w08791lhqus.html
通过隔空手势接听或者挂断电话,这似乎是科幻电影中才有的情节。但正如开篇所说,车内屏幕数量增多,尺寸加大的同时「驾驶者分心」的机率也增加了,盲操手势与隔空手势的出现,是解决这个痛点的一种尝试。
目前量产的汽车中,盲操手势主要是通过标准手势与声音反馈的组合来实现。
比如在理想one中,用户在空调屏上左右滑动可以调节风量,上下滑动调节温度,且系统通过声音反馈告知用户操作成功与否。
与盲操手势相比,隔空手势似乎科技感十足,备受汽车制造商的青睐,我们不仅可以在各种概念车上窥见它的踪影,在君马SEEK上,也可以实际操作一番。
君马SEEK提供8种隔空手势。

△ 左图:接听电话 右图:挂断电话

△ 左图:上一曲 右图:下一曲

△ 左图:音量升高 右图:音量降低

△ 左图:音乐播放/暂停 右图:玫瑰花
与君马SEEK相同,宝马提供「向左」手势代表上一曲、「向右」手势代表下一曲,「yeah」手势代表播放或暂停。
但在许多其他操作上,宝马与君马的手势操作则各有特色。
君马SEEK使用手掌的正面与反面来区分不同的操作,正面表示接听电话·/音量增加,反面表示拒听/音量降低。
宝马则选择向屏幕方向点击代表接听电话,手掌向右挥动代表拒听电话,手指顺时针画圈代表音量增加,手指逆时针画圈代表音量降低。
在倒车影像中,手指向右挥动代表调整视角。

△ 图片来源于「汽车界的扛把子」的短视频《宝马手势控制详细演示》
在手势交互上,拜腾也交出了自己的「成绩单」。
拜腾的手势识别共五种,手掌向下激活手势识别,手掌向上启动主页面,手指移动代表移动光标,ok手势代表确定,五指捏合可拖拽内容。

△ 图片来源于太平洋汽车网《拜腾Concept手势感应系统操作演示》
这些高大上的技术看起来令人兴奋,但在实际使用的过程中,依旧存在识别范围有限、识别精度不灵敏、识别后的响应速度慢等等问题,而各个厂家的手势识别没有形成统一的标准,且没有大规模在在用户中进行推广,必然会增加用户的学习成本。
手势识别对用户来说是「真香」还是「鸡肋」,相信时间会给出答案。
参考文献:
汽车内手势的交互设计,是一个有趣又好玩的课题,但如何让这个课题在好玩但同时易用、好用,恐怕只有设计师不断思考,并不断采用一些用户测试的方法进行验证才能获得答案。
文章来源:优设 作者:点滴DESIGN
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
宋体字可以说是我们现在最常用的字体之一,一方面他与黑体一样,具有非常良好的可读性和易辨性,另一方面,他又比黑体更具有历史感和东方韵味,我们可以看到很多的教材、书籍内文或者官方文件,都是用的宋体字,甚至许多设计都会用一些比较有表现力的宋体字作为标题。所以可想而知,学习设计宋体字对我们的帮助有多大。正所谓欲知大道,必先知史。所以在讲如何设计宋体字之前,我们先来扒一扒宋体字的历史吧。

虽然说宋体字叫做宋体字,但是如果要追溯宋体字的起源,我们还得从唐朝说起。

唐朝时期,佛教在中国开始盛行开来,唐朝皇帝甚至派出唐僧师徒四人前往西天取经。

于是便出现了「抄经生」这种人肉印刷机。这篇经文便是当时唐朝的抄经生所抄写的,他们需要使用规整统一的楷体,文字的开头在同一水平线,而且每一列的字数统一规定为17或者19个字,方便字数的统计,像这一篇经文每一列就是17个字。

可是即便出现了大量的抄经生,依旧满足不了人们对经书的需求。于是聪明的中国人开始印刷经书,将经文刻在木板上,就可以实现大量的印刷了。

可是楷书刻起来是很不方便的。一方面,书法家写的楷书讲究起承转合、抑扬顿挫,不同的人写出来的字风格差异十分明显,例如颜真卿和赵孟頫他们所写的「宋」字就明显不同,即便用笔临摹都很难了,更别说雕刻出来了。

另一方面楷体由于是书写的字体,所以大多数笔画都是带有弧度的,而在木板上刻字,曲线是非常难刻的。


于是他们逐渐将曲线刻成直线,把笔画的弧形特征降低,也将楷体中相同的笔画进行规范了,这样的字体便是宋体字的前身。


我们可以看一下宋朝时期的刻本,这是南宋时期陈宅经籍铺所刊刻的《朱庆馀诗集》。这时,撇、捺等笔画的弯曲程度大大降低了,而竖笔和横笔也基本上变成笔直的直线了。不过宋朝时期刻本体的横画依旧是倾斜的,从中依然能很明显地看到楷体的痕迹。那么为什么宋体字会形成横细竖粗,横画后带三角形饰角的字形呢?

那是因为刻字的木板上是带有木纹的,如果垂直木头的纹理刻的话,笔画会比较容易断,需要加粗一些。而如果是顺着木纹刻的话,就没那么容易断,所以可以相对细一些。可是为什么是横画细,竖画粗呢?反过来不行吗。

那是因为在大多数的汉字中,横画都是比竖画多的。上海交大的郭曙纶教授对20902个汉字进行了统计,发现这些汉字的总笔画数量多达268479个,而其中横画有82682个,占30.8%,而竖画有51459个,占19.2%。可见,在汉字中横画是比竖画多的。所以如果将横画刻粗,竖画刻细的话,可能会使得字体过挤而不美观。

虽然说横画顺着木纹,比较不容易断,可是横画的两端还是会比较容易磨损的,所以工匠们一般会将横画的两端稍微刻大一些,形成饰角。

在明朝,宋体得到了进一步的简化,原本复杂精细的刀刻技法简化成了横、竖和斜三种,所以刻字工匠的门槛大大降低了,宋体字得到了真正的普及。我们同样来看一下明朝时期的刻本,这是明朝时期汲古阁刻印的《道德指归论》,这个时候的宋体横画已经基本变成水平了,虽然笔画依旧比较张扬,但是已经少了许多楷体的影子。所以从明朝时期开始的刻本体才能算作真正的宋体。

也是在明朝时期,宋体字传到了日本,所以现在日本将宋体字称为明朝体。

清朝是刻本最多的一个朝代,而宋体字在中国真正被确定统一称为「宋体字」也是发生在清朝。


了解了宋体字的历史后,我们可以发现宋体字的意义并非只是美观和易读而已,他是经过中华民族近千年传承、优化和改良的文化结晶,他的身上有着厚重的文化气息。也难怪中国、日本、韩国等受中华文化影响的国家会对宋体有独特的偏爱。接着我们就正式进入设计宋体字的教程部分,首先我们来了解一下宋体字的主要特征。

从楷体字转变为宋体,主要产生了三个特征,第一个是横平竖直,也就是说横画是水平的,竖画是垂直的。第二个特征是横画比较细,竖画比较粗。第三个特征是笔画上出现了三角形的装饰角。

可是随着字体设计的发展,对于宋体的定义已经越来越模糊了。例如上面的这三种字体,虽然他们不完全满足宋体的特征,可是它们都能算作是宋体。所以我们也不需要对宋体下一个死定义,免得我们在设计字体的时候被定义所束缚住了。

可是仿宋体是不能够算是宋体字的。我们看仿宋体是不是觉得他和宋朝时期的刻本非常像呢?因为仿宋体是在民国时期,丁善之和丁辅之模仿宋刻本所设计出来的字体,所以仿宋体模仿的是宋朝刻本,而非宋体字,那么仿宋体当然也就不能算在宋体的行列里了。

