

Web前端基础:
Web前端工具:
jQuery是一个JavaScript函数库。jQuery是一个轻量级的"写的少,做的多"的JavaScript库。 jQuery库包含以下功能:
提示: 除此之外,jQuery还提供了大量的插件。
目前网络上有大量开源的 JS 框架, 但是 jQuery 是目前最流行的 JS 框架,而且提供了大量的扩展。

jQuery版本有很多,分为1.x 2.x 3.x
1.x版本:能够兼容IE678浏览器
2.x版本:不兼容IE678浏览器
1.x和2.x版本jquery都不再更新版本了,现在只更新3.x版本。 3.x版本:不兼容IE678,更加的精简(在国内不流行,因为国内使用jQuery的主要目的就是兼容IE678)
国内多数网站还在使用1.x的版本
该总结中所用版本为1.1的版本
jQuery有两个版本:
生成环境使用的和开发测试环境使用的。
Production version - 用于实际的网站中,已被精简和压缩。
Development version - 用于测试和开发(未压缩,是可读的代码)
以上两个版本都可以从 jquery.com 中下载。
这里给个国内的下载地址:
JQuery 下载
jQuery 库是一个 JavaScript 文件,我们可以直接在 HTML页面中通过script 标签引用它,跟引用自己的 外部JavaScript脚本文件一样的语法。
//将第一步中下载好的jQuery资源包进行解压,然后就可以饮用解压好的.js文件 <head> <script src="jquery-1.11.1.js"></script> </head>了。
jQuery 语法是通过选取 HTML 元素,并对选取的元素执行某些操作(actions)
$(selector).action() 说明:美元符号定义 jQuery 选择符(selector)"查询"和"查找" HTML 元素
jQuery 的 action() 执行对元素的操作
文档就绪事件,实际就是文件加载事件。
这是为了防止文档在完全加载(就绪)之前运行 jQuery 代码,即在 DOM 加载完成后才可以对 DOM 进行操作。
如果在文档没有完全加载之前就运行函数,操作可能失败。 所以我们尽可能将所有的操作都在文档加载完毕之后实现。
写法一:
$(function(){ // 开始写 jQuery 代码... });
写法二:
$(document).ready(function(){ // 开始写 jQuery 代码... });
jQuery的ready方法与JavaScript中的onload相似,但是也有区别 :
| 区别 | window.onload | $(document).ready() |
|---|---|---|
| 执行次数 | 只能执行一次,如果执行第二次,第一次的执行会被覆盖 | 可用执行多次,不会覆盖之前的执行 |
| 执行时机 | 必须等待网易全部加载挖完毕(包括图片等),然后再执行包裹的代码 | 只需要等待网页中的DOM结果加载完 毕就可以执行包裹的代码 |
| 简写方式 | 无 | $(function(){ }); |
jQuery 选择器基于元素的 id、类、类型、属性、属性值等"查找"(或选择)HTML 元素。 它基于已经存在的 CSS 选择器,除此之外,它还有一些自定义的选择器。
jQuery 中所有选择器都以美元符号开头:$()。
Query 元素选择器基于元素/标签名选取元素。
语法:$("标签名称")
<div>div1</div> <div>div2</div> <div>div3</div> <script type="text/javascript" src="js/jquery-1.11.1.js" > <script> //文档就绪事件: $(document).ready(function(){ //编写jQuery }); $(function(){ //1、标签选择器: //获取所有的div元素(集合) var divList=$("div"); console.log(divList);//jQuery的对象 console.log(divList.length); for(var i=0;i<divList.length;i++){ console.log(divList[i]);//js的对象 //将js对象转换为jQuery的对象 console.log($(divList[i])); } }); </script>
jQuery #id 选择器通过 HTML 元素的 id 属性选取指定的元素。
页面中元素的 id 应该是唯一的,所以在页面中选取唯一的元素需要通过 #id 选择器。
通过 id 选取元素语法如下:
$("#p1")
jQuery 类选择器可以通过指定的 class 查找元素
$(".mydiv")
匹配所有元素
$("*")
将每一个选择器匹配到的元素合并后一起返回
$("div,ul,li,.mydiv")
在给定的祖先元素下匹配所有的后代元素
$("form input"
在给定的父元素下匹配所有的子元素
$("form > input")
匹配所有紧接在 prev 元素后的 next 元素
$("label + input")
匹配 prev 元素之后的所有 siblings 元素
$("form ~ input")
页面对不同访问者的响应叫做事件
事件处理程序指的是当 HTML 中发生某些事件时所调用的方法
| 鼠标事件 | 键盘事件 | 事件 | 文档/窗口事件 |
|---|---|---|---|
| click | keydown | submit | load |
| dblclick | keyup | change | |
| mouseover | focus | ||
| mouseout | blur | ||
| hover |
在 jQuery 中,大多数 DOM 事件都有一个等效的 jQuery 方法
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
目录
3. 首次有效渲染时间要低于1.25秒,速度指数要低于1000
5. 渐进增强(progressive enhancement)
15.1 如何使用webpack将静态素材快速托管到ImageX,并开启http/2
18. 通过tree-shaking和code-splitting减少净负载
微优化是保持性能最好的办法,但是又不能有太过明确的优化目标,因为过于明确的目标会影响在项目中做的每一个决定。以下是一些不同的模型,请按照自己舒服的顺序阅读
根据一个心理学研究,你的网站最少在速度上比别人快20%,才能让用户感觉到你的网站比别人的更快。这个速度说的不是整个页面的加载时间,而是开始加载渲染的时间,首次有效渲染时间(例如页面需要加载主要内容的时间),或者交互时间(指的是页面或者应用中主要的页面加载完成,并主备好与用户进行交互的时间)。
在Moto G(一个中端三星设备)和Nexus 4(比较主流的设备)上衡量开始渲染时间(用WebPagetest)以及首页有效渲染时间(用Lighthouse),最好是在一个开放的实验室中,使用规范的3G,4G和Wi-Fi链接。
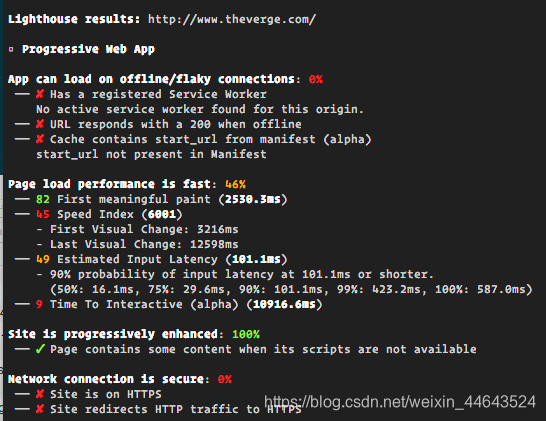
你可以通过你的分析报告看看你的用户处在哪个阶段,选取其中前90%的用户体验来做测试。接着收集数据,建一个表格,筛去20%的数据并预设一个目标(如:性能预算)。现在你可以将上述两个值进行对比检测。如果你始终维持着你的目标并且通过一点一点改变脚本去加快交互时间,那么上述方法就是合理可行的。
如果前端工程师们都在积极的参与项目概念,UX以及视觉设计的决定,这将会给整个项目带来巨大收益。地图设计的决定违背了性能理念,所以他在这份清单内的顺序有待考虑。
RAIL性能模型会为你提供一个优秀的目标,既尽最大的努力在用户初始操作后的100毫秒内提供反馈。为了达到这个目标,页面需要放弃权限,并将权限在50毫秒内交回给主线程。对于像动画一样的高压点,最好的方法就是什么都不做,因为你永远无法达到最小绝对值。
同理,动画的每一帧都需要在16毫秒内完成,这样才能保证每秒60帧(一秒/60=16.6毫秒),如果可以的话最好能在10毫秒内完成。因为浏览器需要一定的时间去在屏幕上渲染新的帧,而且你的代码需要在16.6毫秒内完成执行。要注意,上述目标应用于衡量项目的运行性能,而非加载性能。
纵使这个目标实现起来非常困难,你的最终目标也应该是让开始渲染时间低于1秒且速度指数低于1000(在网速快的地方)。对于首次有效渲染时间,上限最好是1250毫秒。对于移动端,3G下移动设备首次渲染时间低于3秒都是可以接受的。稍微高一点也没关系,但千万别高太多。
不要过多的关注当下最流行的工具,坚持选择适合自己开发环境的工具,例如Grunt、Gulp、Webpack、PostCSS,或者组合起来的工具。只要这个工具运行的速度够快,而且没有给你的维护带来太大问题,这就够了。
在构建前端结构的时候,应始终将渐进增强作为你的指导原则。首先设计并且构建核心体验,随后再完善那些为高性能浏览器设计的高级特性的相关体验,创建弹性体验。如果你的网页可以在使用低速网络、老旧显示器的很慢的电脑上运行飞快,那么在光纤高配电脑上它只会运行的更快。
根据你整体组织结构的优先顺序和策略,你可以考虑使用Google的AMP或Facebook的Instant Articles。要知道没有这些你也可以达到不错的性能,但是AMP可以提供一个性能不错的免费的内容分发网络框架(CDN),Instant Articles可以在Facebook上促进你的性能。你也可以建立progressive web AMP。
根据你的动态数据量,可以将一部分内容外包给静态网站生成工具,将它置于CDN上,从中生成一个静态版本,从而避免那些数据库的请求。也可以选择基于CDN的静态主机平台,通过交互组件丰富你的页面(JAMStack)。注意CDN是否可以很好的处理(或分流)动态内容。没必要单纯的将你的CDN限制为静态。反复检查CDN是否执行了内容的压缩和转化,检查智能HTTP/2传输和缓存服务器(ESI),注意哪些静态或动态的部分处在CDN的边缘(最接近用户的服务器)。
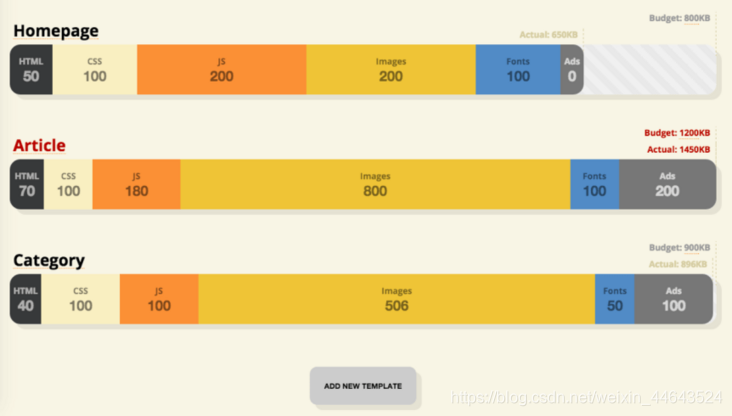
首先应该弄清楚你想解决的问题是什么。检查一遍你所有的文件(JavaScript,图片,字体,第三方script文件以及页面中重要的模块,例如轮播,复杂信息图标和多媒体内容),并将他们分类。
列一个表格。明确浏览器上应该有的基础核心内容,哪些部分属于为高性能浏览器设计的升级体验,哪些是附加内容(那些不必要或者可以被延时加载的部分,例如字体,不必要的样式,轮播组件,播放器,社交网站入口,很大的图片)。
使用符合标准的技术向过时的浏览器提供核心体验,向老式浏览器提供增强体验, 同时对所加载的内容要有严格的把控。即首要加载核心体验部分,将增强部分放在
DomContentLoaded,把额外内容发在load事件中。以前我们可以通过浏览器的版本推断出设备的性能,但现在我们已经无法推测了。因为现在市场上很多廉价的安卓手机都不考虑内存限制和CPU性能,直接使用高版本的Chrome浏览器。一定要注意,在我们没有其他选择的时候,我们选择的技术同时可能成为我们的限制。
在一些应用中,可以在渲染页面前先初始化应用。最好先显示框架,而不是一个进度条或指示器。使用可以加速初始渲染时间的模块或技术(例如tree-shaking和code-splitting),因为大部分性能问题来自于应用引导程序的初始分析时间。还可以在服务器上提前编译,从而减轻部分客户端的渲染过程,从而快速输出结果。最后,考虑使用Optimize.js来加快初始加载速度,它的原理是包装优先级高的调用函数(虽然现在已经没什么必要了)。

到底采用客户端渲染还是服务器端渲染?不论哪种做法,我们的目标都是建立渐进启动:使用服务器端渲染可以得到很短的首次有效渲染时间,这个渲染过程也包括小部分的JavaScript文件,目的是使交互时间尽可能的接近首次有效渲染时间。接下来,尽可能的增加一些应用的非必要功能。不幸的是,正如Paul Lewis所说,框架基本上对开发者是没有优先级的概念的,因此渐进启动在很多库和框架上是很难实施的。如果你有时间的话,还是考虑使用策略去优化你的性能吧。
仔细检查一下例如expires,cache-control,max-age以及其他HTTP缓存头是否被正确的使用。一般来说,资源不论在短时间(如果它会被频繁改动)还是不确定的时间内(如果它是静态的)都是可缓存的——你大可在需要的时候在URL中成改版本。如果可能,使用为指纹静态资源设计的Cache-control:immutable,从而避免二次验证(2016年12月,只有FireFox在https://处理中支持)。你可以使用,Heroku的primer on HTTP caching headers,Jake Archibald的 ”Caching Best Practices”,还有IIya Grigorik的HTTP caching primer作为指导。
当用户请求页面时,浏览器会抓取HTML同时生成DOM,然后抓取CSS并建立CSS对象模型,最后通过匹配DOM和CSS对象生成渲染树。在需要处理的JavaScript文件被解决之前,浏览器不会开始对页面进行渲染。作为开发者,我们要明确的告诉浏览器不要等待,直接开始渲染。具体方法是使用HTML中的
defer和async两个属性。事实上,defer更好一些(因为对于IE9及以下用户对于IE9及以下用户,很有可能会中断脚本)。同时,减少第三方库和脚本的使用,尤其是社交网站的分享按键和<iframe>嵌入(比如地图)。你可以使用静态的社交网站分享按键(例如SSBG的)和指向交互地图的静态链接去代替他们。
尽可能的使用带有
srcset,sizes还有<picture>元素的响应式图片。你也可以利用<picture>元素的AVIF、WEBP格式,用JPEG格式作为替补(参见Andreas Bovens的code snippet)或是使用内容协商(使用接受头)。本身可以使用自己的PS或者skecth尝试导出,若不能导出,可以尝试 火山引擎的ImageX图像处理服务(不知道怎么使用可以自行百度搜索 "火山引擎 ImageX")可以支持多种格式输出,比如AVIF、webp格式;
我曾经写过这篇文档可以对照一下:高效率图像压缩处理服务, 参考截图:
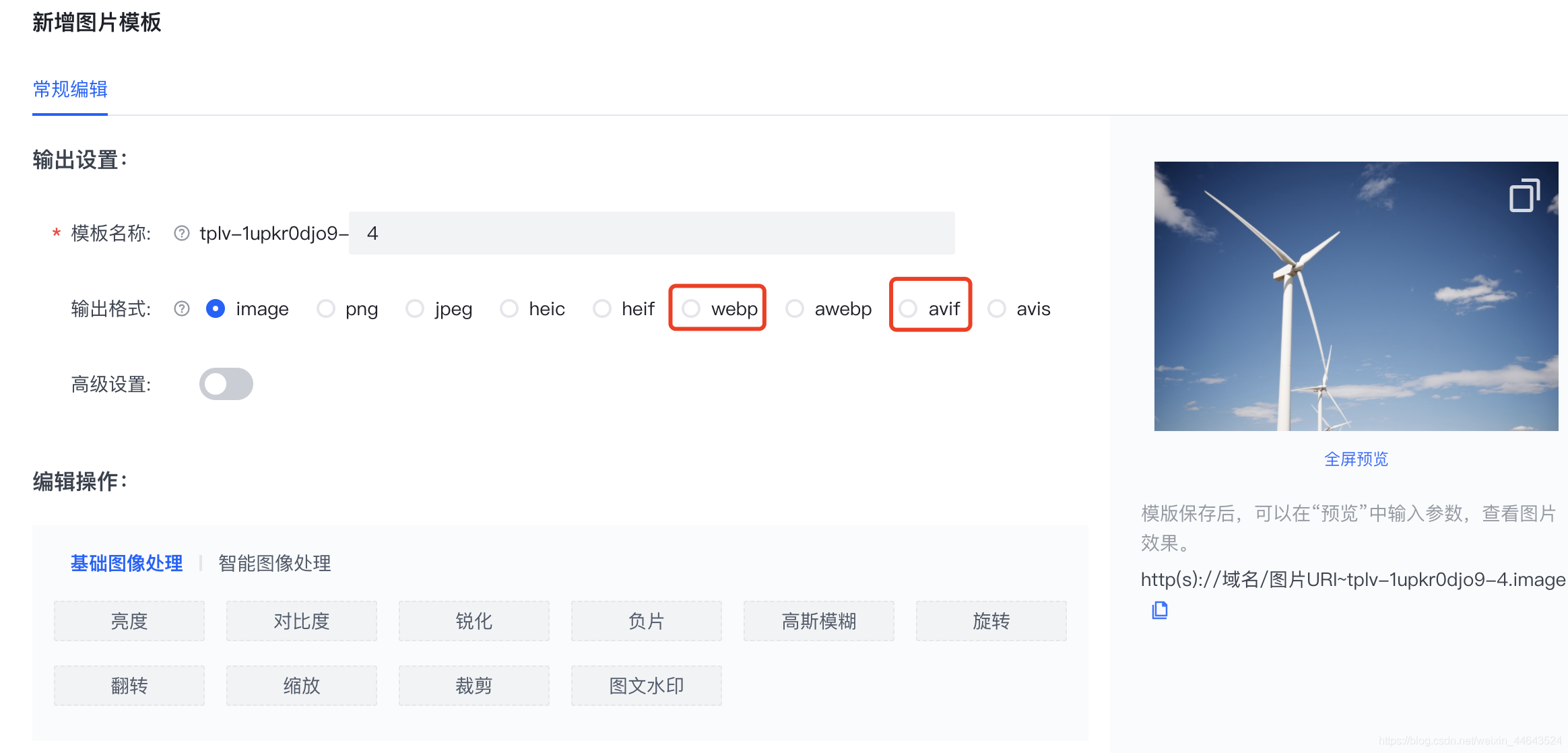
你也可以使用客户端提示,现在浏览器也可以做到。在用来生成响应图片的源文件过少时,使用响应图片断点生成器。
当你在编写登录界面的时候,发现页面上的图片加载的特别快,这时你需要确认一下图片进一步优化的思路只要有三点:
- 降低图片的分辨率,如果浏览器中展示区域100*100,此时展示 400*400 就属于资源浪费,这也是显著提高图片响应速度最直接的方法;
- 降低图片压缩的质量,图片压缩质量,使用有损压缩,比如图片压缩质量90 和75对人眼可见的范围内都可以接受,常见支持有损压缩的图片格式比如,jpeg、wepb、heic、avif等图片格式支持图片有损压缩;
- 改变图像压缩的压缩方式,改变图片的压缩算法也能更高效的提高图片优化图片提高速度,比如 常见图像压缩率(图像画质等同前提下): HEIF (heic) > AVIF (avif、avis) >webP(awebp) > jpeg > png 等;
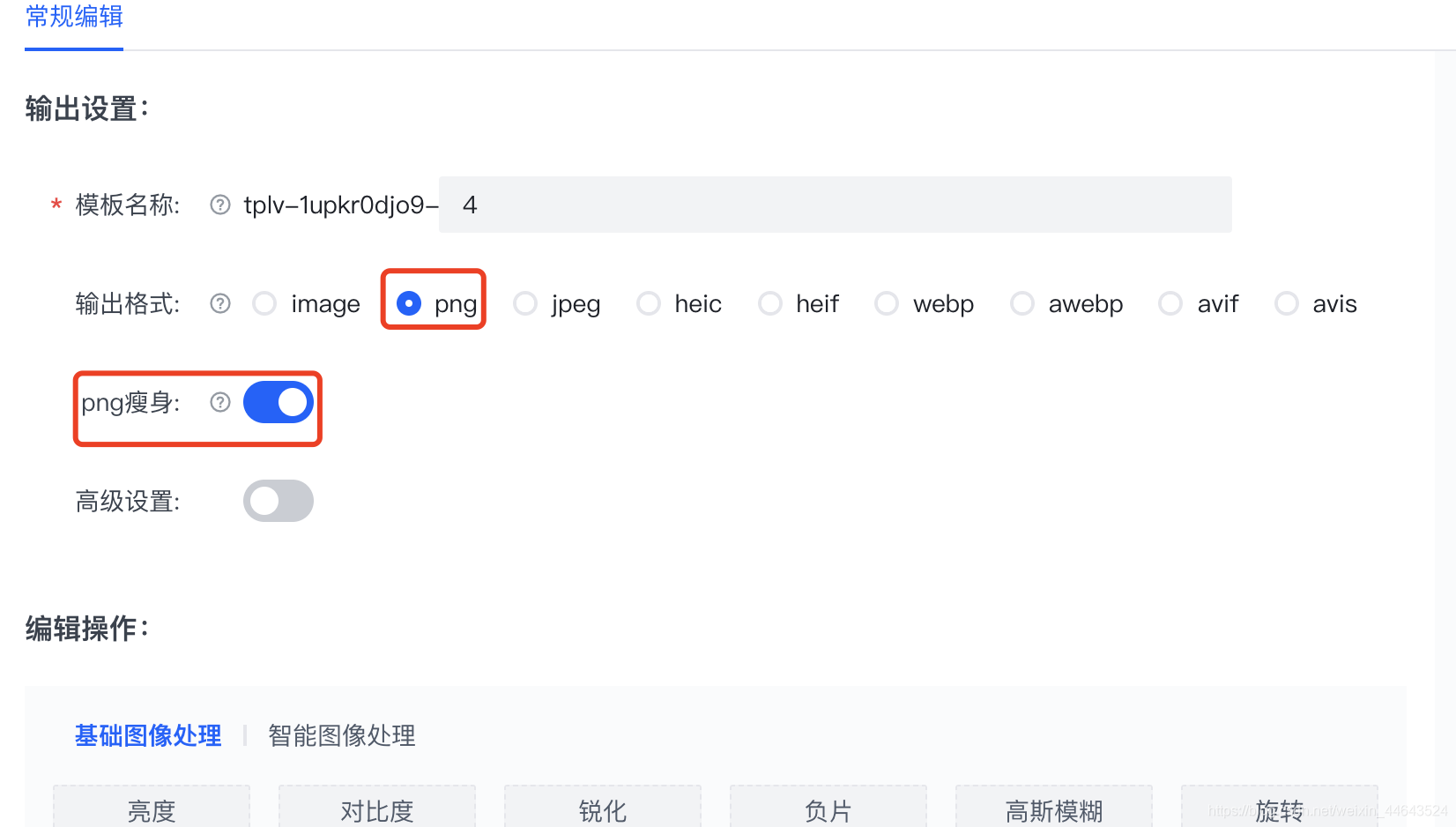
正常情况下PNG是原图格式,体积特别大,巧的是业界对PNG 有
pngquant使用Median Cut量化算法的修改版本和其他技术来缓解Median Cut的不足,可以最大效率保留信息的前提下降低png 的体积大小;如果我们把如上的一些优化处理起来,我使用的过程中发现,火山引擎的imagex 已经完美的支持了上面三者的使用方法:下面我举个例子做一下说明:http://imagex.75live.com/tos-cn-i-n9b2vwdhz3/public/attachments/2021/03/11/GyVrojIWFkQOKSAzYnUmlQxvaESnPaZYxgpu9v1Z.png~tplv-n9b2vwdhz3-12:300:200.webp 这个是 png的原图处理好的结果,在这个url中imagex 给出了一种url语义,"~tplv--模板名称:[模板参数].图像格式" 通过改变300:300 能改改变压缩率,通过参数能够调整压缩质量,通过改变webp-->avif 可以转换成不同的压缩方法;