接着我们来分析一下宋体字的气质。由于宋体诞生于明朝,具有非常悠长的历史,而黑体是在民国时期才产生的,所以宋体相对于黑体更能体现传统感、文化感的气质属性。

所以我们做现代风格的设计的时候,可以使用黑体。

而做比较具有传统风格的设计则可以用宋体。当然也并非说宋体就没办法做现代感的设计,通过对宋体体饰和中宫的设计,我们完全可以做出一款现代型的宋体。

先来说一下中宫,我们在之前的教程里说过,中宫越大,越显现代感,而中宫越小,则越有传统感。在宋体里也不例外。

我们再来看看这两个「東」字,很明显也是左边的「東」字更现代一些,而右边的「東」字传统一些。这两个字的区别在于体饰的不同。体饰越少越简洁,宋体就越显现代;体饰越多越复杂,就越显传统。

另外几何形的体饰也会给宋体带来现代感。

而传统宋体字的体饰则是具有手写感的,线条比较圆滑。

根据体饰和中宫的不同,我们可以大致地将宋体分为三大类。中宫小、体饰多且具有手写感的宋体归类为传统型宋体,中宫大、体饰少且为几何体饰的则归类为现代型宋体。而具有一定手写感的体饰,且中宫偏大的宋体,则归类为中间型的宋体。

除了中宫和体饰之外,我们还经常调整笔画粗细去适应宋体字不同的用途。首先我们先来讲讲正文的宋体。一般正文的字号都是比较小的,如果横画过细的话,会使得横画几乎看不见了,而如果横画过粗的话,笔画又会糊在一块了,所以为了让宋体字在小字号下也能清晰的显示,一般横画和竖画的粗细会控制在1:2到1:3左右,最大一般也不会超过1:4。

不过我们设计正文字体的机会还是比较少的,大多数时候我们都是需要设计比较具有张力的标题字。这个时候我们就可以尝试拉大横画和竖画的粗细差距。当横画和竖画的粗细差距非常大的时候,可以产生较强的视觉冲击力。画面中这三款标题宋体,都用了细横画搭配粗竖画。

有时候我们也可以反其道而行之,将横画加粗,让横画与竖画差不多的粗细。这样我们就可以获得一款非常醒目的宋体。这样的宋体有点像比较粗的黑体,既有醒目的特点,也保留了宋体优雅的属性。

当然,具有张力的标题宋体也并非一定要通过控制横竖笔画的粗细来塑造,通过设计一些有张力的体饰,同样可以让宋体字变得具有表现力。设计体饰是设计宋体字非常重要的一个环节,因为宋体字的大多数笔画是存在许多体饰的,我们除了要将体饰设计得好看之外,更重要的是让不同的体饰和谐共存。如果一个宋体字里存在的体饰都风格不一,那么这个宋体字看着就会不伦不类了。下面我就给大家介绍一个我比较常用的,设计宋体字体饰的方法。

在做字之前,我们要先确定我们想要做的字体的气质,是传统的,还是现代的?文艺的还是可爱的?又或者是其他的气质。因为我们前面也说到,体饰和中宫都会影响字体的气质,所以我们必须要确定了气质之后,才能动手去设计字体的中宫和体饰。

另外还要确定字体的用途,需要比较有张力的标题字体,还是需要具备阅读舒适性的正文字体,那我们也能确定文字的笔画粗细。

确定好了风格之后,我们就可以开始设计笔画了。那么我们先来回顾一下,汉字里的八个基本笔画,我们可以先把这八个笔画的体饰特征都设计好了,再去拼凑我们想要的字。

一般来说,我们设计宋体会先从横画开始设计。因为确定了横画之后,体饰的风格、体饰大小、笔画粗细等很多东西就都可以确定了。

其实宋体中的体饰都是来源于书法中的顿笔,所以我们来看看书法中,横画是怎么写的,书法中的横在起笔和收笔处分别有一个顿笔。这两个顿笔分别对应着宋体横画首尾的两处体饰。对于宋体字来说,横画末尾的这个体饰是非常重要的,他对整个字体的气质影响非常的大。

我们前面已经介绍了这两种衬角分别具有现代感和传统感。

而这一个的衬角是一个比较圆润的圆形,他可以用来做比较可爱的宋体。

这一个衬角和刚刚的就正好相反,非常的非常尖锐,适合用来做比较恐怖的宋体。

还有一点要注意的是,如果竖画越粗的话,横画的衬角一般也要相应的变大一些。

因为宋体的横画本来就已经很细了,如果衬角还非常小的话,横画很容易就会被忽略掉了,横画末端的这个三角形起到了一定强调横线的作用。当然如果是故意要设计成小衬角或者无衬角的话就另当别论了。

横画做好之后,就可以开始设计竖画了。在书法中,竖画在起笔处会有一个顿笔,而收笔的地方会稍微往左侧偏一些,这样分别形成了宋体中竖画起笔和收笔的两处体饰。

那么我们应该怎么用横画推导出竖画呢?横画和竖画关联度最大的地方在横画三角形衬角和竖画上方衬角的这个地方。例如这一组都是直线加切角。

而这组都是曲线加圆角。

另外我们还能将这两个地方给联系起来,因为他们都是起笔的位置。如果横画的起笔是水平的话,那么竖画的起笔就应该是垂直的。

而如果横画的起笔是往外扩的话,那么竖画的起笔也可以往外扩张。

我一般还会将竖画的起笔和收笔的的地方关联起来,如果起笔是垂直的,那么收笔我也会设置成垂直的。

而如果起笔往外扩的话,那么收笔我也会往外扩形成书写曲线,这样整个竖画能看起来平衡一些。

接着来设计横折。书法中在这个转折的地方会有一个顿笔。所以在宋体的横折处也会形成一个装饰角。

其实横折这个笔画在设计好横画和竖画之后基本就已经出来了。只要将他们组合在一起,然后将横画的衬角往回缩小一些,横折就做好了。

讲完了横折我们顺便也讲一下这种口字的结构好了。口字结构由刚刚做好的横折加上一个竖线和一个去掉三角衬角的横线组成。然后我们需要做一些细微的调整。竖笔体饰的这个地方需要往上收一些,不要漏出来,这样的笔画看着能干净一些。

然后竖画入笔的地方也要往上提一些,让左右两边的体饰能够平衡。

最后加上横画,把衬角的部分裁去,注意两个竖线需要出头一些。这个口字就完成了。

然后来做撇和捺。书法里的撇起笔的地方有一个顿笔,所以宋体里,撇有一处体饰。

书法里捺则在起笔和收笔处各有一处转折。所以宋体里,捺则有两处体饰。

撇基本上可以从竖线轻易地推导出来,因为他们的起笔都是一样的,只要稍微调整一下起笔的角度就可以了。

而捺与撇是正好相反的,起笔细,收笔粗,所以捺的起笔需要缩小一些,但是需要保证这两个地方是相同的。而捺的收笔是一个比较独立的地方,只需要风格保持大致一致就好了。

接着来做提。在书法中,提的起笔一般是会有一个顿笔的,这一个顿笔与竖的起笔的顿笔是类似,所以在宋体中,提的起笔会有一个与竖类似的体饰。

提与竖起笔的体饰是差不多的,只是方向不同而已。

最后就只剩下点和钩两个基础笔画还没设计了。这两个笔画和别的笔画之间的联系不太大,同样也只需要保持整体笔画风格一致就好了。不过点和钩之间却存在着一定的联系的。最主要的是体现在这个地方,如果是尖角,那么点和钩最好都统一为尖角。