更巧妙的是在这,就算指定输出png后仍然还可以设置质量参数
如果你还觉得不够,那你可以通过多重背景图片技术来提高图片的感知性能。
这里发现一个第三方写的但被官方推荐的开源插件https://github.com/Cmaxd/veimagex-webpack-loader ,通过配置webpack-loader 插件的方式可以将图片上传到ImageX,然后将图片使用不同的图片模板访问就可以满足需求,同一个图片可以使用多个地址,例如avif、webp、jpeg 使用 <picture> 标签进行降级 或者判断浏览器支持降级;
你用来修饰网页字体的服务很有可能毫无用处,包括字形和额外的特性。如果你在使用开源的字体,尝试用字体库中某一个小的子集或是自己归类一个小的子集从而压缩文件大小(例如通过一些特殊的注音符号引用Latin)。WOFF2 support是个非常不错的选择,如果浏览器不支持,那你可以将WOFF和OTF作为备用。你也可以从Zach Leatherman的“Comprehensive Guide to Font-Loading Strategies”一文中选择一个合适的策略,然后使用服务器来缓存字体。如果想要快速入门,Pixel Ambacht的教程与案例会让你的字体变得尽然有序。如果你用的是第三方服务器主机,没办法自己在服务器上对字体进行操作,一定看看Web Font Loader。
为了确保浏览器尽可能快的渲染你的页面,先收集页面首次可见部分的CSS文件(也叫决定性CSS或上半版CSS)进行渲染,然后将它加入页面的<head>部分,从而避免重复操作。因为慢启动阶段对交换包大小的限制,你关键CSS文件的大小也被限制在14KB左右。如果高于这个值,浏览器需要重复一些步骤来获取更多的样式。关键CSS是允许你这样做的。可能对每个模板都需要这个操作。如果可能,考虑一下用Fiament Group用的条件内敛方法。
通过HTTP/2,关键CSS可以单独存为CSS文件,通过服务器传输,而且可以避免HTML膨胀。服务器传输缺乏连续支持,并且存在一些超高速缓存的问题(Hooman Beheshti演示的前144页)。事实上,这样会导致网络缓冲区膨胀。因为TCP的慢启动,服务器传输在稳定的连接下会更有效率。所以你可能需要建立带有缓存的HTTP/2服务器传输机制。但请记住,新的
cache-digest规则会否定手动建立的需要缓存的服务器的请求。
Tree-shaking是通过保留那些在项目过程中真正需要的代码从而清理你的构建过程的一种方式。你可以用Webpack 2来提出那些没用的住配置文件,用UnCSS或Helium从CSS中取出不需要的样式。同理,也可以考虑学习一下如何编写高效的CSS选择器,以及如何避免膨胀和高费的样式。
Code-splitting是另一个Webpack特性,它可以根据按需加载的块将你的代码分开。只要你在代码中定义了分离点,Webpack便会处理好相关的输出文件。它基本上能保证你初始下载的内容很小,而且在需求被添加时按需请求代码。
Rollup所展示的结果要比Browserify配置文件所显示的好得多。所以当我们想使用类似工具的时候,或许应该看看Rollupify,它将ECMAScript2015模块变成了一个更大的CommonJS模块——因为小模块没准有出乎意料的高性能成本,这源自于你对打包工具模块系统的选择。
使用类似CSS containment的方法对高消耗组建进行隔离,从而限制浏览器样式的范围,可以作用在为无canvas的浏览工作的布局和装饰工作中,或是用在第三方工具上。要确保页面滚动和出现动画效果时没有延迟,别忘了之前提到过的每秒60帧的原则。如果没办法做到,那就尽可能保证每秒帧数的大致范围在15到60帧。使用CSS中的will-change通知浏览器哪些元素和属性发生了变化。也记得要衡量渲染执行中的性能(可以用DevTools)。可以参照Udacity上Paul Lewis的免费课程——浏览器渲染优化,作为入门。还有一篇Sergey Chikuyonok的文章讲了如何正确的用GPU动画。
使用页面框架,对高消耗组建延迟加载(字体,JS文件,循环播放,视频和内嵌框架)。使用资源提示来节省在
dns-prefetch(指的是在后台执行DNS检索),preconnect(指要求浏览器在后台进行握手链接(DNS,TCP,TLS)),prerender(指要求浏览器在后台对特定页面进行渲染),preload(指的是提前取出暂不执行的源文件)。根据你浏览器的支持情况,尽量使用preconnect来代替dns-prefetch,而且在使用prefetch和prerender要特别小心——后者(prerender)只有在你非常确信用户下一步操作的情况下再去使用(比如购买流程中)。
Google开始向着更安全网页的方向努力,并且将所有Chrome上的HTTP网页定义为“不安全”时,你或许应该考虑是继续使用HTTP/1.1,还是将目光转向HTTP/2环境。虽然初期投入比较大,但是使用HTTP/是大趋势,而且在熟练掌握之后,你可以使用service worker和服务器推送技术让行性能再提升一大截。
现在,Google计划把所有HTTP页面标记为不安全,并且将HTTP安全指示器设置为与Chrome用来拦截HTTPS的红色三角相同的图标。使用HTTP/2的环境的缺点在于你要转移到HTTPS上,并且根据你HTTP/1.1用户的数量(主要指使用过时操作系统和过时浏览器的用户),你需要适应不同的建构过程,才能发送不同的建构。注意:不论是迁移还是新的构建过程都可能非常棘手而且耗时很多。
重申,使用HTTP/2协议之前,你需要彻底排查目前为止你所使用协议的情况。你需要在打包组建和同时加载很多小组间之间找到平衡。
一方面,你可能想要避免将很多资源链式链接,与其将你全部的界面分割成许多小模块,不如将他们压缩使之成为建构过程的一部分,之后给它们赋予可检索的信息并加载它们。这样的话,对一文件将不再需要重新下载整个样式清单或JavaScript文件。
另一方面,封装是很有必要的,因为一次向浏览器发送太多JavaScript文件会出问题。首先,压缩会造成损坏。得益于dictionary reuse,压缩大文件不会对文件造成损害,压缩小文件则不然。确实有方法可以解决这个问题,但这不是本文讨论的范畴。其次,浏览器还没有优化到可以对类似工作流进行优化。例如,Chrome会引发进程间通信(IPCs),这些通信的数量与资源的数量成正比,而这成百上千个资源将会消耗大量的浏览器的执行时间。
Chrome的Jake Archibald建议,为了用HTTP/2达到最好的效果,考虑一下逐步加载CSS文件
当然你可以考虑逐步加载CSS文件。很显然,你这样做对HTTP/1.1的用户非常不利,所以你可能需要根据不同的浏览器建立多个版本来应对你的调度过程,这样就会使过程略微复杂。你也可以避免HTTP/2连接的合并,同时受益于HTTP/2来使用域名碎片,但是实现起来有些困难。
我们到底应该做什么呢?如果你粗略的用过HTTP/2,似乎成功的发送过10个左右的包(在老是浏览器上运行的也不错)。那你就能着手开始试验并且为你的网站找到平衡点。
所有的浏览器都支持HTTP/2并且使用TLS,这是有你可能想要避免安全警告,并删除页面上没用的元素。好好检查你的安全头部是否设置正确,排除已知的缺陷并检查证书。
如果还没有迁移到HTTP, 你那可以先看看HTTPS准则(The HTTPS-Only Standard)。确保所有外部插件和监视脚本都能被HTTPS正确加载,确保没有跨站脚本出现,HTTP脚本传输的安全头和内容安全头也都设置正确。
这份清单综合性很强,几乎介绍了所有的可用的优化方式。那么,如果你只有一个小时进行优化,你应该干什么呢?让我们从中总结10个最有用的来。别忘了在你开始优化前和结束优化后,记录你的结果,包括开始渲染时间以及在3G,有限连接下的速度。
但没关系,本文只是一个普通大纲(希望能做到综合性强),你应该根据自己的工作环境列一份适合自己的清单。最重要的,在开始优化之前,先对项目中存在的问题有一个明确的了解。
转自:csdn论坛 ,
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
Web前端总结:
Web前端:HTML最强总结 附详细代码
Web前端:CSS最强总结 附详细代码
Web前端:JavaScript最强总结 附详细代码
层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。
层叠:多个样式可以作用在同一个html的元素上,同时生效
多个样式定义可层叠为一个CSS很像化妆,通过不同的CSS将同样的HTML内容打造为不同的呈现结果。 所以,前端程序员相互表白的时候可以说:you are the CSS to my HTML. 这是不是CSS是对HTML进行美化和布局作用的最好总结?
CSS与html结合使用
根据定义CSS的位置不同,分为行内样式、内部样式和外部样式
也称为内联样式
直接在标签中编写样式,通过使用标签内部的style属性;
代码样式:
弊端:只能对当前的标签生效,没有做到内容和样式相分离,耦合度太高。
定义在head标签内,通过style标签,该标签内容就是CSS代码
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>内部样式</title> <style> div{ color: red; } </style> </head> <body> <div>hello my css</div> </body> </html>
基本格式由两个主要的部分构成:
筛选具有相似特征的元素
选择具有相同id属性值的元素,建议html页面中的id值唯一
id 选择器可以为标有特定 id 的 HTML 元素指定特定的样式。
HTML元素以id属性来设置id选择器,CSS 中 id 选择器以 “#” 来定义。
PS: ID属性不要以数字开头,数字开头的ID在 Mozilla/Firefox 浏览器中不起作用。
虽然多个元素可以使用同一个id选择器控制样式,但是不推荐。如果需要同样的样式对多个标签生效, 使用class选择器。
选择具有相同的class属性值的元素。
PS:类名的第一个字符不能使用数字!它无法在 Mozilla 或 Firefox 中起作用
选择具有相同标签名称的元素。
定义选择器语法:标签名称{};PS:标签名称必须是html提供好的标签。
使用标签选择器:自动使用在所有的同名的标签上
ID选择器 > 类选择器 > 标签选择器
当多个选择器作用在同一个标签上的时候,如果属性冲突,看优先级;如果不冲突,样式叠加生效
行内样式 > 内部样式 >外部样式
同样,三个样式表中都有内容作用在同一个html标签的时候,如果属性冲突,看优先级;如果不冲突, 样式叠加生效
跟颜色相关的取值分3种:
PS:只有块状元素可以设置宽高,行级元素设置不生效
取值方式有2种:
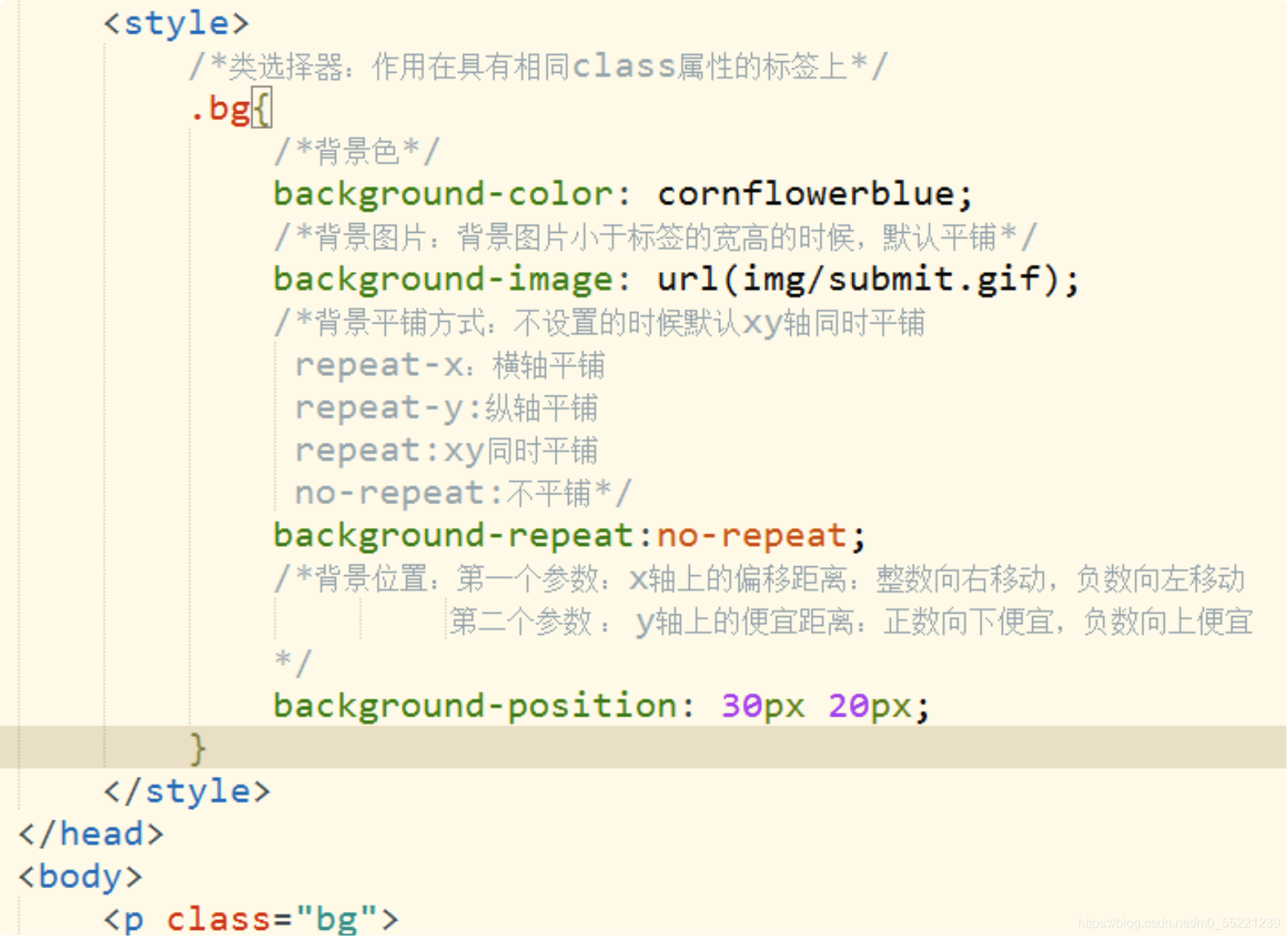


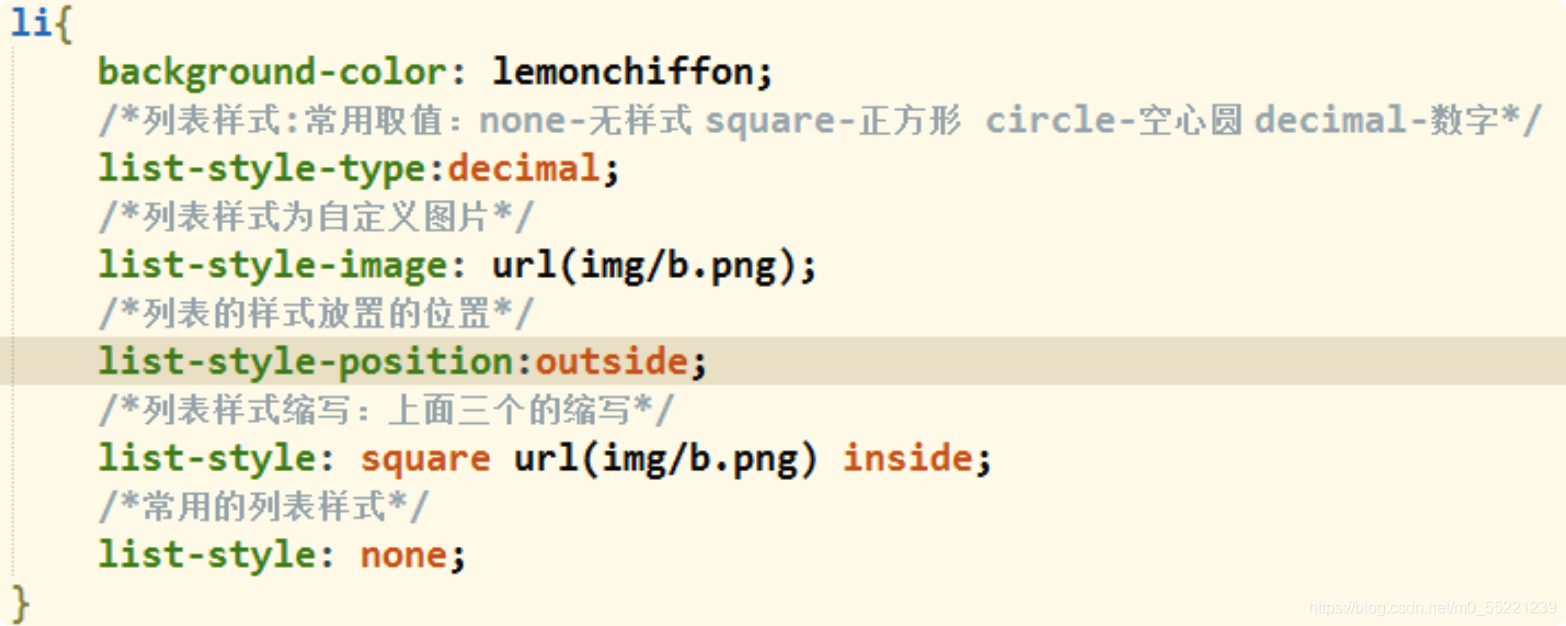
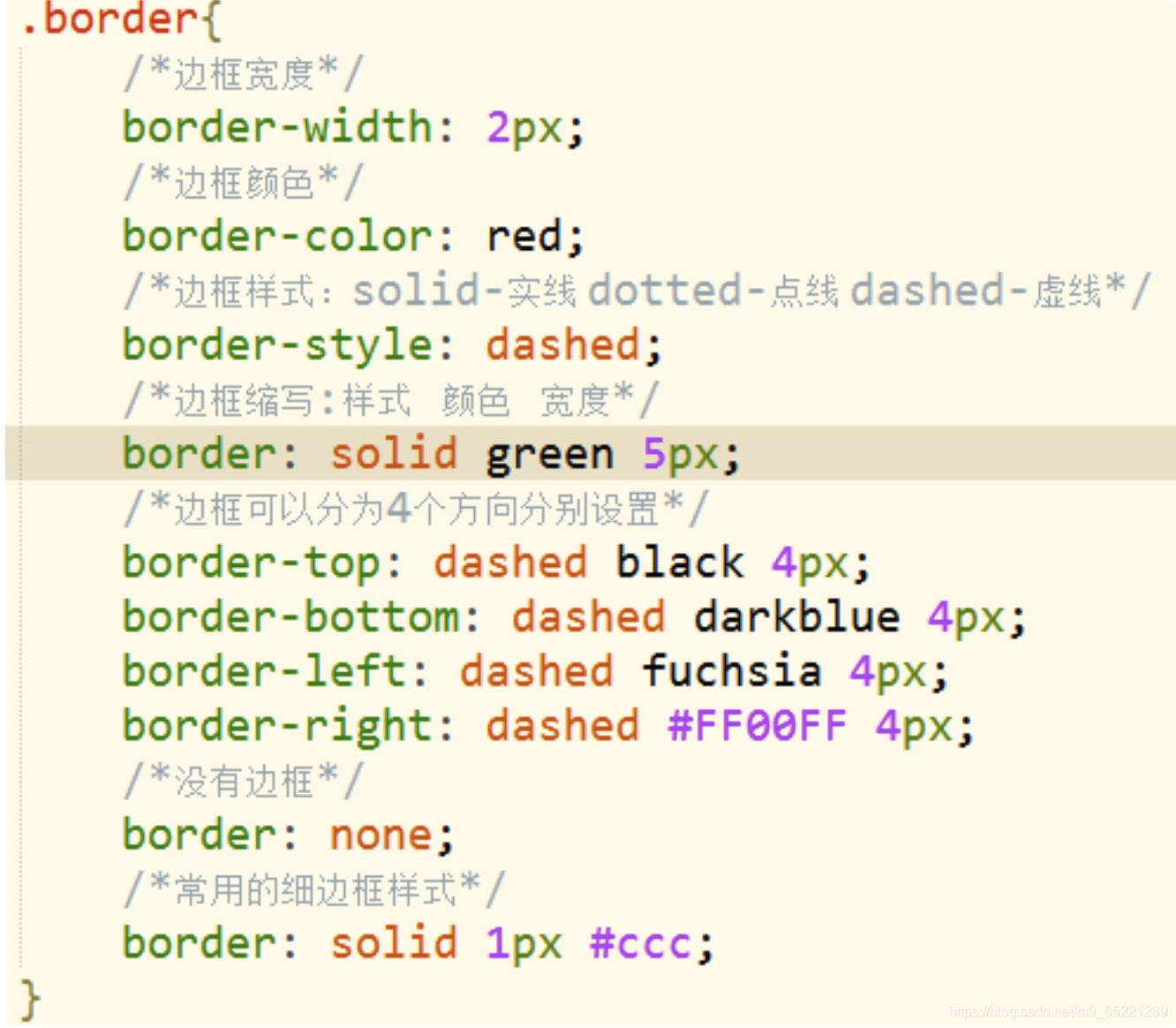
以谷歌浏览器为例说明。
快捷键F12或者工具条中的开发者工具调出以下内容。
在elements中可以看到当前页面的所有标签,在styles中可以看到html元素对应的样式。
条件:交集选择器由两个选择器构成,找到的标签必须满足:既有标签一的特点,也有标签二的特点。
语法:h3.class{ color:red; } 其中第一个为标签选择器,第二个为class选择器,两个选择器之间不能有空格,例如div.list。
交集选择器是并且的意思。 即…又…的意思
例如: table.bg 选择的是: 类名为 .bg 的 表格标签,但用的相对来说比较少。
概念
后代选择器又称为包含选择器。
作用
用来选择元素或元素组的子孙后代
其写法就是把外层标签写在前面,内层标签写在后面,中间用空格分隔,先写父亲爷爷,再写儿子孙子。
格式:父级 子级{属性:属性值;属性:属性值;}
语法:.class h3{color:red;font-size:16px;}
当标签发生嵌套时,内层标签就成为外层标签的后代。 子孙后代都可以这么选择。 或者说,它能选择任何包含在内 的标签。
作用:子元素选择器只能选择作为某元素子元素(亲儿子)的元素。 其写法就是把父级标签写在前面,子级标签写在后面,中间跟一个 > 进行连接。
语法:.class>h3{color:red;font-size:14px;}
比如:
.demo > h3 {color: red;} 说明 h3 一定是demo 亲儿子。 demo 元素包含着h3
转自:csdn论坛 ,
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
区块链
区块链(Blockchain)是指通过去中心化和去信任的方式集体维护一个可靠数据库的技术方案。该技术方案让参与系统中的任意多个节点,把一段时间系统内全部事务通过密码学算法计算并记录到一个数据块(block),生成该数据块的hash用于链接下个数据块,系统所有参与节点来共同检验记录是否为真,并且每个区块的内容都由后续子链上的区块来保证其内容不可被篡改。 各个参与节点可以在新区块产生确认及奖励分配上达成共识,从而逐渐形成的一个庞大、去中心化的公开账本。
01 对比特币的认识
2008年,中本聪(Satoshi Nakamoto)发表了一篇题为“比特币:一种点对点的电子现金系统”的论文描述了比特币的模式。
新区块的创造过程是一个区块创造权的竞争的过程,即通过工作量证明来选定新区块的创造者。在任何一个特定的时间点上,整个区块链系统范围内的,所有竞争者在同时开始,共同针对同一特定新候选区块进行哈希运算比赛。获胜的条件是最先算出符合该特定新候选区块要求的哈希值。获胜的(只能有一个获胜者)奖励是伴随该新区块一起发行的全部新比特币。当一个新区块被创造出来了,所有的竞争者马上重新开始进行对下一个区块创造权的竞争。
新区块的创造速度大概是10分钟一块。
比特币的存储依靠的就是分布式账本技术。比特币就是一串数据代码。所有的比特币就是记录于区块链中各自对应的区块内,然后分布式存放于比特币系统的各个节点上。比特币区块链就像是一个由比特币系统所有的节点共享的统一电子账本。
比特币的使用就是比特币的交易,也就是比特币所有权的转换。比特币的使用主要是通过加密技术来实现的
02 对以太坊的认识
以太坊是一个具有智能合约功能的开放区块链平台,使开发人员能够建立和发布各种分布式应用。通过在以太坊上编程建立各种分布式应用可以解决诸如:投票、域名、金融交易、众筹、公司管理、合约、知识产权、硬件集成的智能资产等等各方面问题。
以太坊,与比特币区块链技术一样,使用激励驱动的安全模式。共识达成基于选择具有最高总难度的区块。矿工创建区块,其他人检测有效性。
以太币是于2015年7月30日开始发行的。类似于比特币,以太币的发行方式也是采用工作量证明机制(POW)。通过工作量证明机制,以太坊每年发行15,626,576枚以太币。以太坊计划于2017年末将以太币的发行方式改为权益证明机制(POS)。届时,每年的新发行的以太币数量为1000万枚。以太币的总发行量是没有上限的。
以太坊是通过在比特币区块链系统基础上进行修改和创新而产生的。以太坊本质上就是:区块链+智能合约
(1) 什么是以太坊虚拟机
同比特币区块链系统不同,以太坊设计了以太坊虚拟机(EVM)专门用来运行智能合约。太坊虚拟机是一个同网络,文件系统或者其他操作过程隔绝开来的封装起来的计算机代码运行环境.
(2)以太坊的账户
以太坊的基础单元是账户. 这些账户可以通过消息传递来发生互动变化。每个账户都有一个与之关联的状态和一个20字节的地址。所有价值和信息的转移都体现为账户状况的变化.以太坊区块链通过控制所有账户的变化实现其各种功能.