而如果点是圆滑过渡的,那么钩最好也是圆角。

另外还有如果点的这个位置是比较饱满的话,那么钩转折的位置也应该设计得饱满一些。

而如果是瘦瘦的点,钩转折的位置也要相应的瘦一些。

最后还有一个需要统一的地方,就是撇、点、钩等笔画的收笔必须要保持一致。可以是圆角、还是切角、尖角或者是其他特殊的角,收笔的大小也应该统一。

不过我们设计宋体字时,也并非一定要百分百遵循这一套设计方法,因为这一套设计理论是结合书法所推导出来的,而随着时代的发展,宋体字的形式和定义也不断被拓宽,例如一些比较新型的宋体,都会省略掉竖、撇、捺等笔画的体饰,让字体显得更简洁一些。所以如果大家想做一些比较创新的宋体字,而非传统严谨的字体的话,大可以放开手脚去设计,最终只要保证美观和和谐统一就好了。

我们在将所有笔画都设计完之后,就可以将笔画拼起来了,可是如果我们设计的笔画比较没有特点,最后拼凑出来的字体也就显得有些中规中矩,缺乏视觉张力。那么接下来我就给大家介绍几个让宋体字比较有张力的常用方法。

第一个是在宋体字的笔画之间加入连接线,模拟写字的连笔效果。

由于宋体字是用刀刻出来的字,基本上是不会有连笔的存在,而加入连笔线条就可以缓和宋体字刀刻的僵硬感,让文字显得更灵动。

第二个方式是将设计好的笔画松散的排列。

因为宋体具有文艺的气质,而将笔画松散地排列能够体现一种慵懒的文艺感,和宋体的气质是非常契合的。

不过这种方式最好能与词义吻合,例如团圆这个词应该是笔画凝结在一起更能符合团圆的词义,像这样做得松松垮垮的味道就有些不太对了。

第三个方式是省略横画。由于宋体字存在着三角衬角,所以即便省略掉了横线,依旧能够通过三角衬角判断横线的位置。

所以省略横画对宋体的识别度影响不大,并且能够增加宋体字的图形感。

第四个方式是断笔。

刚刚我们讲到了宋体存在着三角衬角,所以省略掉横画也不会过多的影响识别度。那么在断笔这里也是一样的道理,我们最好选择断开横画,因为这样对字体识别度的影响最小。

也许有的人听到这里会觉得,这才是课程的重点。其实并不是的,这里教给大家的四个增加张力的手法只是辅助工具而已,不是说我先随便瞎设计一个字体,然后再套用这几个方法去增加形式感,我认为这样的方式只是在遮丑而已,而作为设计师的我们更应该追求骨骼和体饰的美感,而非一味遮丑。那么教程部分就到这里结束,下面给大家示范一个案例吧。

我们这节课的案例就是做韦礼安这首猫咪共和国的单曲封面。这是我从MV开头截的图。我们可以看到MV中猫咪共和国这五个字是手写的,给人一种可爱随意的感觉。那么我们这节课就尝试用宋体字来体现这种感觉。

那么我们对这款字体的定位就很明确了,是一款可爱的标题字体。

我们先在屏幕上打上猫咪共和国五个字作为字体骨骼的参考。这里我选择了思源宋体,因为思源宋体是一款现代型的字体,中宫比较大一些。太过紧凑的中宫不适合我们塑造可爱、随意的感觉。另外一个很重要的原因是,思源宋体虽然高贵,但是免费,如果我们改动的程度不大,也不会造成侵权。

为了让字体更憨一点,我们可以将文字压扁一点点,营造出一种老子一米五的感觉。然后就可以降低透明度,开始在这个参考骨架上秀一波操作了,接下来我们就一个笔画一个笔画地来设计。

首先因为是标题字体,所以我们希望做一个横画和竖画都差不多粗的宋体,这样会比较醒目一些。然后因为气质是可爱的,所以我把体饰设置成圆圆的,胖胖的。

我们用横画推导出竖画。体饰方面基本上就直接照搬了横画的体饰,因为横画的风格很明显了,竖画保持一致就可以了。

接着做横折。我们先将横画和竖画凑一起看看。这样会有两个比较大的问题,一个是竖线的体饰凸出来了一块,另一个是横画和竖画的衬角叠加在一块显得太大了。所以我们需要将衬角缩小一些。

接着做口字结构,我们将竖画放好之后,发现不用调整也挺平衡的,所以我们就直接用这一个口字。

然后撇和捺的起笔我们也可以直接用竖画的起笔推导出来。

值得注意的是,我们可以看一下这个撇,为了凸显这个笔画的可爱,所以我们笔画的粗细变化其实是很小的,为的是让收笔的地方比较钝一些,显得更人畜无害。

同样为了营造字体可爱的气质,我将捺的收笔也设计成圆弧收笔,而并非普通宋体的尖锐收笔。

接下来我们应该是要做提笔画的,可是我们发现这五个字里并没有提,所以我们就跳过他,直接做点和钩了。同样为了保证风格的一致,这个点的粗细变化也不大,而且头特别钝。


点和钩之间是有关联的,这三组地方分别互相对应。
① 端点应该都比较大,比较钝一些;
② 圆滑地过渡;
③ 屁股的地方比较饱满一些。

将做好的笔画放上去,接着还需要做一些调整,因为我们现在用的还是思源宋体的骨架,这个骨架和我们设计的笔画并不一定搭。我对字面大小,视错觉等进行了一定的修正,然后还将中宫稍微扩大了一些。这时候我们会发现,调整过后的这组字依然显得太过正经,还是摆脱不了思源宋体正文字的属性,而我们想做的字应该是可爱、慵懒的标题字。

不知道大家还记不记得我们刚刚讲的宋体字四种增加张力的套路。很明显松散笔画这种方式最适合随机慵懒的感觉,那么我们来试试看。

我们先将这五个字的字距拉开一些,方便我们调整笔画。然后将笔画松散地排列开。

接着我们还需要做一些调整,这样看起来太粗糙了。我们将点、撇、捺等笔画调短一些,让他们具有点的感觉。因为点的构成具有随机和活泼的气质。

然后将重心往下压,因为重心靠下的字体会显得比较憨一些,那么我们这一组字就完成了。

最后我们用这个字来做一个版面,先建立一个单曲封面125mm*125mm的画板,并设置5mm的页边距和7*7的网格。

然后我们放入一张猫的照片作为版面的主体,占据右下角的5.5栏。

接着我们将做好的字体放在左上角,和右下角的猫做对角线的呼应,可是这么摆放好像还是不够好玩。

所以我们加入英文和线条做成一个文字组合。

最后在版面的左下角加入其它信息,这个单曲封面就做好了。

效果还不错吧。
最后我们来总结一下这节课。首先我们给大家扒了一下宋体字的历史,知道了宋体字诞生于明朝,可是最早能够追溯到唐朝。接着分析了宋体字的特征和气质,宋体字相较黑体字具有传统、文化的属性,可是也能通过对体饰、中宫的控制,设计出具有现代感的宋体。然后我们教给了大家一套设计宋体字体饰的方法,最后是四个增加宋体字张力的常用手法。那么我们这节课就到这里,我是千树,我们下次再见。
文章来源:优设 作者:研习设
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
为什么需要额外的类型检查?
TypeScript 只在编译期执行静态类型检查!实际运行的是从 TypeScript 编译的 JavaScript,这些生成的 JavaScript 对类型一无所知。编译期静态类型检查在代码库内部能发挥很大作用,但对不合规范的输入(比如,从 API 处接收的输入)无能为力。
运行时检查的严格性
至少需要和编译期检查一样严格,否则就失去了编译期检查提供的保证。
如有必要,可以比编译期检查更严格,例如,年龄需要大于等于 0。
运行时类型检查策略
定制代码手动检查
灵活
可能比较枯燥,容易出错
容易和实际代码脱节
使用校验库手动检查
比如使用 joi:
import Joi from "@hapi/joi"const schema = Joi.object({ firstName: Joi.string().required(), lastName: Joi.string().required(), age: Joi.number().integer().min(0).required()});
灵活
容易编写
容易和实际代码脱节
手动创建 JSON Schema
例如:
{ "$schema": "http://json-schema.org/draft-07/schema#", "required": [ "firstName", "lastName", "age" ], "properties": { "firstName": { "type": "string" }, "lastName": { "type": "string" }, "age": { "type": "integer", "minimum": 0 } }}
使用标准格式,有大量库可以校验。
JSON 很容易存储和复用。
可能会很冗长,手写 JSON Schema 可能会很枯燥。
需要确保 Schema 和代码同步更新。
自动创建 JSON Schema
基于 TypeScript 代码生成 JSON Schema
-- 比如 typescript-json-schema 这个工具就可以做到这一点(同时支持作为命令行工具使用和通过代码调用)。
-- 需要确保 Schema 和代码同步更新。
基于 JSON 输入示例生成
-- 没有使用已经在 TypeScript 代码中定义的类型信息。
-- 如果提供的 JSON 输入示例和实际输入不一致,可能导致错误。
-- 仍然需要确保 Schema 和代码同步更新。
转译
例如使用 ts-runtime。
这种方式会将代码转译成功能上等价但内置运行时类型检查的代码。
比如,下面的代码:
interface Person { firstName: string; lastName: string; age: number;}const test: Person = { firstName: "Foo", lastName: "Bar", age: 55}
会被转译为:
import t from "ts-runtime/lib";const Person = t.type( "Person", t.object( t.property("firstName", t.string()), t.property("lastName", t.string()), t.property("age", t.number()) ));const test = t.ref(Person).assert({ firstName: "Foo", lastName: "Bar", age: 55});
这一方式的缺陷是无法控制在何处进行运行时检查(我们只需在输入输出的边界处进行运行时类型检查)。
顺便提一下,这是一个实验性的库,不建议在生产环境使用。
运行时类型派生静态类型
比如使用 io-ts 这个库。
这一方式下,我们定义运行时类型,TypeScript 会根据我们定义的运行时类型推断出静态类型。
运行时类型示例:
import t from "io-ts";const PersonType = t.type({ firstName: t.string, lastName: t.string, age: t.refinement(t.number, n => n >= 0, 'Positive')})
从中提取相应的静态类型:
interface Person extends t.TypeOf<typeof PersonType> {}
以上类型等价于:
interface Person { firstName: string; lastName: string; age: number;}
类型总是同步的。
io-ts 很强大,比如支持递归类型。
需要将类型定义为 io-ts 运行时类型,这在定义类时不适用:
-- 有一种变通的办法是使用 io-ts 定义一个接口,然后让类实现这个接口。然而,这意味着每次给类增加属性的时候都要更新 io-ts 类型。
不容易复用接口(比如前后端之间使用同一接口),因为这些接口是 io-ts 类型而不是普通的 TypeScript 类型。
基于装饰器的类校验
比如使用 class-validator 这个库。
基于类属性的装饰器。
和 Java 的 JSR-380 Bean Validation 2.0 (比如 Hibernate Validator 就实现了这一标准)很像。
-- 此类 Java EE 风格的库还有 typeorm (ORM 库,类似 Java 的 JPA)和 routing-controllers (用于定义 API,类似 Java 的 JAX-RS)。
代码示例:
import { plainToClass } from "class-transformer";import { validate, IsString, IsInt, Min } from "class-validator";class Person { @IsString() firstName: string; @IsString() lastName: string; @IsInt() @Min(0) age: number;}const input: any = { firstName: "Foo", age: -1};const inputAsClassInstance = plainToClass( Person, input as Person);validate(inputAsClassInstance).then(errors => { // 错误处理代码});
类型总是同步的。
需要对类进行检查时很有用。
可以用来检查接口(定义一个实现接口的类)。
注意:class-validator 用于具体的类实例。在上面的代码中,我们使用它的姊妹库 class-transformer 将普通输入转换为 Person 实例。转换过程本身不进行任何类型检查。
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
为什么要做数据可视化?
在一个设计项目里,
到底要从哪一个角度切入,才能经得推敲?
每个数据可视化,
模拟美国1790-2016 移民的时代树轮
作者从自然中的树轮提取灵感,把树的生长迁移到移民变化上,发现了美国通过类似的移民过程。
https://web.northeastern.edu/naturalizing-immigration-dataviz/
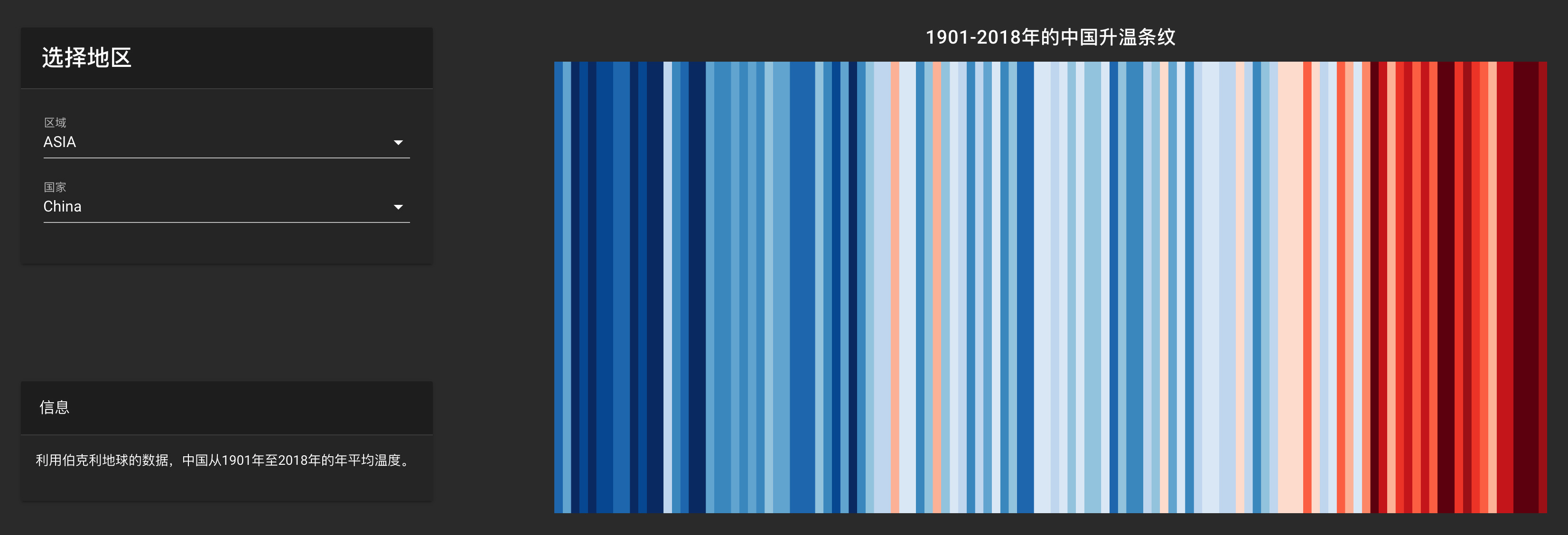
这个可视化形式非常经典,条纹代表了自19世纪中期以来每年的全球平均气温,通过网页的相互作用,你还能看到不同国家不同地区在这段时间的温度变化。,
现居上海,在澎湃新闻担任数据可视化设计师。
自学编程两年多,最初是为了做更酷的数据可视化作品,误打误撞放置了十款设计小工具,变成了模仿的设计玩具制造玩家,希望用编程去解锁设计/数据可视化的更多可能性。
●
为理清垃圾分类规则,亚赛及团队从上海市垃圾分类查询平台上筛选了2055件物品的垃圾分类信息,看可视化教你如何分类垃圾。
项目封面,垃圾从屏幕上方掉落,通过鼠标可以进行交互。
世界杯落幕,一个月来32支球队打入了169粒进球。如果俯瞰足球场,将所有进球在一张图上绘出,有某种绝妙的,惊险的,乌龙的瞬间?
亚赛大学专业是广告学,毕业后却成为数据可视化设计师,在她看来,数据可视化并同时是“图表”,而是用设计和编程描述数据背后的故事,发现世界的渠道。如何展示数据,如何跟观众讲这个既定事实故事,都是设计师需要考虑的。
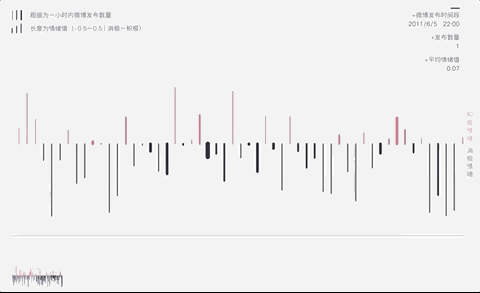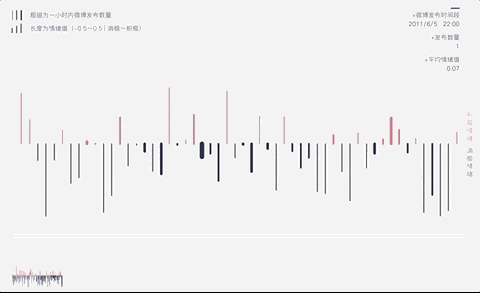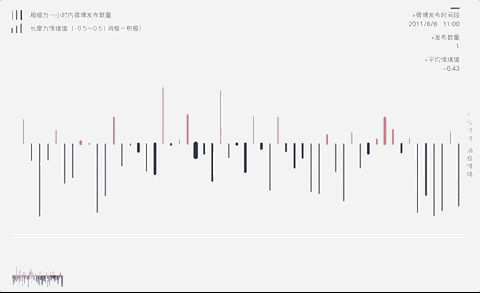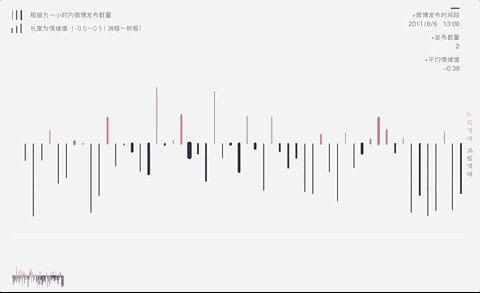
红色向上为相对积极,蓝色行下为相对消极,每根柱子的长度代表情绪的大小,通过3000多条微博看到她在微博内容背后自己的情绪斗争。
结合她发微博的时间制作了微博发布时间情况,用花瓣作为视觉呈现,真切意识到患者脆弱的无力感。