以太坊有两类账户: 外部账户和合约账户,他们被存放于同一地址空间上.外部账户是由人类用户通过对应的公私钥来掌控。而合约账户则是由被存储在其内部的代码掌控。智能合约指的是合约账户中的那些对被发送来的交易进行自动处理的程序代码。用户可以通过在区块链中存储程序代码来创建新的智能合约。
以太坊账户状态的变化就是指以太坊账户组成成分发生的变化。以太坊账户含有四个组成部分:
(1) 序号(nonce):如果账户是一个外部拥有账户,nonce代表从此账户地址发送的交易序号。如果账户是一个合约账户,nonce代表此账户创建的合约序号。
(2) 余额(balance): 此地址拥有Wei的数量。
(3) Merkle 树根的哈希值: Merkle树会将此账户存储内容的哈希值进行编码,默认值是空值。
(4) 代码哈希值:此账户太坊虚拟机内的代码的哈希值。对于合约账户,就是被哈希的代码并作为代码哈希值保存起来。对于外部账户,代码哈希值是一个空字符串的哈希值。
(3)以太坊的交易和交易费用
太坊区块链系统只有两种类型的交易:合约创建和消息通信。
以太坊所有的交易都是在外部账户触动下发生的.合约账户不会自发地产生任何行动. 只有当外部账户发出交易时,合约账户才会执行相应的操作。以太坊通过规定节点必须与运算结果保持一致,从而保证智能合约严格确定执行。
在以太坊中一个重要的概念就是费用(fees). 发生在以太坊区块链系统内的交易而产生的每一次计算都会要求相应的费用。这个费用是以”gas”的来支付。gas就是用来衡量在一个具体计算中要求的费用单位。gas 价格(gas price)就是你愿意在每个gas花费ETH的数量,以“gwei”进行衡量。“Wei”是ETH的最小单位,1ETH表示10^18Wei. 1gwei是1,000,000,000 Wei。
发生交易时,交易发送者先设置gas limit和gas price。gas limit和gas price就代表着发送者愿意为执行交易支付的Wei的最大值。以太坊用户必须向以太坊区块链系统支付少量交易费用。交易的发送者必须在激活的合约账户的每一步为所有的运算和数据存储付费。如果在他们的账户余额中有足够的Ether来支付这个最大值费用,那么就没问题。在交易结束时任何未使用的gas都会被返回给发送者,以原始费率兑换。费用通过以太坊Gas结算,以太币的形式支付的。这样可以帮助太坊区块链系统避免被滥用或被恶意攻击.
交易费用由节点收集,节点在以太坊网络中完成收集、传播、确认和执行交易的工作。矿工们将交易活动分组:交易记录(以太坊区块链中账户状态的更新)被分组存放在区块中;节点通过互相竞争决定添加权;获得添加权的节点将新的区块添加到区块链的上。获得添加权的节点会得到以太币奖励,通过这些奖励激励节点为以太坊区块链系统贡献硬件和电力。
(4)以太坊的状态变化机制
第一步,检查交易的格式是否正确(即有正确数值)、签名是否有效和随机数是否与发送者账户的随机数匹配。如否,返回错误。
第二步,计算交易费用,并从签名中确定发送者的地址。从发送者的账户中减去交易费用和增加发送者的随机数。如果账户余额不足,返回错误。
第三步,设定初值GAS = STARTGAS,并根据交易中的字节数减去一定量的Gas值。
第四步,从发送者的账户转移价值到接收者账户。如果接收账户还不存在,创建此账户。如果接收账户是一个合约,运行合约的代码,直到代码运行结束或者燃料用完。
第五步,如果因为发送者账户没有足够的钱或者代码执行耗尽燃料导致价值转移失败,恢复原来的状态,但是还需要支付交易费用,交易费用加至矿工账户。
第六步,否则,将所有剩余的燃料归还给发送者,消耗掉的燃料作为交易费用发送给矿工。
03 **对Hyperledger的认识
04 了解其他那些区块链项目 Corda EOS
05 公链、联盟链、私链的区别
中本聪巧妙地将以下几个成熟的技术和理论组合的一起,并以此为基础构建区块链技术:
基于去中心化的分布式算法而建立起点对点对等(P2P)网络。
基于非对称加密算法。
基于分布式一致性算法,解决了分布式场景下的拜占庭将军问题。
基于博弈论而精心设计的奖励机制,实现了纳什均衡,确保整个系统的安全和稳定运行。
如果同时具有上述四点要素,可以认为这是一种公共区块链技术,简称公有链。如果只具有前三点要素,将其称为私有区块链技术,简称私有链。而联盟链则介于两者之间,可视为联盟成员内的一种私有链。这里主要介绍公有链和私有链。
公链是指全世界任何人都可读取的、任何人都能发送事务且能获得有效确认的、任何人都能参与共识过程的区块链。共识过程决定哪个区块可被添加到区块链中和明确当前状态。作为中心化或者准中心化信任的替代物,公有链的安全由加密数字经济维护。加密数字经济采取工作量证明机制或权益证明机制等方式,将经济奖励和加密数字验证结合了起来,并遵循着一般原则:每个人从中可获得的经济奖励,与对共识过程作出的贡献成正比。这些区块链通常被认为是完全去中心化的。
私有链是指其写入权限仅在一个组织手里的区块链。读取权限或者对外开放,或者被限制。相关的应用囊括数据库管理、审计、甚至一个公司,尽管在有些情况下希望它能有公共的可审计性,但在很多的情形下,公共的可读性并非是必须的。
私有链相比于公有链的优点:
事务的效率更高:比特币区块链目前每秒可完成7笔事务,而私有链目前最高可以到每秒10万笔,并且还有提高的空间。显然后者更适应现实世界金融事务的需求。
事务可以回滚:这点对于中心化机构也很重要,在某些情况下,某些事务会因为错误或法律的问题而被要求修改、撤销。
事务费用更低:目前公有链的事务费用是每笔0.10美元,而且随着时间流逝币值趋于增长,导致事务费用也在增长。而私有链的事务费用将会降低一到两个数量级。
仍然是基于分布式网络,保留了分布式记账系统的优点。
提供了更好的隐私保护:公有区块链因为其透明共享总账本的设计,本身不提供隐私保护功能。而私有链可以对读取权限进行限制,从而提供更好的隐私保护。
验证者是公开透明的,不存在一些矿工出于共谋原因而致的51%攻击风险。
节点可以很好地连接:节点互相可以很好地连接,故障可以迅速通过人工干预来修复,并允许使用共识算法减少区块时间,从而更快完成事务。
私有链的缺点:
违背了区块链去中心化的本质,重新引入了若干“信任节点”;
其参与者需要经过审核和验证,从而严格限制了其规模,其安全性容易受到威胁。因此,私有区块链更适合为传统机构所用。
公有链的优点:
保护用户:免受开发者的影响——在公共区块链中的用户更多、更广泛,程序开发者无权干涉
用户的使用方式。反过来说,区块链可以保护使用这些程序的用户。
网络规模效应——公共区块链是开放的,因此有可能被许多外界用户使用和产生一定的网络效应。而在公有链上运行的应用越多,节点越多,那么该区块链条也会越可信。
因此使用公有链,还是私有链,完全根据需求而定。
06 了解哪些共识算法
07 说说最熟悉的共识算法
08 看过哪些书
09 以太坊智能合约
10 拜占庭问题
在互联网大背景下,当需要与不熟悉的对方进行价值交换活动时,人们如何才能防止不会被其中的恶意破坏者欺骗、迷惑从而作出错误的决策。进一步将“拜占庭将军问题”延伸到技术领域中来,其内涵可概括为:在缺少可信任的中央节点和可信任的通道的情况下,分布在网络中的各个节点应如何达成共识
11 51%算力攻击
在比特币网络中,采用PoW共识机制来解决如何获得记账权的问题,采用“最长链共识”解决如何记账的问题。
所谓51%的攻击,就是利用比特币网络采用PoW竞争记账权和“最长链共识”的特点,使用算力优势生成一条更长的链“回滚”已经发生的“交易行为”。
51%是指算力占全网算力的51%,比特币网络需要通过哈希碰撞来匹配随机数从而获得记账权,算力衡量的是一台计算机每秒钟能进行哈希碰撞的次数。
算力越高,意味着每秒钟能进行越多次的哈希碰撞,即获得记账权的几率越高。
在理论上,如果掌握了50%以上的算力,就拥有了获得记账权的绝对优势,可以更快地生成区块,也拥有了篡改区块链数据的权利。
实际上,当恶意攻击者持有比特币全网占比比较高的算力时,即使尚未达到51%的比例,也可以制造相应的攻击,比较典型的就是双花问题。
12 Sybil攻击
在对等网络中,但节点通常具有多个身份标识,通过控制系统的大部分节点来消弱冗余备份的作用
13 Eclipse攻击
Eclipse攻击是一种网络级的攻击,攻击者模仿所有其他节点的入流量和出流量,达到将受害者与网络上的其他节点隔离的目的。这种攻击意味着通过让最新的区块信息不能到达节点来达到隔离节点的目的。事实上,比特币网络也易受到eclipse攻击。但在以太坊网络上,两个节点就足以发起eclipse攻击。
14 DDoS攻击
是指处于不同位置的多个攻击者同时向一个或数个目标发动攻击,或者一个攻击者控制了位于不同位置的多台机器并利用这些机器对受害者同时实施攻击。由于攻击的发出点是分布在不同地方的,这类攻击称为分布式拒绝服务攻击,其中的攻击者可以有多个。
15 Merkle Tree数据结构
A、Merkle树结构
由一个根节点(root)、一组中间节点和一组叶节点(leaf)组成。叶节点(leaf)包含存储数据或其哈希值,中间节点是它的两个孩子节点内容的哈希值,根节点也是由它的两个子节点内容的哈希值组成。所以Merkle树也称哈希树。
B、哈希树的特点
叶节点存储的是数据文件,而非叶节点存储的是其子节点的哈希值(Hash,通过SHA1、SHA256等哈希算法计算而来),这些非叶子节点的Hash被称作路径哈希值(可以据其确定某个叶节点到根节点的路径),
叶节点的Hash值是真实数据的Hash值。因为使用了树形结构, 其查询的时间复杂度为 O(logn),n是节点数量。
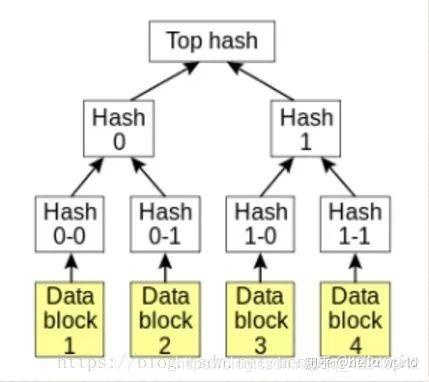
默克尔树的另一个特点是,底层数据的任何变动,都会传递到其父节点,一直到树根。
16 哈希算法
哈希算法(Hash)又称摘要算法(Digest),它的作用是:对任意一组输入数据进行计算,得到一个固定长度的输出摘要。
哈希算法最重要的特点就是:
相同的输入一定得到相同的输出;
不同的输入大概率得到不同的输出。
哈希算法的目的就是为了验证原始数据是否被篡改。
17 看过那些白皮书 bitcoin ethereum EOS
18 未来你看好那些区块链项目
19 区块链的应用场景
20 以太坊协议 ERC20 ERC721 ERC223 ERC875
21.什么是挖矿?
挖矿是在区块链网络达成共识的过程。挖矿有两个目的。首先,它在生成的块中创建新的代币。其次,它通过向网络提供工作证明,包括分布式计费中的交易;也就是说,证明所生成的块是有效的。
22.比特币实现中的交易和块是如何加密的?
比特币块不以任何方式加密:每个块都是公开的。阻止修改和保证数据完整性的是一个称为块哈希的值。块的内容是使用在比特币的一种特殊Hash函数来处理,它的实现和得到的值包含在区块链中。
23.什么是软分叉?
在分类帐中的块包括以建立最长链的方式,即具有最大累积难度的链。分叉是有两个候选块竞争形成最长的区块链,两个矿工发现工作问题的证明方法在很短的时间内没有同步对方的情况。造成网络分割,因为某些节点得到块从矿工#1和而另外一些得到矿工#2。 分叉通常在一个块中得到解决,因为这种情况再次发生的概率变得非常低,因为下一个块出现,所以很快有一个新的最长链,将被认为是主要的。
**24.**什么是双重支出?
这是与数字货币有关的主要问题之一。 事实上,这是一个数字通证被多次使用的条件,因为通证通常由易于克隆的数字文件组成。它只会导致通货膨胀,组织不得不承受巨大的损失。 区块链技术的主要目标之一是尽可能地消除这种方法。
------开发基础篇--------
01 go语言问题
02 solidity语言语法问题
03 c/c++语言语法问题
04 java语言语法问题
问:以太坊的有价通证叫什么?