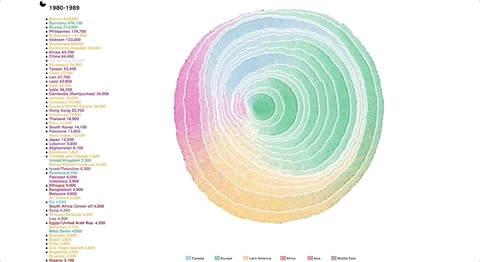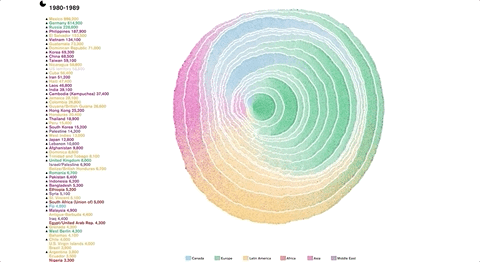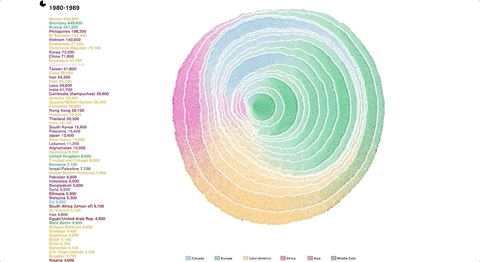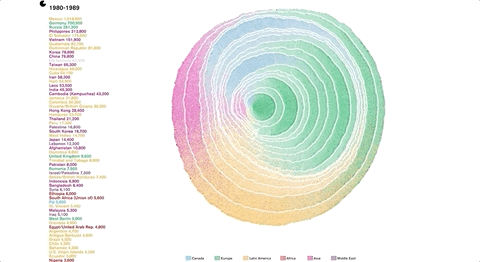
在这里你能看到117年气温的变化
●