答:以太(ETH:Ether)
问:Wei和以太有什么区别?
答:Wei是一个面额,像美分到美元或便士到磅。 1 ETH =10^18 Wei
问:以太坊的平均出块时间是多少?
答:大约14秒
问:以太坊的平均块大小是多少?
答:大约2KB,实际值取决于具体情况。
问:以太坊是否支持脚本? 如果是这样,支持什么类型的脚本?
答:是的。 它支持智能合约
问:你如何得到以太?
答:有几种方法:
1.成为一名矿工
2.用其他货币换取
3.使用以太Faucet,例如 https://faucet.metamask.io
4.接受别人的赠送
问:以太从哪里来的?
答:在2014年预售中首次创建了6000万个。另外,在挖出新块时也会生成以太。
问:什么是节点?
答:一个节点本质上是一台连接到网络的计算机,它负责处理交易。
问:你熟悉多少种以太坊网络?
答:有三种类型的网络 - 实时网络(主),测试网络(如Ropsten和Rinkeby)和私有网络。
问:与以太坊网络交互的方式有哪些?
答:可以使用电子钱包或DApp
问:你可以“隐藏”一个以太坊交易吗?
答:不可以。所有交易对每个人都是可见的。
问:交易记录在哪里?
答:在公共账本上。
问:这些网络的ID是什么?
答:Live(id = 1),Ropsten(id = 3),Rinkeby(id = 4),Private(由开发人员分配)
问:我可以在Rinkeby测试网络中挖一些以太,然后转移到Live网络吗?
答:不可以。不能在不同的以太坊网络之间传递以太。
问:为什么需要私有网络?
答:有很多原因,但主要是为了数据隐私、分布式数据库、权限控制和测试。
问:你如何轻松查看有关交易和区块的详细信息?
答:使用区块链浏览器,如etherscan.io或live.ether.camp
问:私有网络的交易和区块信息怎么查看呢?
答:可以使用开源浏览器客户端,例如https://github.com/etherparty/explorer
问:区块链的共识是什么?
答:遵循特定协议(如以太坊)验证交易(创建块)的过程。
问:区块链中两种常用的共识模型是什么?
答:工作量证明(POW)和权益证明(POS)。
问:简单地解释下工作量证明。
答:它实际上是矿工为了证明自己的工作量并验证交易而对一个计算密集型问题的求解。
问:以简单的方式解释权益证明。
答:区块的创建者是根据节点所持有的财富和股权随机选择的。 它不是计算密集型的。
问:以太坊使用什么共识模式?
答:截至2018年初,它使用工作量证明,但今后将切换到权益证明。
问:怎么挖以太币?
答:使用钱包或geth客户端。
问:用什么来对交易进行签名?
答:用户的私钥。
问:丢失私钥后还能恢复以太坊账户吗?
答:可以,可以使用助记词组。
问:有哪些方法可以连接到一个以太坊节点?
答:IPC-RPC、JSON-RPC和WS-RPC。
问:那么Geth是什么?
答:Geth是以太坊的客户端。
问:连接到geth客户端的默认方式是什么?
答:默认情况下启用IPC-RPC,其他RPC都被禁用。
问:你知道geth的哪些API?
答:Admin、eth、web3、miner、net、personal、shh、debug和txpool。
问:你可以使用哪些RPC通过网络连接到geth客户端?
答:可以使用JSON-RPC和WS-RPC通过网络连接到geth客户端。 IPC-RPC只能连接到同一台机器上的geth客户端。
问:如果启动geth时使用了-rpc选项,哪些RPC会被启用?
答:JSON-RPC。
问:哪些RPC API是默认启用的?
答:eth、web3和net。
问:如何为JSON RPC启用Admin API?
答:使用-rpcapi选项。
问:选项-datadir有什么作用?
答:它指定了区块链的存储位置。
问:什么是geth的“快速”同步,为什么它更快?
答:快速同步会将事务处理回执与区块一起下载并完整提取最新的状态数据库,而不是重新执行所有发生过的交易。
问:选项–testnet是做什么的?
答:它将客户端连接到Ropsten网络。
问:启动geth客户端会在屏幕上输出大量文字,应该如何减少输出信息?
答:可以将–verbosity设置为较低的数字(默认值为3)
问:如何使用IPC-RPC将一个geth客户端连接到另一个客户端?
答:首先启动一个geth客户端,复制它的管道位置,然后使用同一个datadir启动另一个geth客户端并使用–attach选项传入管道位置。
问:如何将自定义javascript文件加载到geth控制台中?
答:通使用–preload选项传入js文件的路径。
问:geth客户端的帐户存储在哪里?
答:在keystore目录中。
问:为了进行交易,需要对账户进行什么操作?
答:必须先解锁该账户 - 可以传入账户地址或账户序号来解锁。 也可以使用–password选项传入一个密码文件,其中包含每个账户的密码。
问:你提到了一些有关账户序号的内容。 什么因素决定账户的序号?
答:添加帐户的先后顺序。
问:是否可以使用geth进行挖矿?
答:可以,使用–mine选项开启。
问:什么是“etherbase”?
答:这是接收挖矿奖励的帐户,它是序号为0的帐户。
问:什么是智能合约?
答:这是用多种语言编写的计算机代码。 智能合约存在于以太坊网络上,它们根据预定规则执行动作,规则是由参与者在这些合约中商定的。
问:智能合约可以使用哪些语言编写?
答:Solidity,这是最常用的语言,也可以使用Serpent和LLL。
问:你能举出一个智能合约的用例吗?
答:卖方-买方应用场景:买方在智能合约中存入款项,卖方看到存款并发送货物,买方收到货物并放行付款。
问:什么是Metamask?
答:Metamask是一个可以帮助用户在浏览器中与以太坊网络进行交互的工具
问:Metamask使用哪个以太坊节点?
答:它使用infura.io
问:Metamask不支持什么?
答:挖矿和合约部署。
问:执行合约是否免费?
答:不,调用合约方法是一个交易,因此需要支付费用。
问:访问智能合约的状态是否免费?
答:是的,查询状态不是交易。
问:谁执行合同?
答:矿工。
问:为什么调用智能合约的方法需要付费?
答:有些方法不会修改合约的状态,也没有其他逻辑,只是返回一个值,这样的方法是可以免费调用的。 调用那些改变合约状态的方法则需要付费,因为它们需要gas来执行。
问:为什么需要gas?
答:由于矿工在他们的机器上执行合约代码,他们需要gas来覆盖执行合约代码的成本。
问:是不是gas的价格决定了交易什么时候被处理?
答:即是,也不是。 gas价格越高,交易成功的可能性就越大。 尽管如此,gas价格并不能保证更快的交易处理。
问:交易中的gas使用量取决于什么?
答:这取决于合约所用的存储量、指令(操作码)的类型和数量。 每个EVM操作码都对应一个固定的gas用量。
问:交易费是如何计算的?
答:gas用量*gas价格(由调用方指定gas价格)
问:如果智能合约的执行成本低于调用方指定的gas用量,用户是否得到退款?
答:是的
问:如果智能合约的执行成本高于指定的gas用量,会发生什么情况?
答:用户不会得到退款,并且一旦所有的gas用完,执行就会停止,合约也不会改变。
问:谁支付智能合约的调用费用?
答:调用合约的用户。
问:节点在什么上面运行智能合约代码?
答:EVM - 以太坊虚拟机。 EVM遵循EVM规范,该规范是以太坊协议的组成部分。 EVM只是节点上的一个进程。
问:为了运行智能合同,EVM需要什么?
答:它需要合约的字节码,是通过编译Solidity等更高级别的语言编写的合约来生成字节码。
问:粗略的说,EVM有哪些组成部分?
答:内存区域、堆栈和执行引擎。
问:什么是Remix?
答:开发,测试和部署合约的在线工具。 适合快速构建和测试轻量级合约,但不适合更复杂的合约。
问:在Remix中,可以连接哪些节点?
答:可以使用Metamask连接到公共节点、也可以链接到使用Geth搭建的本地节点,或者在Javascript VM中模拟的内存节点。
问:什么是DApp,它与App有什么不同?有什么不同?
答:App通常包含一个客户端,这个客户端会与一些中心化的资源(由一个组织拥有)进行通信,通常客户端通过一个中间层连接到中心化的数据层,如果中心化的数据层中的信息丢失,不能很轻松地恢复。
DApp表示去中心化应用程序。 DApps通过智能合约与区块链网络进行交互。 DApp使用的数据驻留在合约实例中。
中心化数据可能比去中心化数据更容易受到破坏。
问:DApp的前端是否局限于某些技术或框架?
答:不受限制。可以使用任何技术来开发DApp的前端,比如HTML,CSS,JS,Java,Python…
问:前端用什么库连接后端(智能合同)?
答:Web3.js库。
问:在DApp的前端需要哪些东西才能与指定的智能合约进行交互?
答:合约的ABI和字节码。
问:ABI有什么作用?
答:ABI是合约的公开接口描述对象,被DApps用于调用合约的接口。
问:字节码有什么作用?
答:节点上的EVM只能执行合约的字节码。
问:为什么要使用BigNumber库?
答:因为Javascript不能正确处理大数。
问:为什么需要检查在Web DApp代码的开始部分是否设置了web3提供器(Provider)?
答:因为Metamask会注入一个web3对象,它覆盖其他的web3设置。
问:为什么要使用web3.js版本1.x而不是0.2x.x?
答:主要是因为1.x的异步调用使用Promise而不是回调,Promise目前在javascript世界中
是处理异步调用的首选方案。
问:如何在web3 1.x中列出账户?
答:web3.eth.getAccounts
问:.call和.send有什么区别?
答:.send发送交易并支付费用,而.call查询合约状态。
问:这样发送1个以太对吗:.send({value:1})?
A:不对,这样发送的是1 wei。 交易中总是以wei为单位。
问:那么为了发送1个以太,我必须将这个值乘以10^18?
答:可以使用web3.utils.toWei(1,‘ether’)。
问:调用.send()时需要指定什么?
答:必须指定from字段,即发送账户地址。 其他一切都是可选的。
问:web3.eth.sendTransaction()的唯一功能是将以太发送到特定的地址,这个说法是否正确?
答:不对,也可以用它调用合约方法。
问:你是否知道以太坊的可扩展性解决方案?
答:2层协议。可能的解决方案是状态通道(state channels)和Plasma。
Solidity
问:Solidity是静态类型的还是动态类型的语言?
答:它是静态类型语言,这意味着类型在编译时是已知的。
问:Solidity中与Java“Class”类似的是什么?
答:合约。
问:什么是合约实例?
答:合约实例是区块链上已部署的合约。
问:请说出Java和Solidity之间的一些区别。
答:Solidity支持多重继承,但不支持重载。
问:你必须在Solidity文件中指定的第一件事是什么?
答:Solidity编译器的版本,比如指定为^ 0.4.8。 这是必要的,因为这样可以防止在使用其他版本的编译器时引入不兼容性错误。
问:合约中包含什么?
答:主要由存储变量、函数和事件组成。
问:合约中有哪些类型的函数?
答:有构造函数、fallback函数、修改合约状态的函数和只读的constant函数。
问:如果我将多个合约定义放入单个Solidity文件中,我会得到什么错误?
答:将多个合约定义放入单个Solidity文件是完全正确的。
问:两个合约之间交互的方式有哪些?
答:一个合约可以调用另一个合约,也可以继承其他合约。
问:当你尝试使用部署一个包含多个合约的文件时会发生什么?
答:编译器只会部署该文件中的最后一个合约,而忽略所有其他合约。
问:如果我有一个大项目,我需要将所有相关的合约保存到一个文件中吗?
答:不需要。可以使用import语句导入其他合约文件,例如import “./MyOtherContracts.sol”;。
问:我只能导入本地合约文件吗?
答:还可以使用HTTP协议导入其他合约文件,例如从Github导入:import “http://github.com/owner/repo/path_to_file”;。
问:EVM的内存分成了哪些部分?
答:它分为Storage、Memory和Calldata。
问:请解释一下Storage。
答:可以把它想象成一个数据库。 每个合约管理自己的Storage变量。 它是一个键-值数据库(256位键值)。
就每次执行使用的gas而言,在Storage上读取和写入的成本更高。
问:请解释一下Memory。
答:这是一个临时存储区。 一旦执行结束,数据就会丢失。 可以在Memory上分配像数组和结构这样复杂的数据类型。
问:请解释一下Calldata 。
答:可以把calldata视为一个调用堆栈。 它是临时的、不可修改的,用来存储EVM的执行数据。
问:哪些变量存储在Storage,那些变量存储在Memory?