为什么要数据可视化?
1.我们利用视觉获取的信息量,其实远远超过别别的感官要多层次。
2.可视化将会让观众更加直观全面看待事实故事
3.人类大脑对记忆能力的限制

垃圾分类可视化手册



169球回顾俄罗斯世界杯
●
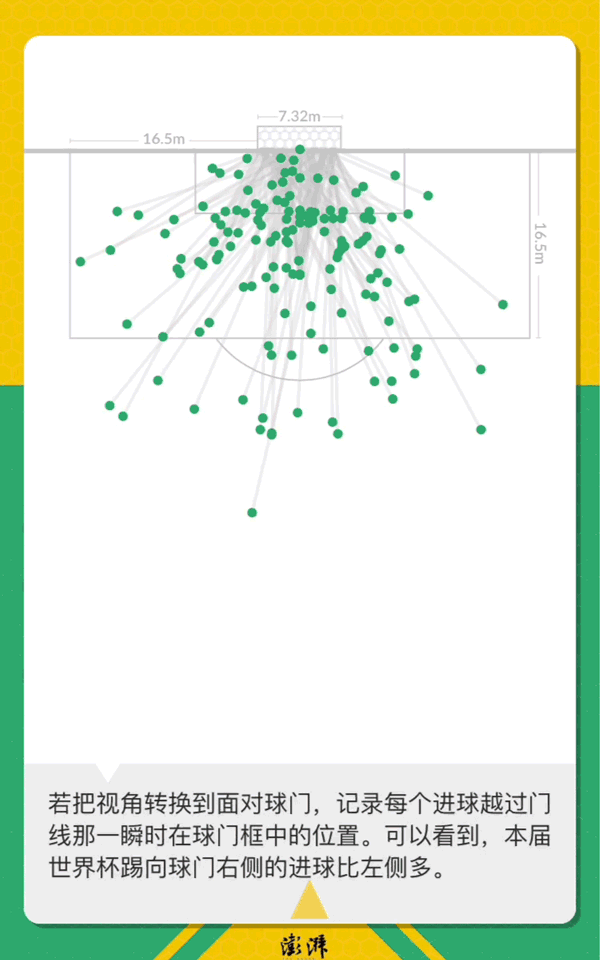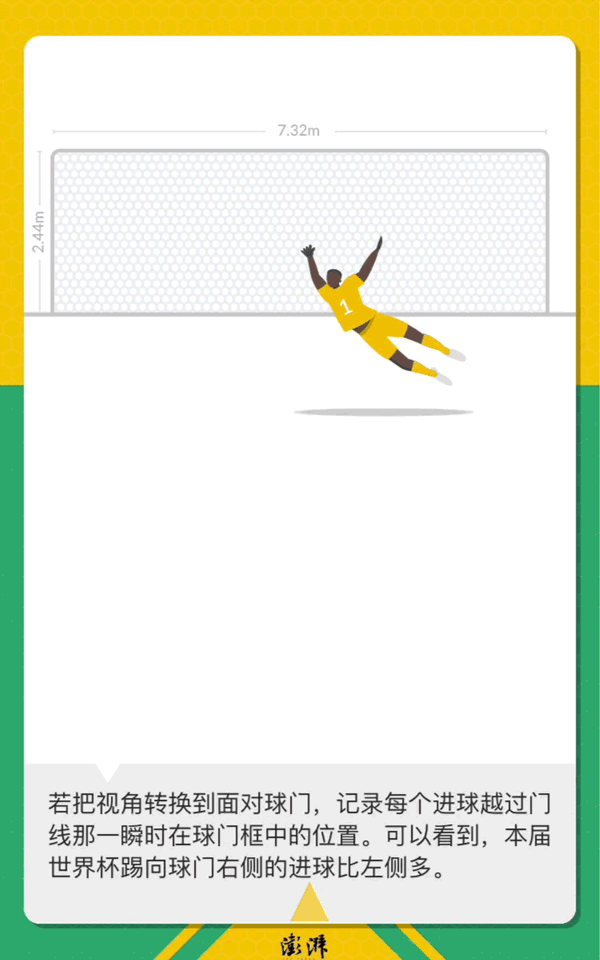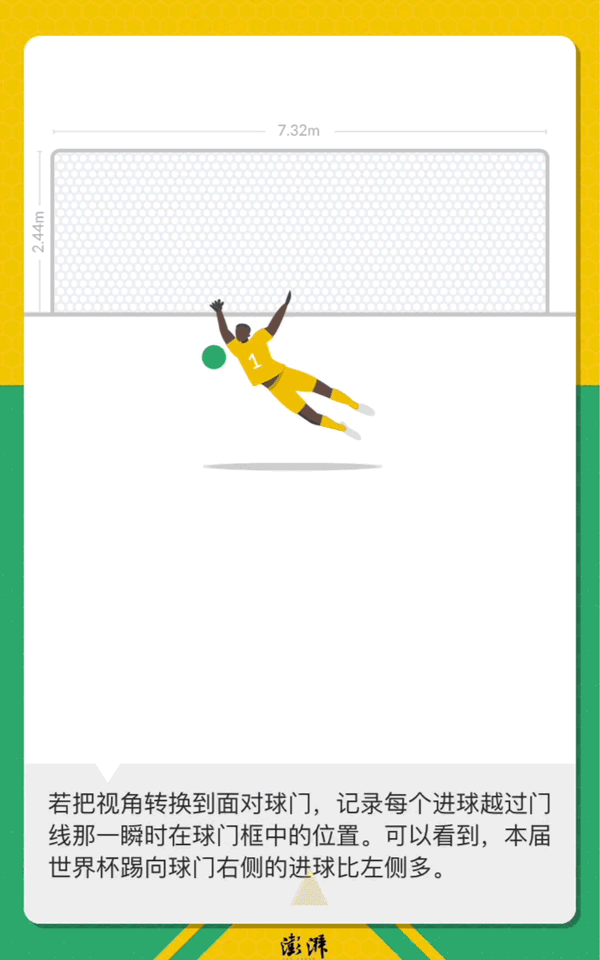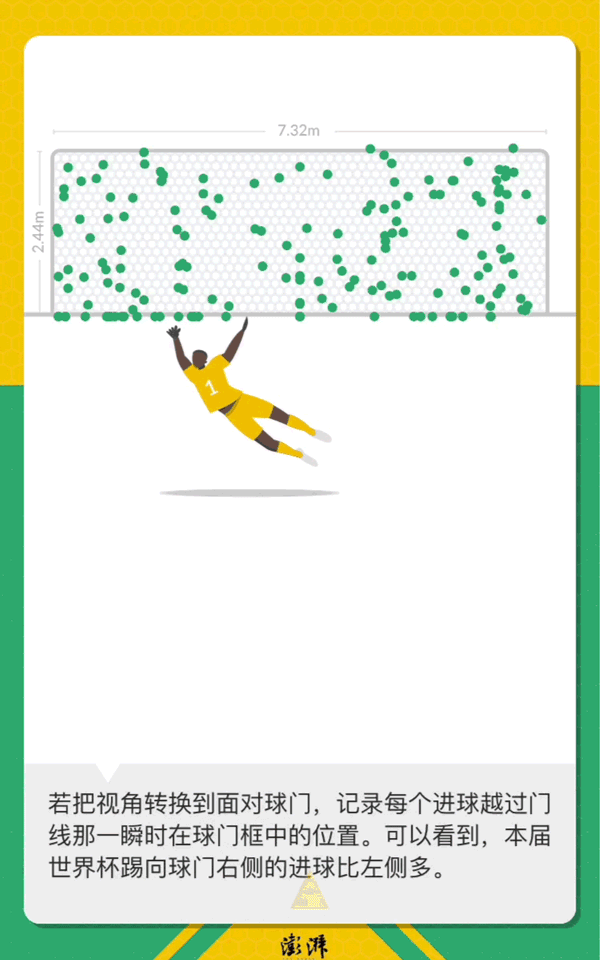
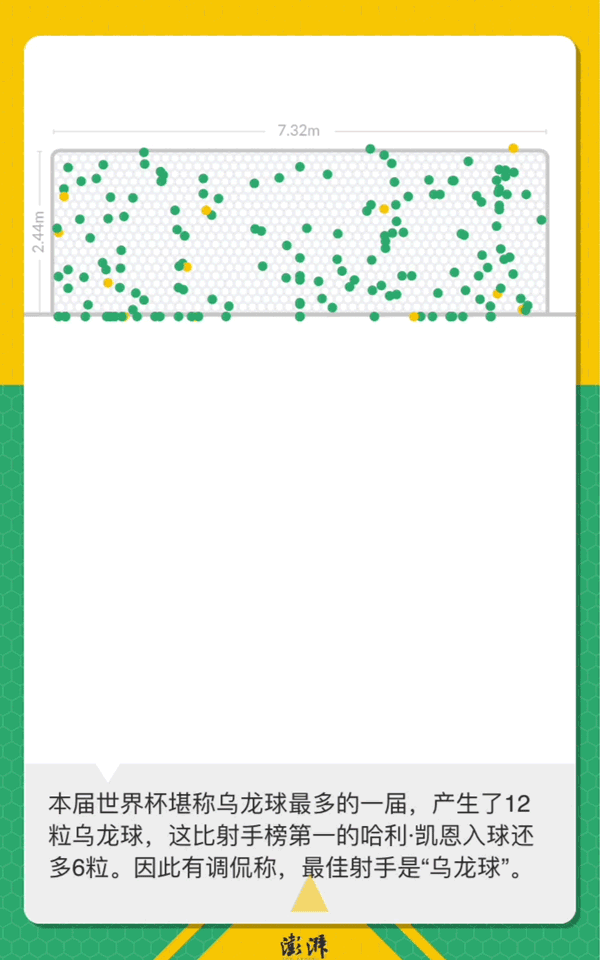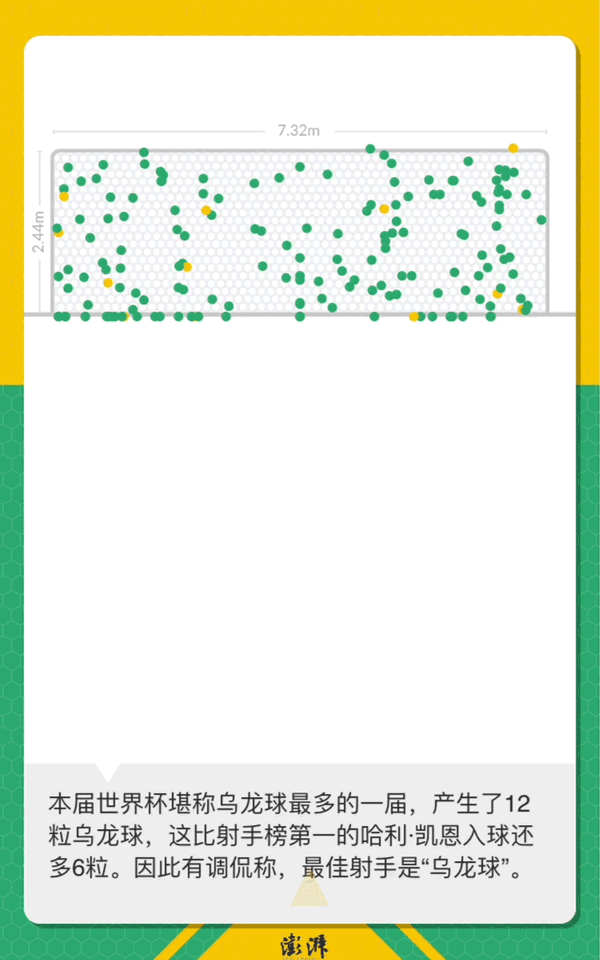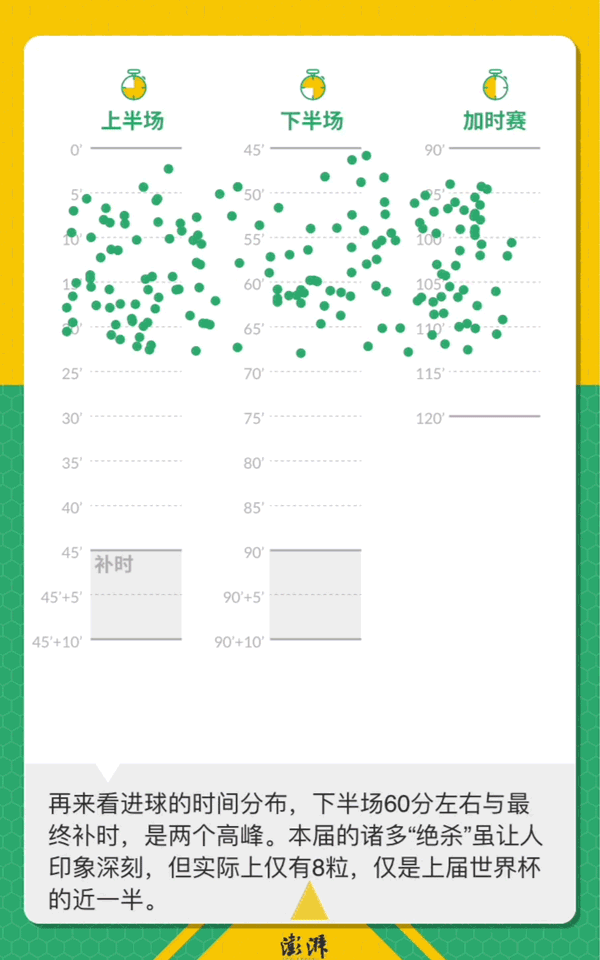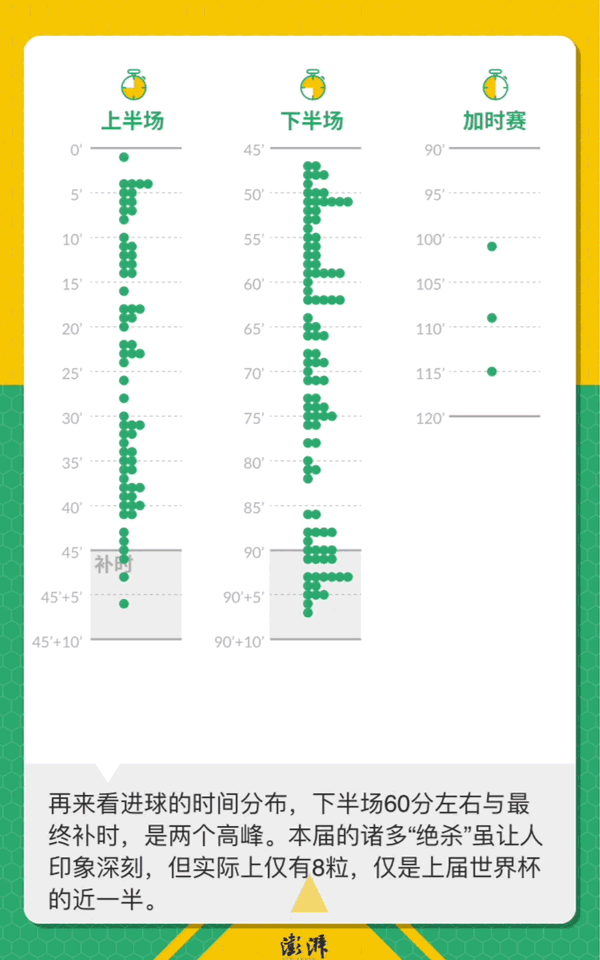
数据分析53027条留言背后
抑郁症患者的自救与互助
02
数据可视化
创作的7个步骤
景点事件:某种前几天的女排十一连胜,就可以提前找数据做一个梳理类的题。
热门话题:有的话题是社会持续关注的起点,可以从深度报道,学术研究等不同管道持续关注。
关注来源:习惯性地关注一些信息来源,某些智库,政府网站,外国网站等等。
1.获取数据,无所谓是来自文件,磁盘亦或者网络等;
2.分析数据结构,分类排序;
3.过滤,去掉所有不感兴趣的数据;
4.综合使用数学,统计,模式识别等方法来挖掘出一些特征数据;
5.选择某种树状图,列表,树等的可视化模型来替换数据;
6.精炼基本表示法,使数据插入的更清楚,预期视觉效果;
7.添加一些用于控制或操作数据的交互方法。
●
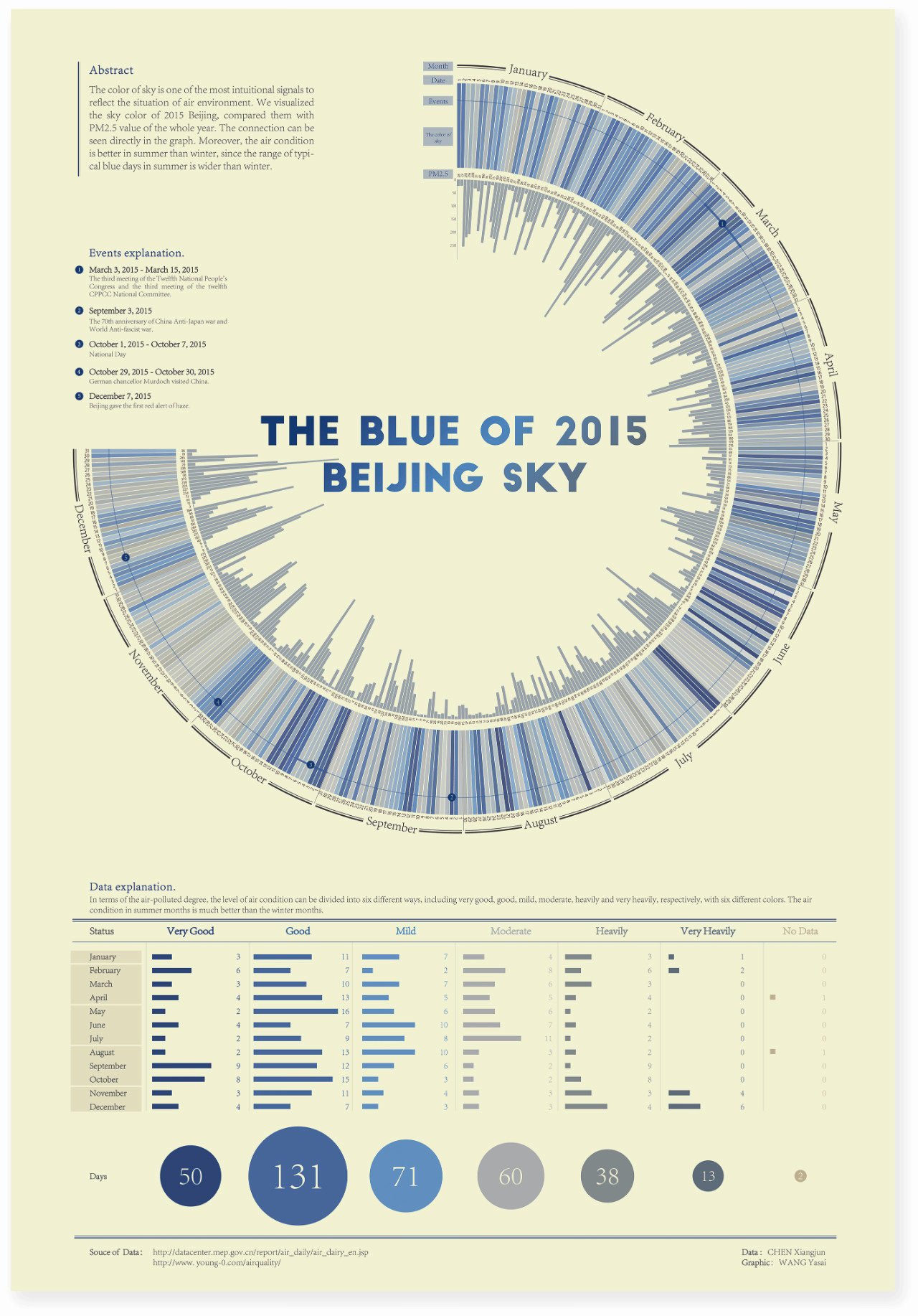
这是亚赛做过一个关于春节禁放烟花的选题,把某些城市的除夕中午12点到春节中午12点变成一朵24片花瓣(代表24小时)的烟花,对比2017年和2018年两年的数据。