答:状态变量和局部变量(它们是对状态变量的引用)存储在Storage区域, 函数参数位于Memory区域。
转自:csdn论坛 ,
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
众所周知,Vue项目采用了数据双向绑定和虚拟DOM基础,在数据驱动代替DOM频繁渲染已经算是非常高效了,对开发者而言已经非常优化了,那为什么还会有Vue性能优化这一说呢?
因为目前Vue 2.x使用了webpack等第三方打包构建工具,并且支持其他第三方的插件,我们在项目中使用这些工具时可能不同的操作在运行或打包效率上会有不同的效果,下面就来详细说明优化的方向。
1 v-if 和 v-show 的使用
v-if 为false的时候不会渲染DOM到视图,为true的时候才会渲染到视图;
v-show 不管初始条件是什么,元素总是会渲染到视图,只是简单地基于 CSS 的 display 属性进行切换。
最佳实践:频繁切换显示隐藏的元素采用v-show,很少改变使用v-if
2 computed 和 watch 区分使用
computed: 是计算属性,依赖其它属性值,并且 computed 的值有缓存,只有它依赖的属性值发生改变,下一次获取 computed 的值时才会重新计算 computed的值;
watch: 更多的是「观察」的作用,类似于某些数据的监听回调 ,每当监听的数据变化时都会执行回调进行后续操作;
最佳实践:当我们需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时,都要重新计算;当我们需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许我们执行异步操作 ( 访问一个 API ),限制我们执行该操作的频率,并在我们得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
3 v-for 遍历必须为 item 添加 key,且避免同时使用 v-if
现在不加key一般会报错的,添加key可以方便 Vue内部机制精准找到该条列表数据。当更新时,新的状态值和旧的状态值对比,较快地定位到 diff
v-for比 v-if 优先级高,如果每一次都需要遍历整个数组,将会影响速度,尤其是当之需要渲染很小一部分的时候,必要情况下应该替换成 computed属性。
4 纯显示长列表性能优化
对于只用来展示用的数据,不需要做vue做数据劫持,只需要冻结这个对象即可:
export default { data () { return { users: [] } }, created () { axios.get('/api/users').then((res)=>{ this.users = Object.freeze(res.data.users) }) } }
5 事件的销毁
Vue 组件销毁时,会自动清理它与其它实例的连接,解绑它的全部指令及事件监听器,但是仅限于组件本身的事件。 如果在 js 内使用 addEventListene 等方式是不会自动销毁的,我们需要在组件销毁时手动移除这些事件的监听,以免造成内存泄露,如:
created() { addEventListener('click', this.click, false) }, beforeDestroy() { removeEventListener('click', this.click, false) }
6 图片资源懒加载
使用vue-lazyload插件:
安装
npm install vue-lazyload --save-dev
1
man.js 引用
import VueLazyload from 'vue-lazyload' Vue.use(VueLazyload) // 或自定义 Vue.use(VueLazyload, { preLoad: 1.3, error: 'dist/error.png', loading: 'dist/loading.gif', attempt: 1 })
修改img标签
<img v-lazy="/static/img/1.png">
1
7 路由懒加载
Vue 是单页面应用,可能会有很多的路由引入 ,这样使用 webpcak 打包后的文件很大,当进入首页时,加载的资源过多,页面会出现白屏的情况,不利于用户体验。如果我们能把不同路由对应的组件分割成不同的代码块,然后当路由被访问的时候才加载对应的组件,这样就更加高效了。这样会大大提高首屏显示的速度,但是可能其他的页面的速度就会降下来。
const Foo = () => import('./Foo.vue') const router = new VueRouter({ routes: [ { path: '/foo', component: Foo } ] })
8 第三方插件按需引入
我们在使用第三方库的时候,最好是按需引入而不是全局引入,因为第三方库的插件比较多全部引入会打包比较慢,如Element UI、Ant Design of Vue等UI库:
按需引入
import Vue from 'vue'; import { DatePicker } from 'ant-design-vue'; Vue.use(DatePicker);
1
2
3
全局引入
import Antd from 'ant-design-vue'; Vue.use(Antd);
1
2
9 优化无限列表性能
如果你是在渲染带无限滚动加载的列表时,那么需要采用 窗口化 的技术来优化性能,只需要渲染少部分区域的内容,减少重新渲染组件和创建 dom 节点的时间。 你可以参考以下开源项目 vue-virtual-scroll-list 和 vue-virtual-scroller来优化这种无限列表的场景的。
大家自己去Github看使用说明吧。
10 服务端渲染 SSR or 预渲染
一般单页应用是在浏览器端完成页面渲染的,数据是发请求从后台拿过来的;而服务器端渲染SSR是页面元素的结构(HTML)是在服务器端就已经构建好的,直接把整个页面返回到客户端的。
那SSR有什么优缺点呢:
更好的SEO:网络爬虫可以直接爬取页面信息利于被搜索引擎收录,而ajax异步请求的内容不会被收录,所以通过SSR渲染的完整的页面信息更利于SEO;
支持的钩子函数只支持 beforCreate 和 created,服务器需要处于Node Server环境;
需要更高的服务器配置:因为它包含了数据处理和页面渲染,所以服务器开支变大
如果对首屏加载速度要求比较高或对SEO有要求的可以采用SSR渲染。
转自:csdn论坛
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
正如Redux一样,当你不知道是否需要Vuex那就是不需要。不要因为想用Vuex而使用它。
用过Vue的人都知道,Vuex是Vue的一个全局状态管理模块,它的作用是多个组件共享状态及数据,当某个组件将全局状态修改时,在绑定了该状态的另一个组件也将响应。实际上可以将Vue理解为一个function,在Vue的作用域中有一个数据代理,在每个Vue的实例中都能对其读和写
我们都知道Vue的数据驱动原理是用Object.defineProperty()进行数据代理,在setter中对数据绑定的view进行异步响应(vue3.0则是使用proxy)
通过查看Vuex源码可知Vuex的核心原理就是在Vue的beforeCreate钩子前混入(mixin)Vuex,并在init中将$store属性注册到Vue中
为了使案例更具体,我这还是简单使用脚手架搭了个项目(可参考另一篇文章),虽然只有两个组件,但是能清晰的理解其用法,我的src目录如下,除了最基础的App.vue和main.js外只有两个组件和一个store
先说明一下两个组件的作用,第一个组件是输入框,在里面输入字符,在二个组件div中显示,就是这么简单
首先我们使用常规方式(EventBus)实现一下,这里只需要在mainjs中创建一个vue实例,然后注册在vue中就可以通过事件emit和on来进行组件通信
main.js
import Vue
from 'vue'
import App
from './App'
Vue.prototype.$eventBus = new Vue()
new Vue({
el: '#app',
components: {App},
template: '<App/>'
})
<template>
<div>
{{
val
}}
</div>
</template>
<script>
export default {
name: "divComp",
data () {
return {
val: ''
}
},
mounted () {
this.$eventBus.$on('changeVal', (e) => {//监听输入事件通过eventBus传递信息
this.val = e
})
}
}
</script>
<style
scoped>
</style>
如果到这一步,你仍然感觉难度不大,那么恭喜你,Vuex的使用已经掌握了一大半了
下面,我们来说说actions,在说actions之前,我们先回顾一下mutations,mutations中注册了一些事件,在组件中通过emit对事件进行触发,达到处理异步且解耦的效果,然而官方并不推荐我们直接对store进行操作
官方对actions的说明是:Action 类似于 mutation,不同在于1.Action 提交的是 mutation,而不是直接变更状态。2.Action 可以包含任意异步操作。
也就是说,我们要把组件中的emit操作放到actions中,而在组件中通过某些方式来触发actions中的函数间接调用emit,此时,为了让action更直观,我们添加一个清除输入框字符的方法,当点击清除按钮时清除state.val
在输入框组件中将value绑定到state上
<template>
<input type="text" @input="inputHandler" :value="this.$store.state.val" />
</template>
<script>
export default {
name: "inputComp",
methods: {
inputHandler(e) {
this.$store.dispatch("actionVal", e.target.value);
},
},
};
</script>
<style
scoped>
</style>
在另一个显示数据的组件中新增删除按钮并绑定删除事件,通过dispatch告知store并通过emit操作state
<template>
<div>
<button @click="clickHandler">清除</button>
<span>{{ this.$store.state.val + this.$store.getters.getValueLength }}</span>
</div>
</template>
<script>
export default {
name: "divComp",
methods: {
clickHandler(){
this.$store.dispatch('actionClearVal')
}
},
};
</script>
<style
scoped>
</style>
最后在store中新建删除的actions和mutations
import Vue
from "vue";
import Vuex
from "vuex";
Vue.use(Vuex);
const state = {
val: ''
}
const mutations = {
changeVal(state, _val) {
state.val = _val
},
clearVal(state, _val) {
state.val = ''
}
}
const actions = {
actionVal(state, _val) {
state.commit('changeVal', _val)
},
actionClearVal(state) {
state.commit('clearVal')
}
}
const getters = {
getValueLength(state) {
return `长度:${state.val.length}`
}
}
export default new Vuex.Store({
state,
mutations,
actions,
getters
})
最终效果如下:
到这里为止,Vuex的基本用法就介绍完毕了。
然而除此之外,Vuex官方还提供了辅助函数(mapState,mapMutations,mapGetters,mapActions)和Modules(store的子模块,当有许多全局状态时,我们为了避免代码臃肿,就可以将各个store分割成模块)方便我们书写
下面我们用辅助函数重新实现一下上述功能
输入框:
<template>
<input type="text" @input="inputHandler" :value="value" />
</template>
<script>
import { mapState, mapMutations } from "vuex";
export default {
name: "inputComp",
computed: {
...mapState({ value: "val" }),
},
methods: {
...mapMutations({ sendParams: "changeVal" }), // sendParams用来传递参数,先把sendParams注册到mutations上,输入时触发sendParams
inputHandler(e) {
this.sendParams(e.target.value);
},
},
};
</script>
<style
scoped>
</style>
显示框:
<template>
<div>
<button @click="clickHandler">清除</button>
<span>{{ value + valueLength }}</span>
</div>
</template>
<script>
import { mapState, mapGetters, mapActions } from "vuex";
export default {
name: "divComp",
computed: {
...mapState({ value: "val" }),
...mapGetters({ valueLength: "getValueLength" }),
},
methods: {
...mapActions({ clickHandler: "actionClearVal" }),
},
};
</script>
<style
scoped>
</style>
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
文章目录
一.函数防抖
二、函数节流
1.时间戳实现
2.定时器实现
3.用节流优化防抖(定时器+时间戳)
三、总结
四、例子
一.函数防抖
当持续触发事件时,并不执行事件处理函数,一定时间段内没有再触发事件,事件处理函数才会执行一次;如果设定的时间到来之前,又一次触发了事件,就重新开始延时。
function debounce(fn, delay) {
// 定时器
let timer = null
// 将debounce处理结果当作函数返回
return function () {
// 保留调用时的this上下文
let context = this
// 保留调用时传入的参数
let args = arguments
// 每次事件被触发时,都去清除之前的旧定时器
if(timer) {
clearTimeout(timer)
}
// 设立新定时器
timer = setTimeout(function () {
fn.apply(context, args)
}, delay)
}
}
当持续触发事件时,保证一定时间段内只调用一次事件处理函数。
3.用节流优化防抖(定时器+时间戳)
防抖的问题在于如果用户的操作十分频繁——他每次都不等 设置的 delay 时间结束就进行下一次操作,于是每次都为该用户重新生成定时器,回调函数被延迟了不计其数次。 频繁的延迟会导致用户迟迟得不到响应,用户同样会产生“这个页面卡死了”的观感。
用节流来优化,保证在一定时间段内会调用一次事件处理函数。
function throttle(fn, delay) {
// last为上一次触发回调的时间, timer是定时器
let last = 0, timer = null
// 将throttle处理结果当作函数返回
return function () {
// 保留调用时的this上下文
let context = this
// 保留调用时传入的参数
let args = arguments
// 记录本次触发回调的时间
let now = +new Date()
// +是一元操作符,利用js隐式转换将其他类型变为数字类型
// 判断上次触发的时间和本次触发的时间差是否小于时间间隔的阈值
if (now - last < delay) {
// 如果时间间隔小于我们设定的时间间隔阈值,则为本次触发操作设立一个新的定时器
clearTimeout(timer)
timer = setTimeout(function () {
last = now
fn.apply(context, args)
}, delay)
} else {
// 如果时间间隔超出了我们设定的时间间隔阈值,那就不等了,无论如何要反馈给用户一次响应
last = now
fn.apply(context, args)
}
}
}
三、总结
函数防抖:将几次操作合并为一此操作进行。原理是维护一个计时器,规定在delay时间后触发函数,但是在delay时间内再次触发的话,就会取消之前的计时器而重新设置。这样一来,只有最后一次操作能被触发。
函数节流:使得一定时间内只触发一次函数。原理是通过判断是否到达一定时间来触发函数。
区别: 函数节流不管事件触发有多频繁,都会保证在规定时间内一定会执行一次真正的事件处理函数,而函数防抖只是在最后一次事件后才触发一次函数。
场景:比如在页面的无限加载场景下,我们需要用户在滚动页面时,每隔一段时间发一次 Ajax 请求,而不是在用户停下滚动页面操作时才去请求数据。这样的场景,就适合用节流技术来实现。
转自:csdn
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
异常包括的主要关键字有try{}catch(){}finally{} throw和throws五个关键字 。
下面我们来细说一下这五个关键字分别有什么用。
try catch关键字 这两个关键字是连用的
1.如果try块中的语句正常执行完毕,不会发生异常则catch块中的语句都将会被忽略。
2.如果try语句块在执行中遇到异常。并且这个异常与catch中声明的异常类型相匹配,那么在try块中其余剩下的代码都将被忽略。
3.如果try语句块在执行过程中遇到异常,而抛出的异常在catch块中没有被声明,那么程序立刻退出。
finally关键字这个关键字中的代码总能被执行(怎么我都要执行 )
1.只要try中所有语句正常执行完毕,那么finally块就会被执行。
2.如果try语句块在执行过程中碰到异常,无论这种异常能否被catch块捕获到,都将执行finally块中的代码。
注:try—catch—finally结构中try块是必需的catch和finally块为可选,但两者至少须出现其中之一。
如果catch中存在return,finally也会执行只不过执行的顺序有一定差异 ,先执行catch里的代码块,之后执行finally里的代码块,最后执行return语句。
throw关键字抛出异常
throws关键字声明捕捉异常
那么throw和throws有什么区别呢
1.作用不同:throw用于在程序中抛出异常;throws用于声明在该方法内抛出异常。
2.使用的位置不同:throw位于方法体内部,可以作为单独语句使用;throws必须跟在方法参数列表的后面,不能单独使用。
3.内容不同:throw抛出一个异常对象,而且只能有一个;throws后面跟异常类,而且可以跟多个异常类。
知道了这五个关键字的用法下面我们来说一下几个常用的异常代码:
1.ArithmeticException 试图除以0。
2.NullpointerException 当程序访问一个空对象的成员变量或方法,访问一个空数组的成员时发生。
3.ClassCastException 发生多态后,吐过强制转换的并不是父类的子类时发生。编译的时候可以通过,以为编译的时候并不会检查类型转换的问题。
4.ArraylndwxOutOfBoundsException 访问的元素下标超过数组长度
5.NumberFormatException 数字格式异常。
6.Exception 一般的异常都包括。
转自:csdn
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
ES6中的let和const和解构赋值
什么是ES6?