通过环境质量数据来看烟花禁放政策下的效果,看到不同地区不同政策带来的影响。
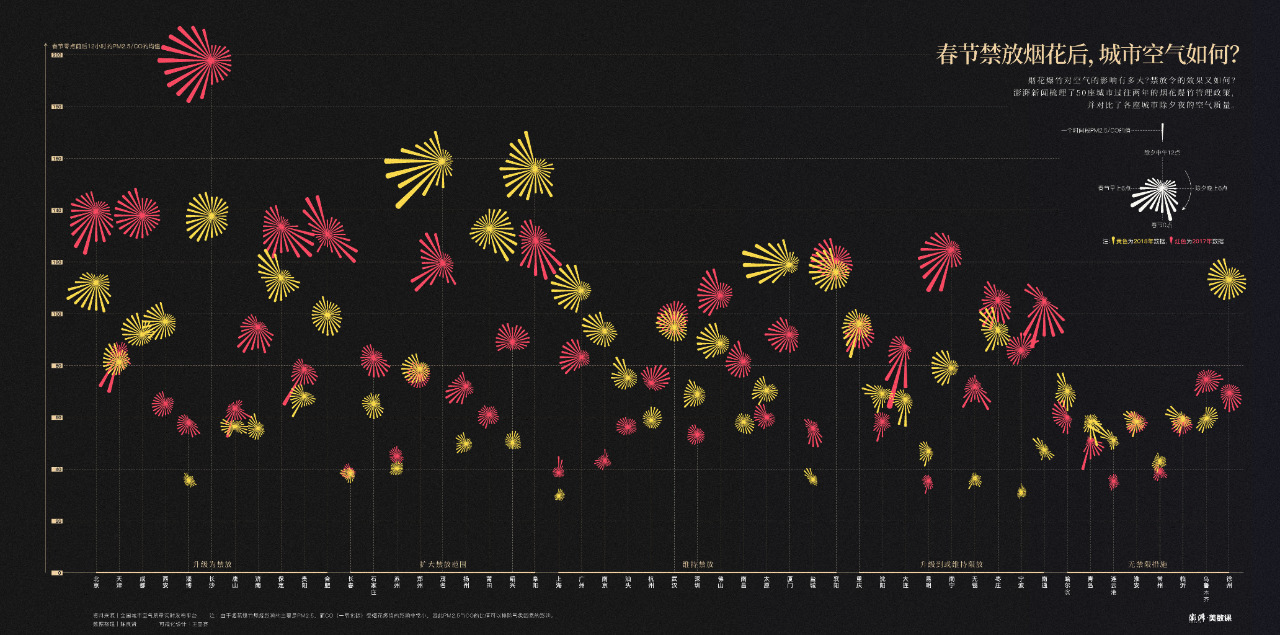
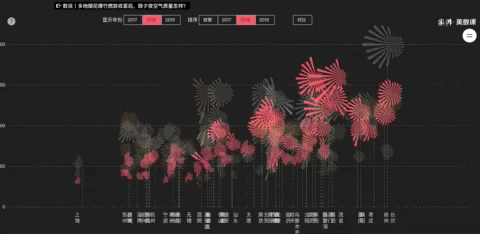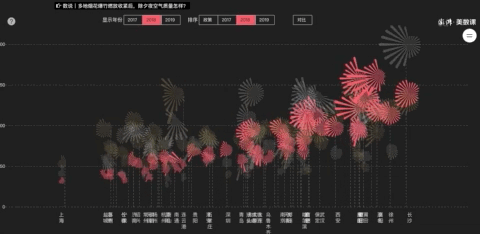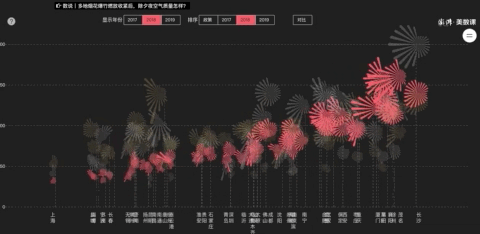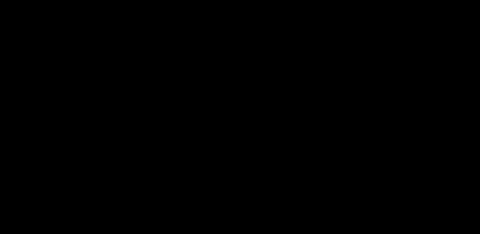
详细案例:https : //wangyasai.github.io/Work/firework.html
03


文章来源:站酷 作者:最毕设设计媒体
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
蓝蓝设计的小编 http://www.lanlanwork.com