ES6, 全称 ECMAScript 6.0 ,是 JavaScript 的下一个版本标准,2015.06 发版。
为什么要使用ES6?
每一次标准的诞生都意味着语言的完善,功能的加强。js语言本身也有一些令人不满的地方
1.变量提升特性增加了程序运行的不可预测性 。
变量提升可以简单看以下代码了解下:
console.log(a);
var a=1;
//console.log(a)会输出undefined
这段代码也可以这样表示
var a;
console.log(a);
a=10;
//依旧输出undefined
这就是变量提升!
2.语法过于松散,实现相同的功能,不同的人可以会写出不同的代码,阅读性较低。
所以:ES6 ,目标是使JavaScript语言可以用来编写复杂的大型应用程序,成为企业级开发语言。我们没有理由不去学习ES6。
let关键字
ES6中新增的用于声明变量的关键字。主要是替代var。
特征:1.let声明的变量只在所处的块级有效,具有块级作用域! 在ES6之前JS只有全局作用域和局部作用域。
块级作用域:通俗来讲就是在一对大括号中产生的作用域,块级作用域中的变量只能在大括号中访问,在大括号外面是访问不到的。
可以看以下代码:
if(true){
let a=10;
console.log(a);//输出10
}
console.log(a);//报错提示a没有定义
{
let b=10;
console.log(b);//输出10
}
console.log(b);//报错提示b没有定义
if(true){
let c=20;
console.log(c)//输出20
if(true){
let d=30;
console.log(c)//输出 20
}
console.log(d);//报错d没有定义
}
在for循环中也起到作用,根据不同的需求选择let和var!
例如:
for(var i=0;i<10;i++){}
console.log(i) //输出10
for(let j=0;j<10;j++){}
console.log(j) //报错 j没有定义
好处:在业务逻辑比较复杂的时候,可以放在内层变量覆盖外层变量!
2.存在let 一开始就会形成封闭的作用域 使用let命名声明变量前 ,变量不可用,必须先声明后使用,不存在变量提升
例如:
if(true){
console.log(temp);//报错
let temp=1;
}`
3.let 不允许重复声明 在一个作用域内。
例如:
if(true){
let temp;
console.log(temp);//报错Identifier 'temp' has already been declared
let temp=1;
}
if(true){
var temp=10;
let temp=5;
console.log(temp);//报错 错误和上面一致
}
但是不在一个作用域内可以 例如:
{
let x=10;
console.log(x);//输出10
}
{
let x=5;
console.log(5);//输出5
}
const关键字
const一般用来声明常量,声明一个只读的常量。
特征:1.一旦声明其值不能改变必须立即初始化
例如:
const a; //这样什声明会直接报错!!!
1
这样声明没有初始化会直接报错!
2.对于对象:存的不是对象的本身, 而是对象的引用, 引用地址 ,地址不变, 对象可拓展!
例如:
const foo={y:10};
foo.x=100;
console.log(foo.x);//输出100
1
2
3
对象可以扩展
但是对象不能改变
例如:foo={n:1000}; 会报错!
作用域:
var v1=100;
function f1(){
console.log(v1,v2); //undefined no defined
var v1=110;
let v2=200;
function f2(){
let v3=300;
console.log(v1,v2,v3);//110 200 300
}
f2();
console.log(v1,v2,v3);// 110 200 no defined
}
f1();
console.log(v1,v2,v3);// 100 no defined no defined
可以向外面作用域找 不可以向里面作用域找 内层变量可能会覆盖外层变量
let和var的本质区别:浏览器的顶层对象为window Node的为global,var定义的变量会关联到顶层对象中,let和const不会!
例如:
var a =100;
console.log(window.a); // 100
let b=100;
console.log(window.b); //undefined
1
2
3
4
如何选择const和let:数据需要变化用let 数据不需要变化用const
解构赋值:ES6中允许从数组中提值,按照对应位置,对变量赋值,对象也可以实现解构!
例如:
{
let a,b,c;
[a,b]=[1,2];
console.log(a,b,c); //输出 1 2 undefined
}
{
let a,b,c;
[a,b,...c]=[1,2,3,4,5,6];
console.log(a);//输出1
console.log(b);//输出2
console.log(c);//输出[3,4,5,6]
}
{
let a,b,c;
[a,b,c=3]=[1,2];
console.log(a,b,c);//输出1 2 3
}
{
let a,b;
[a,b]=[1,2];
[a,b]=[b,a]
console.log(a,b);//输出 2 1
}
{
let a,b;
({a,b}={a:1,b:2})
console.log(a,b);//输出 1 2
}
{
function fun(){
return [1,2,3,4,5,6]
};
let a,b;
[a,,,,b]=fun();
console.log(a,b);//输出1 5
}
{
let o={p:42,q:true};
let {p,q}=o;
console.log(p,q);//输出 42 true
}
{
let {a=10,b=5}={a:3};
console.log(a,b);//输出 3 5
}
{
let metaData={
title:'abc',
test:[{
title:'test',
desc:'description'
}]
}
let {title:esTitle,test:[{title:cnTitle}]}=metaData;
console.log(esTitle,cnTitle);//输出abc test
}
解构赋值表达式右边的部分表示解构的源;解构表达式左边的部分表示解构的目标,如果左右两边对比成功就返回右边的值,如果没有对比成功就会undefined返回原来的值
除此之外还可以返回一些函数和方法
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
零基础如何快速入「]前端?这个问题往往是没有基础会遇到的,想要快速入「门前端开发,简单来说就是要把基础的知识点掌握熟练,然后由浅入深的去学习,在这里根据我过来的经验,为大家简单介绍一下零基础如何快速入门前端。
举个可能不太恰当的例子:前端就好比如盖房子,html就充当 了房子结构这部分,也是房子的基础。css呢, 就好比咱们房子的装修,墙面什么颜色,什么风格,什么地板等等,这些给房子改变风格,样式的就是css。而Java呢,就好比这个房子的功能,房子需要制冷吧,需要暖气吧,也需要上下水吧。这些功能性的就相当于是Java。
一、前端工具(dreamwear/sublime/Photoshop/SVN等)
二、零基础入门(HTML,CSS)
1、前端开发概况、代码入门
页面基本结构、文档声明、编码声明、css语法、style属性、link和style标签、id属性、基本样式、Border 、Background、 Font、盒模型、文本设置等等。
2、常用标签集合
header、article、aside、section、footer、nav、h1-h6、p、ul、ol、li、img、dl、dt、dd…绝对路径、相对路径、标签语义化、标签嵌套规范、SEO…
3、常用选择器&标签类型划分
d、class、类型选择、包含选择、群组选择、通配符、选择器优先级、标签样式初始化订制方案、超链接及伪类划分、标签类型划分及特性、inline、inline-block、block…
4、浮动进阶
浮动的作用、浮动的特性、文档流、浮动的各种问题、clear、BFC(块级格式化上下文)、触发BFC的条件、Haslayout、Haslayout的触发条件…
5、定位
relative相对定位、Absolute绝对定位、Absolute绝对定位、Fixed 固定定位、inherit 继承、static静态定位、默认值、zIndex层级问题、margin负值、透明度…
6、表格和表单
表格标签、表格样式重置、单元格合并、表单元素、表单相关的属性操作、表单默认样式初始…
7、兼容性问题处理
兼容性问题总结、浮动在IE6,7下的各种问题、表单在低版本IE的问题、处理低版本IE对新增标签的支持、CssHack、条件注释语句、PNG问题、透明度的问题、固定定位在IE低版本的处理方式…
8、整站进阶
样式规划、favicon、Css Sprite、Data URI、隐藏元素、测试工具使用、滑动门、等高布局、三列布局、未知宽高图片在容器内水平垂直居中、文本水平垂直居中、多行文本水平垂直居中…
9、css3入门
transition、属性选择器、nth-of-type、nth-child、backgroundSize、box-sizing、圆角,盒模型阴影、文字阴影、rgba、表单高级、H5表单新增属性、E:not(s)、E:target、E::selection、
10、移动端布局
测试环境Emulation、viewport、window.devicePixelRatio、物理分辨率、Media Queries、rem、window.screen、移动端布局相关问题、window.deviceorientationevent、横竖屏判断…
11、Animation和Transform
浏览器前缀、keyFrames、Animation调用、播放次数设置、动画偶数次调用顺序、Animation的问题、无缝滚动、动画播放|暂停、rotate旋转、deg、skew斜切、scale缩放、translate位移、transform-origin、transform的执行顺序问题…
12、Bootstrap前端开发框架
Html语法规范、CSS语法规范、Less 和 Sass 中的嵌套、class 命名、选择器、Normalize.css、栅格系统、排版、代码、响应式工具…
另外关于零基础如何快速入门前端的问题,项目实战这一点很重要,一定要学以致用,我的建议是,只有在实战项目中多加练习才能真正的掌握这门技术!
转自:csdn; 作者:hugo233
蓝蓝设计( www.lanlanwork.com )是一家专注而深入的界面设计公司,为期望卓越的国内外企业提供卓越的UI界面设计、BS界面设计 、 cs界面设计 、 ipad界面设计 、 包装设计 、 图标定制 、 用户体验 、交互设计、 网站建设 、平面设计服务
蓝蓝设计的小编 http://www.lanlanwork.com
{kind=link}